








©PaperWeekly 原创 · 作者 | 王增志
单位 | 南京理工大学硕士生
研究方向 | 情感分析与观点挖掘

引言
2020 年自然语言处理方向出现了很多令人印象深刻的工作, 其中就包括了这一系列 Seq2Seq 大规模预训练语言模型,比如 BART [1],T5 [2] 和 GPT-3 [3],直觉上这些生成模型一般会用于摘要和翻译这种典型的生成任务,2021年的很多工作开始尝试利用这些强大的生成模型来建模一些复杂的自然语言理解任务,比如命名实体识别,属性级情感分析和事件抽取任务等等。本文将会按照时间线简要对基于生成式方法的事件抽取相关的工作进行梳理。
事件抽取(Event Extraction, EE)是指从自然语言文本中抽取事件并识别事件类型和事件元素的技术。其任务目标是根据触发词识别句子中所有目标事件类型的事件,并根据论元角色集合抽取事件所对应的论元,这里的事件类型和论元都是预定义好的。举个例子,给定一个句子,事件抽取旨在识别出句子中包含的结构化事件。
Input: The man returned to Los Angeles from Mexico following his capture Tuesday by bounty hunters.
Output:
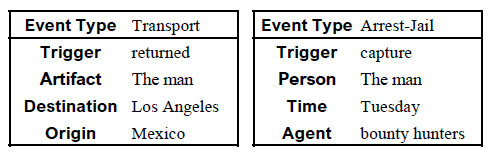
该任务分为如下几个子任务:
Trigger Identification:检测(抽取)句子中的事件的触发词,可以是一个词也可以是一个span;
Trigger Classification:判断抽取到的触发词对应的事件类型;
Argument Identification:检测(抽取)句子中的论元比如某种事件发生的时间,地点等;
Argument Classification:判断抽取到的论元对应的论元角色;

TANL
这是一篇来自 AWS 团队 ICLR 2021 的工作 [4],作者致力于研究结构预测任务(比如命名实体识别,实体关系抽取,语义角色标注,共指消解,事件抽取,对话状态追踪等)的多任务学习,之前的大多数方法都是针对具体的特定的任务进行建模,训练一个任务特定的判别器,但是这样的方法一方面结构不能被适配到其他类似的任务上,给迁移学习带来了困难,另一方面这种判别式的结构很难利用标签的语义知识。
基于此,作者提出了 TANL 模型(Translation between Augmented Natural Language),即给定输入,输出原有文本和对应的文本标注。如下图所示,输入文本,输出的文本在原文本的上做了 augmented,即加上了标注,图中的实体关系联合抽取任务,会在头实体上加上对应的实体类别,在尾实体上除了加上实体类型,还会加上关系,以及对应的头实体 span;语义角色标注任务,模型会标注出主语,谓语,时间地点等;共指消解任务,模型会标注出所有的第一个 mention,然后在后续出现的 mention 上标注对应的本体,最后对输出的文本进行解析,得到预测的结构。
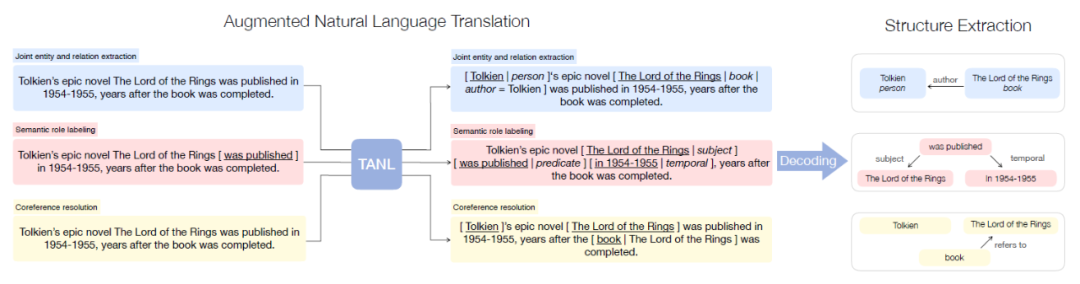
下图是模型对事件抽取任务的建模示例,首先进行触发词的抽取,输出的句子会在触发词后面加上对应的事件类型,然后针对事件论元的抽取,输入会标注出触发词和对应的事件类型,然后输出时会在相关的 span 标注实体的类型,比如个人,时间等,还会标注出论元的类型,用“=”来对应触发词。

作者在 single-model-single-dataset,multi-dataset 和 multi-task 三种 setting 上进行了实验,实验结果显示模型在实体关系联合抽取,关系分类和语义角色标注达到了新的 SOTA,在其他的任务上取得了跟 SOTA 相比还可以的ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









