








©PaperWeekly 原创 · 作者 | 陈思硕
单位 | 北京大学
研究方向 | 自然语言处理
预训练-微调已经成为自然语言理解领域的标准范式,而微调后的预训练模型对不同类型的分布外(OOD)样本的检测能力尚缺乏全面的探究分析。来自北京大学的研究者深入分析了现有方法对语义迁移(Semantic Shift,简称 SS)类型的分布外样本与非语义迁移(Non-Semantic Shift,简称 NSS,又名背景迁移)类型的分布外样本的检测表现,发现在模型微调前后存在有趣的 trade-off:
在预训练特征上构建的检测器在 NSS 类型的 OOD 数据上表现最好,而模型微调后,检测器在 NSS 类型的 OOD 数据上的表现显著下降,在 SS 类型的 OOD 数据上的表现显著上升并达到现有方法中的最优。
也就是说,没有单一方法在两种类型的分布外样本上都能取得最佳的检测表现,根据作者的分析,微调破坏了与类别标签无关的通用特征,从而导致 NSS 类型 OOD 样本的检测性能下降。
基于以上实验观察与分析,作者提出一种简单有效的通用分布外检测指标 GNOME,它集成了从预训练特征与微调后模型特征计算出的距离分数,在 NSS 与 SS 两类 OOD 数据上都能取得接近 SOTA 的性能(因此在平均意义上最佳),并且在 OOD 数据兼具两类分布迁移的基准数据集上取得了最佳表现。日前,该论文被 EACL 2023 (Findings) 录用。

论文标题:
Fine-Tuning Deteriorates General Textual Out-of-Distribution Detection by Distorting Task-Agnostic Features
论文链接:
https://arxiv.org/pdf/2301.12715.pdf
收录会议:
EACL 2023 (Findings)

背景与动机
1.1 研究背景:NLP模型的OOD检测
自 BERT、GPT 等预训练模型发布以来,预训练-微调已经成为自然语言理解任务的通用范式,但微调后的模型在面对与训练集分布不同的分布外数据(OOD data)时,容易给出过高的置信度 ,威胁到开放世界中模型的安全性。
因此,基于预训练模型的文本分布外检测(textual ODD detection)近期颇受关注。该问题的本质是一个可以建模为二分类的异常检测问题,模型除了给出分布内(ID)的类别标签预测外,还需要对测试样本 给出置信度分数 以进行 OOD detecton 的决策:
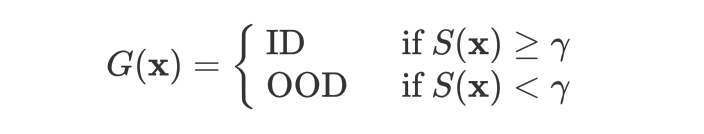
其中 越高,表示检测器 越倾向于认为 是分布内(in-distribution,ID)样本; 则为用户选定的阈值。
1.2 研究动机:OOD文本缺乏统一定义,导致现存方法的评测并不全面
对给定的 OOD 检测算法,研究者一般在分布内的训练集上训练分类模型和检测器,之后在分布内的测试集和 OOD 测试集上使用给定的检测器分别得到置信度分数,衡量两个分布的差异以评价 OOD 检测器的性能(理想的检测器对所有分布内样本给出的置信度分布 都应该比任何 OOD 样本的置信度高)。
一般使用 AUROC(即 ID/OOD 二分类的 AUC,越高越好)与 FAR95(95% 的 ID 样本被召回时,被误认为 ID 的 OOD 样本的比例,越低越好)衡量。
然而,自然语言处理领域的研究者对 OOD 文本的定义缺乏共识,现有 OOD 检测方法的性能的性能未得到全面的评价。具体来说,模型部署环境中面对的分布迁移可分为两类:
1. 语义迁移(Semantic Shift,简称 SS):分布外数据与分布内数据共享相似的背景信息(如长度分布、语言风格等),但属于新的语义类别,如对话意图识别中研究者关注的 unknown intents [2][3] 属于主要由语义迁移(SS)形成的 OOD 数据;
2. 非语义迁移(Non-Semantic Shift,简称 NSS,又名背景迁移):分布外数据和分布内数据共享相同的语义标签,但在背景信息上不同,如有害信息识别(toxicity detection,有害/无害的二分类任务)中,推特数据作为分布内数据集时,Wikipedia 中的评论属于主要由非语义迁移(NSS)造成的 OOD 数据(它们共享有害、无害这两个语义标签)。
值得一提的是,即使在分布内数据上训练的模型也可以在由 NSS 形成的分布外样本上做出预测,但其性能往往会有显著的下降(如何提升在这类数据上的泛化性能则是 OOD generalization 领域的研究目标)。鉴于在医疗、自动驾驶等高风险领域错误预测的代价高昂,将这类分布外样本拒绝是合理的选择(模型进行保守的低置信度预测,将控制权交给人类),相当一部分 NLP 领域的 OOD detection 研究工作在这类分布外数据集上进行测试 [4][5][6]。
此外,在现实中的 OOD 数据常有兼具 SS/NSS 两种迁移的情况,NLP 研究者通常使用与分布内数据集来自不同任务的数据集来模拟这种情况进行测试 [7][8][9](在本文中称为 the cross-task setting),如 SST-2 影评情感分类数据作为分布外数据集,而 20Newsgroups 新闻分类数据集作为 OOD 数据。
由于对 OOD 文本缺乏统一的定义,现有的工作往往只将本身提出的新检测方法与基线在某种设定下进行评测、得出结论,对检测器在现实中各类分布迁移下的表现缺乏全面的评测。Arora et al., EMNLP 2021 [5] 初步指出了这个问题,并对部分简单的基线在 SS 和 NSS 的设定下做了初步测评,但对现存主流方法在各种设定下表现的全面评测尚属空白。
因此ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5376
5376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









