








©PaperWeekly 原创 · 作者 | 李婧蕾
学校 | 北京邮电大学硕士生
研究方向 | 自然语言处理

Abstract
无监督聚类的目的是根据在表示空间中的距离发现数据的语义类别。然而,在学习过程的开始阶段,不同类别在表征空间中经常存在重叠部分,这给基于距离的聚类实现不同类别之间的划分带来了巨大的挑战。为此,本文提出了(SCCL)——一个利用对比学习促进更好空间划分的新框架。

论文标题:
Supporting Clustering with Contrastive Learning
论文链接:
https://arxiv.org/abs/2103.12953
代码链接:
https://github.com/amazon-research/sccl
本文对 SCCL 在短文本聚类方面的性能进行了评估,结果表明,SCCL 显著提高了大多数基准数据集的前沿结果,在准确率方面提高了 3%-11%,在标准化互信息方面提高了 4%-15%。此外,当使用 ground truth 聚类标签进行评估时,本文的定量分析还证明了 SCCL 在利用自底向上的实例鉴别和自顶向下的聚类优势来实现更好的簇内和簇间距离方面的有效性。

近年来,许多研究致力于将聚类与深度表示学习结合起来。尽管有很好的改进,但聚类性能仍然不足,特别是在存在大量聚类的复杂数据的情况下。如 Figure1 所示,一个可能的原因是,即使使用深度神经网络,在聚类开始之前,不同类别的数据仍然有显著的重叠。因此,通过优化各种基于距离或相似度的聚类目标学习到的聚类纯度较低。
另一方面,实例对比学习(Instance-CL)最近在自我监督学习方面取得了显著的成功。Instance-CL 通常对通过数据扩充获得的辅助集进行优化。然后,顾名思义,采用对比损失将从原始数据集中的同一实例中增强的样本聚在一起,同时将来自不同实例的样本分开。本质上,Instance-CL 将不同的实例分散开来,同时隐式地将相似的实例在某种程度上聚集在一起(参见 Figure1)。通过将重叠的类别分散开来,可以利用这个有利的属性来支持聚类。然后进行聚类,从而更好地分离不同的簇,同时通过显式地将簇中的样本聚集在一起来收紧每个簇。
为此,本文提出了基于对比学习的支持聚类(SCCL),通过联合优化自顶向下的聚类损失和自底向上的实例对比损失。本文评估了 SCCL 在短文本聚类方面的表现,由于社交媒体如 Twitter 和 Instagram 的流行,短文本聚类变得越来越重要。它有利于许多现实世界的应用,包括主题发现,推荐和可视化。然而,由噪声和稀疏性引起的微弱信号给短文本聚类带来了很大的挑战。尽管利用浅层神经网络来丰富表征已经取得了一些改进,仍有很大的改进空间。
本文用 SCCL 模型解决了这个挑战。本文的主要贡献如下:
本文提出了一种新颖的端到端无监督聚类框架,大大提高了各种短文本聚类数据集的最新结果。此外,本文的模型比现有的基于深度神经网络的短文本聚类方法要简单得多,因为那些方法通常需要多阶段的独立训练。
本文提供了深入的分析,并演示了 SCCL 如何有效地结合自上而下的聚类和自下而上的实例对比学习,以实现更好的类间距离和类内距离。
本文探讨了用于 SCCL 的各种文本增强技术,结果表明,与图像域不同,在文本域使用复合增强并不总是有益的。

Model
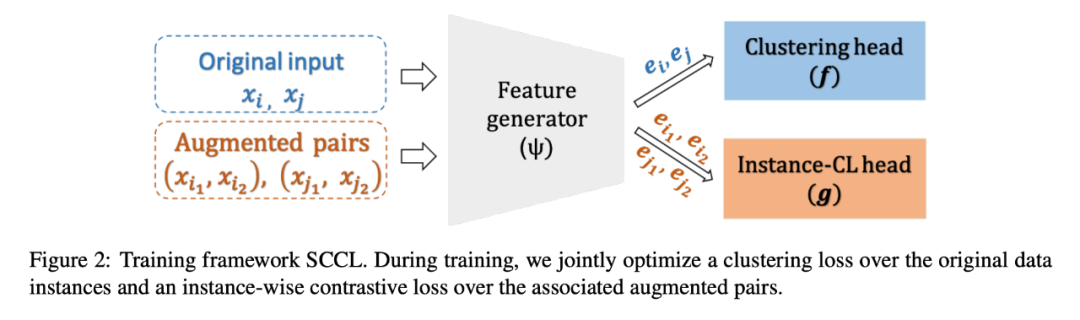
本文的目标是开发
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2396
2396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









