








©PaperWeekly 原创 · 作者 | Maple小七
学校 | 北京邮电大学硕士生
研究方向 | 自然语言处理
作者提出了一个概念简单但足够有效的摘要生成框架:SimCLS,在当前的 SOTA 摘要生成模型(BART、Pegasus)基础上,SimCLS 在生成模型之后加上了一个无参考摘要的候选摘要打分模型,该打分模型的训练采用了对比学习的思想。SimCLS 可以缓解 Seq2Seq 框架固有的目标函数和评价指标不一致的问题,从而可以从模型生成的候选摘要中筛选出真实的评价指标(ROUGE)打分更高的摘要。

论文标题:
SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization
论文链接:
https://arxiv.org/abs/2106.01890
代码链接:
https://github.com/yixinL7/SimCLS

Introduction
当前的 Seq2Seq 模型通常在极大似然估计(MLE)的框架下以 teacher-forcing 的方式得到训练,众所周知,Seq2Seq 存在着目标函数与评价指标不一致的问题,因为目标函数计算的是局部的,token 级别的损失,而 ROUGE 这类评价指标会计算参考摘要和模型生成的摘要整体上的相似性。
另外,Seq2Seq 模型本身的训练和测试阶段也是不一致的,在测试阶段,模型需要以自回归的方式生成摘要,因此生成过程存在错误累加的问题,这个问题也被广泛地称为曝光偏差(exposure bias)问题。
前人针对 Seq2Seq 模型存在的这些问题提出了一些解决方法,目前主要有下面的几种策略:
Reinforcement Learning: 通过基于全局预测的奖励(rewards)直接优化评价指标,减轻训练和测试的不一致性。虽然强化学习可以直接优化不可导的评价指标,但这又引入了很多强化学习本身存在的问题,比如梯度估计的噪声会导致模型对超参敏感以及训练过程的不稳定性。
Minimum Risk Training: 虽然可以直接优化评估指标,但估计损失的精度依旧得不到保障。
Structured Prediction: 将先验的句子级损失与 MLE 损失结合起来,虽然可以缓解 MLE 训练的局限性,但评价指标和目标函数之间的关系依旧是不明确,不直观的。
在本文中,作者引入了一种基于对比学习的打分模型,该模型通过训练无参考摘要的打分模型来近似需要参考摘要的评价指标,直接学习评价指标本身的打分模式。值得注意的是,虽然已经有一些相关工作提出了可以为 MLE 损失引入对比损失增强模型表现,但作者选择将对比损失和 MLE 损失解耦,形成了一个两阶段结构的模型。

Contrastive Learning Framework for Abstractive Summarization
SimCLS 的思路很直观,首先,我们预训练一个基于 MLE 损失的 Seq2Seq 摘要生成模型,然后建立一个基于对比损失的打分模型为生成的候选摘要排序,通过分开优化生成模型和评价模型,我们能够以有监督的方式训练这两个模型,避免了复杂的强化学习方式。
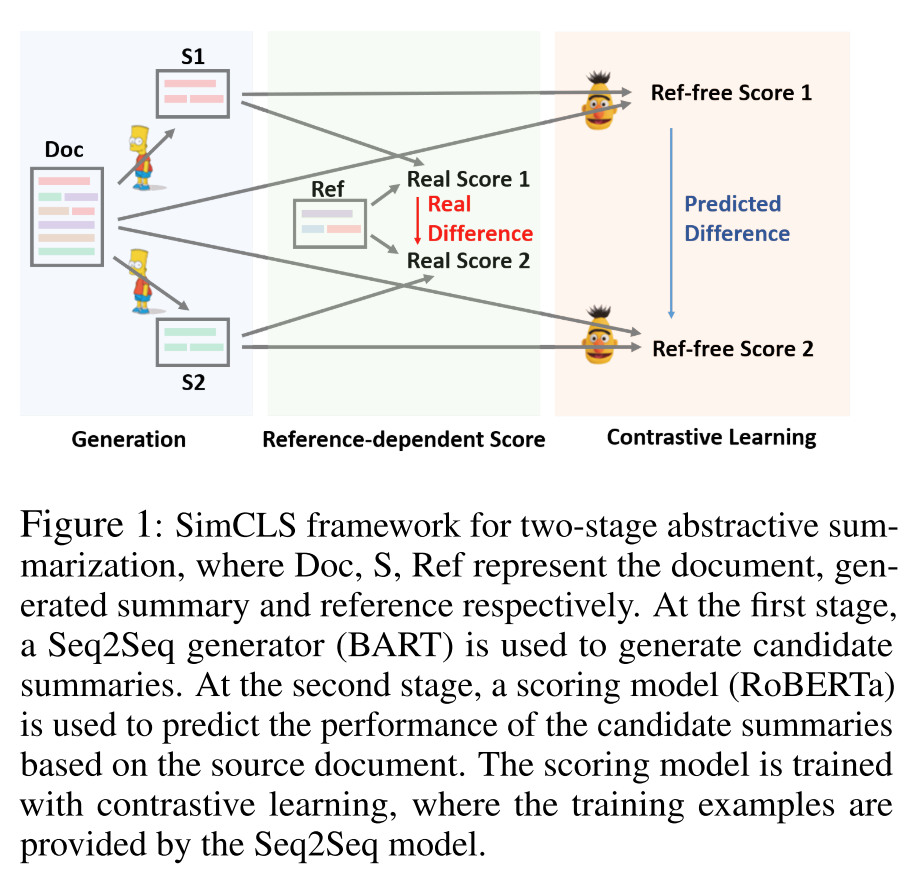
具体来说,给定原文档 和对应的参考摘要 ,生成式摘要模型 的目标是生成候选摘要 ,使得评价指标 给出的分数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 683
683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









