







 本文介绍了上海科技大学与阿里巴巴达摩院的合作研究,提出了一种在结构预测问题上的结构化知识蒸馏(Structural KD)方法,解决了在结构输出空间过大的情况下,直接优化目标函数的难题。该方法适用于多种结构预测模型,已在 ACL 2021 上发表。
本文介绍了上海科技大学与阿里巴巴达摩院的合作研究,提出了一种在结构预测问题上的结构化知识蒸馏(Structural KD)方法,解决了在结构输出空间过大的情况下,直接优化目标函数的难题。该方法适用于多种结构预测模型,已在 ACL 2021 上发表。

本文介绍了上海科技大学屠可伟课题组与阿里巴巴达摩院的一项合作研究,提出了在结构预测问题上一种较为通用的结构化知识蒸馏方法。该论文已被 ACL 2021 接受为长文。

论文标题:
Structural Knowledge Distillation: Tractably Distilling Information for Structured Predictor
论文地址:
http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21kd.pdf

简介
知识蒸馏(knowledge distillation,简称 KD)是模型压缩方法的一种,用于将知识从一个复杂的教师模型转移到一个简单的学生模型中。KD 的基本思想是希望学生模型的预测尽量接近教师模型的预测。自然语言处理和计算机视觉的很多任务要求结构化的输出,例如图片的像素级标签、句子的单词级标签序列等。
这时就需要使用结构知识蒸馏(structural KD)在模型之间转移这种结构化的信息。但结构输出空间一般是输出尺寸的指数大小,直接求解和优化 structural KD 的目标函数是不可行的。之前的工作一般是在特定情形中采用近似求解或将问题转换成非结构化知识蒸馏求解。
本文则根据很多常见结构预测模型会把输出结构的打分分解成多个子结构的打分之和,且子结构空间远小于结构输出空间的特性,提出了在一定条件下 structural KD 目标函数的多项式复杂度精确求解的方法。

背景知识
2.1 知识蒸馏
知识蒸馏框架通常包含一个或多个大型的已训练的教师模型和小型的学生模型,训练时知识蒸馏会鼓励学生模型的预测尽量接近教师模型的预测,一般来说就是将两者的交叉熵作为目标函数。
假设我们要训练一个多分类模型,类别集合为 。在样本 x 上教师模型的预测分布为 ,学生模型的预测分布为 ,则知识蒸馏要最大化两者的交叉熵:
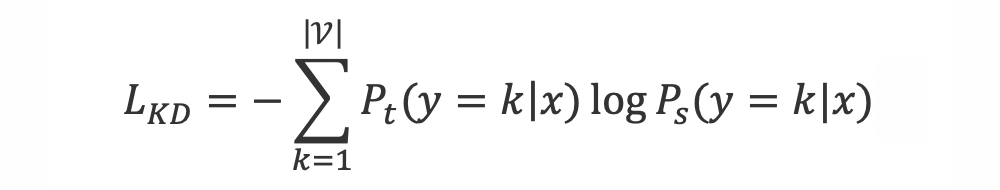
同时我们使用训练集上的样本 训练学生模型,目标函数为:
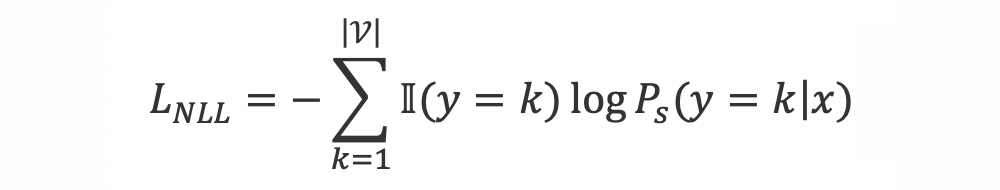
是指示函数。训练时最终的目标函数是两者的加权求和
2.2 词级别知识蒸馏
给定输入序列 ,输出序列 。如果将所有输出 都看作相互独立的,那么就可以在序列的每个位置分别做知识蒸馏,即词级别知识蒸馏(token-wise knowledge distillation),对每个位置的 求和得到整个序列的知识蒸馏目标函数:
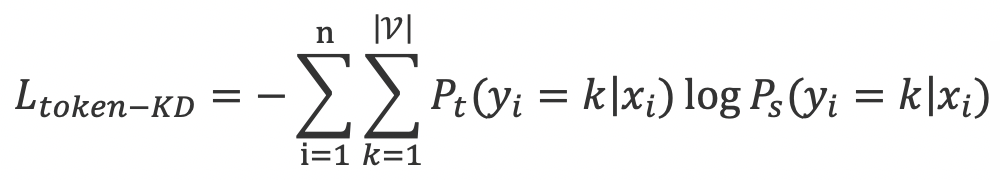
2.3 结构知识蒸馏
但实际上不同位置的输出往往并不是相互独立的,比如用 BIOES 标注 NER 标签的例子:“希尔顿离开北京机场了”,其标签为”B-PER, I-PER, E-PER, O, O, B-LOC, I-LOC, I-LOC, E-LOC, O“。I 标签前只能是 B 标签,不能是其他标签,类似的还有 E 标签前必须是 B 或者 I 标签等规则。
假设这个例子中只有 PER 和 LOC 两种 NER 标签,那么每个词的标注有 9 种,长度为 10 的输出序列理论上有 种组合,但实际上违反了 BIOES 标注规则的结构都不可能出现。因此常见的序列结构预测模型例如线性链 CRF 会建模不同位置输出之间的相关性。
同理,很多其他形式的结构预测模型(例如树或图的预测)也会建模输出结构不同部分之间的相关性。我们希望能在结构预测模型的知识蒸馏中,让学生模型学习到教师模型对完整结构的预测,亦即结构知识蒸馏(structrual knowledge distillation)。
令所有可能的结构输出序列构成结构输出空间 ,则结构知识蒸馏的目标函数为:
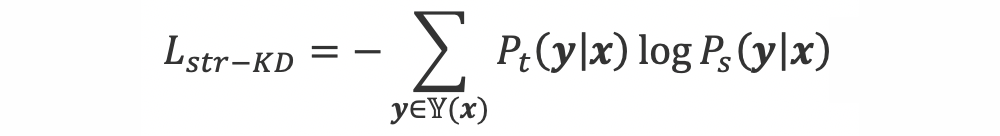
由于结构输出空间大小 往往是输出序列长度 n 的指数函数,因此直接按上式计算是不可行的。
我们去年在 ACL2020 发表的论文“Structure-Level Knowledge Distillation For Multilingual Sequence Labeling”提出了两种近似方法。
一种方法是只考虑
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









