








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 月之暗面
研究方向 | NLP、神经网络
众所周知,分类任务的标准损失是交叉熵(Cross Entropy,等价于最大似然 MLE,即 Maximum Likelihood Estimation),它有着简单高效的特点,但在某些场景下也暴露出一些问题,如偏离评价指标、过度自信等,相应的改进工作也有很多,此前我们也介绍过一些,比如《再谈类别不平衡问题:调节权重与魔改Loss的对比联系》、《如何训练你的准确率?》、《缓解交叉熵过度自信的一个简明方案》[1] 等。
由于 LLM 的训练也可以理解为逐 token 的分类任务,默认损失也是交叉熵,因此这些改进工作在 LLM 流行的今天依然有一定的价值。
在这篇文章中,我们介绍一篇名为 EMO 的工作,它基于最优传输思想提出了新的改进损失函数,声称能大幅提高 LLM 的微调效果。其中细节如何?让我们一探究竟。

论文标题:
EMO: Earth Mover Distance Optimization for Auto-Regressive Language Modeling
论文地址:
https://arxiv.org/abs/2310.04691

概率散度
假设 是模型预测的第 个类别的概率,, 则是目标类别,那么交叉熵损失为
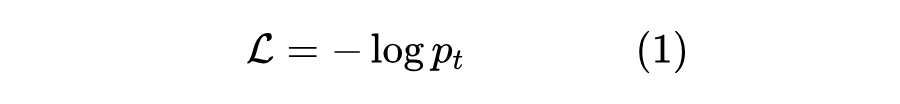
如果将标签 用one hot形式的分布 表示出来(即 ),那么它可以重写成
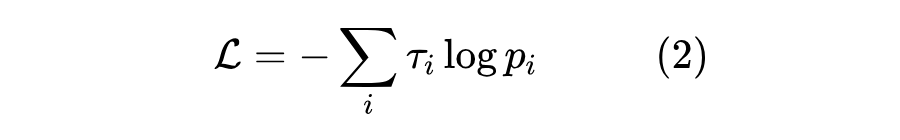
这个形式同时适用于非 one hot 的标签 (即软标签),它等价于优化 的 KL 散度:
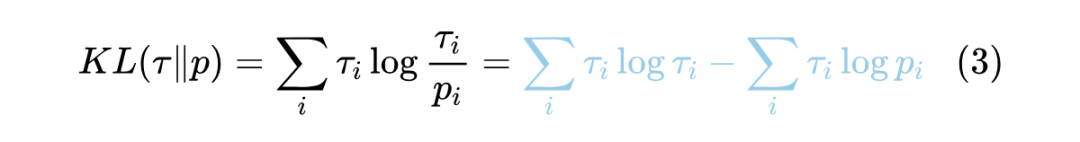
当 给定时,最右端第一项就是一个常数,所以它跟交叉熵目标是等价的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 469
469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









