








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 月之暗面
研究方向 | NLP、神经网络
回过头来看,才发现从第 7 篇《Transformer升级之路:长度外推性与局部注意力》开始,“Transformer 升级之路”这个系列就跟长度外推“杠”上了,接连 9 篇文章(不算本文)都是围绕长度外推展开的。
如今,距离第 7 篇文章刚好是一年多一点,在这一年间,开源社区关于长度外推的研究有了显著进展,笔者也逐渐有了一些自己的理解,比如其实这个问题远不像一开始想象那么简单,以往很多基于局部注意力的工作也不总是有效,这暗示着很多旧的分析工作并没触及问题的核心。
在这篇文章中,笔者尝试结合自己的发现和认识,去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。

问题定义
顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即 “Train Short, Test Long”。
那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列 Loss 或者 PPL 不会爆炸,更加符合实践的评测则是输入足够长的 Context,让模型去预测答案,然后跟真实答案做对比,算 BLEU、ROUGE 等,LongBench [1] 就是就属于这类榜单。
但要注意的是,长度外推应当不以牺牲远程依赖为代价——否则考虑长度外推就没有意义了,倒不如直接截断文本——这意味着通过显式地截断远程依赖的方案都需要谨慎选择,比如 ALIBI 以及《Transformer升级之路:长度外推性与局部注意力》所列举的大部分方案,还有带显式 Decay 的线性 RNN,这些方案当序列长度足够大时都表现为局部注意力,即便有可能实现长度外推,也会有远程依赖不足的风险,需要根据自己的场景斟酌使用。
如何判断在长度外推的同时有没有损失远程依赖呢?比较严谨的是像《Transformer升级之路:无限外推的ReRoPE?》最后提出的评测方案,准备足够长的文本,但每个模型只算每个样本最后一段的指标,如下图所示:
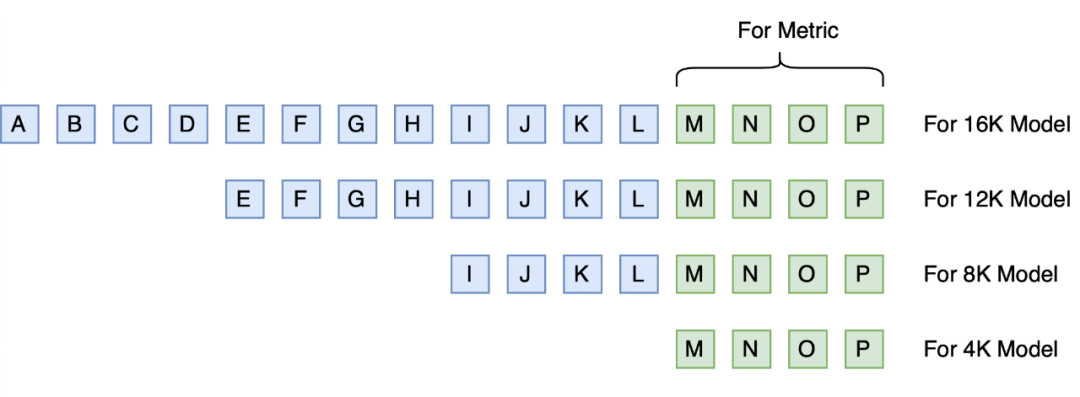
▲ 一种关注远程依赖的评测方式
比如,模型训练长度是 4K,想要看外推到 16K 的效果,那么我们准备一个 16K tokens 的测试集,4K 的模型输入每个样本最后 4K tokens 算指标,8K 模型输入每个样本最后 8K tokens 但只算最后 4K tokens 算指标,12K 模型输入每个样本最后 12K tokens 但只算最后 4K tokens 算指标;依此类推。
这样一来,不同长度的模型算的都是同一段 tokens 的指标,不同的只是输入的 Context 不一样,如果远程依赖得以有效保留,那么应该能做到 Context 越长,指标越好。

旋转位置
谈完评测,我们回到方法上。文章开头我们提到“旧的分析工作”,这里“新”、“旧”的一个主要特点是“旧”工作多数试图自行设置新的架构或者位置编码来实现长度外推,而最近一年来的“新”工作主要是研究带旋转位置编码(RoPE)的、Decoder-Only 的 Transformer 模型的长度外推。
先说个题外话,为什么如今大部分 LLM 的位置编码都选择了 RoPE 呢?笔者认为主要有几点原因:
1. RoPE 不带有显式的远程衰减,这对于旨在 Long Context 的模型至关重要;
2. RoPE 是一种真正的位置编码,通过不同频率的三角函数有效区分了长程和短程,达到了类似层次位置编码的效果,这也是 Long Context 中比较关键的一环;
3. RoPE 直接作用于 Q、K,不改变 Attention 的形式,与 Flash Attention 更契合,更容易 Scale Up。
相比之下,诸如 ALIBI、KERPLE 等,虽然有时也称为位置编码,但它们实际上只是一种 Attention Bias,没有太多位置信息,且不适用于 Encoder,能用于 Decoder 大体上是因为 Decoder 本身的下三角 Mask 就已经有较为充分的位置 Bias 了,额外的 Attention Bias 只是锦上添花。
此外它们无法在单个头内有效区分长程和短程,而是要通过在不同头设置不同的 Decay 因子来实现,这也意味着它们用于单头注意力(比如 GAU)的效果会欠佳。
说这么多优缺点的对比,看起来像是“王婆卖瓜,自卖自夸”,其实不然,这只是为了跟大家交换一下观点,因为之前也有读者提出过相同的问题。
作为 RoPE 的提出者,笔者对 RoPE 的理解不见得一定比大家深刻,毕竟当时提出 RoPE 的初衷纯粹是好玩,当时的想法是有效就很不错了,能媲美 Learnable 的绝对位置编码就是非常好的消息了。所以,既然是“意料之外”,那么“作者本人也没多透彻的认识”这件事,也是“情理之中”了。

窗口截断
好像又把话题扯偏了。简单来说,其实上两节的内容主要是想表达的观点是:目前看来,RoPE 对于 Long Context 来说是足够的,所以研究 RoPE 的长度外推是有价值的,以及我们在选择长度外推方案时,不应牺牲远程依赖的能力。
在本站最早讨论长度外推的《Transformer升级之路:长度外推性与局部注意力》一文中,我们判断长度外推是一个预测阶段的 OOD(Out Of Distribution)的问题,尽管用今天的视角看,这篇文章的一些评述已经显得有点过时,但这个根本判断是依然还算正确,放到 RoPE 中,就是推理阶段出现了没见过的相对距离。
为此,一个看上去可行的方案是引入 Sliding Window的Attention Mask,如下图左所示:
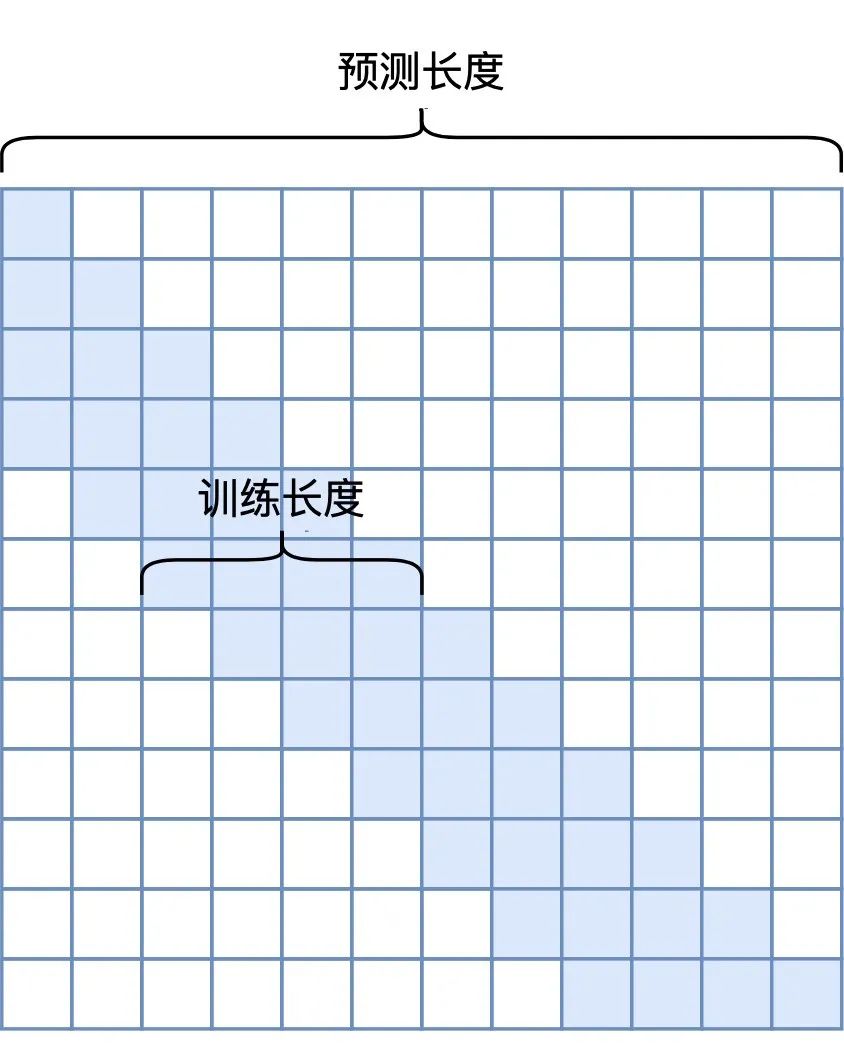
▲ Sliding Window Mask
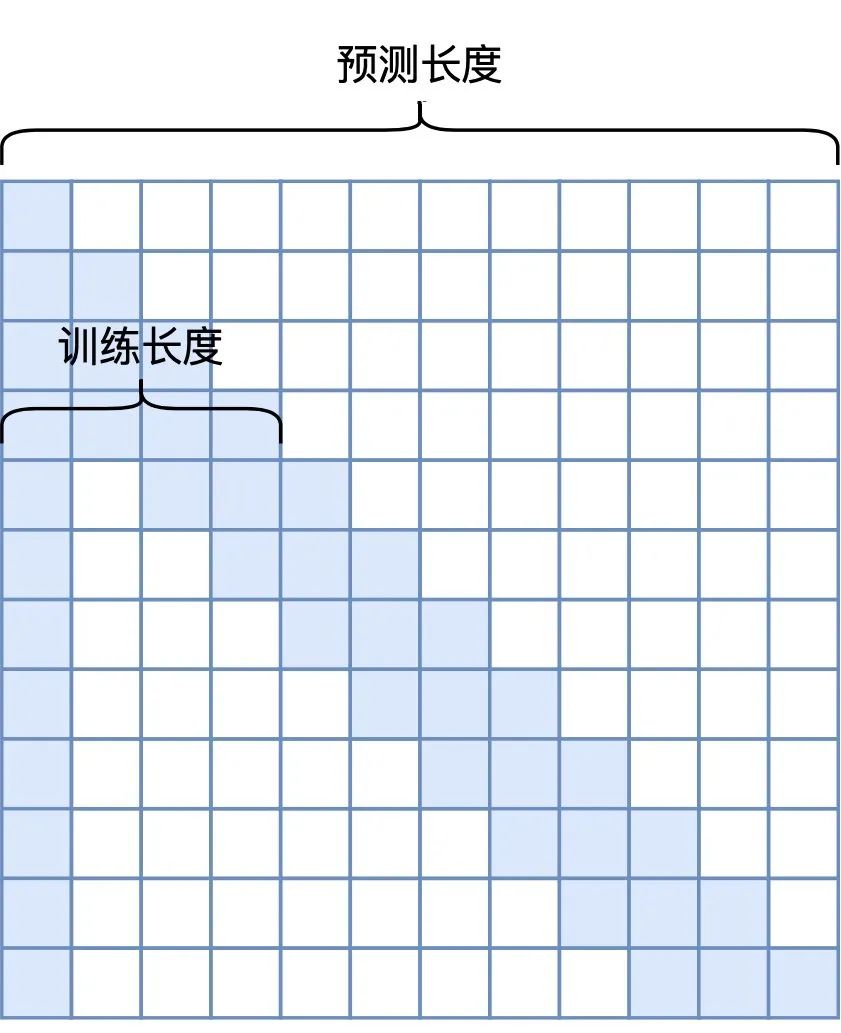
▲ -shape Window Mask
当然,由于强行截断了窗口外的注意力,所以这个方案并不满足“不牺牲远程依赖的能力”的原则,但我们可以只将它作为一个 Baseline 看待。很遗憾的是,即便做出了如此牺牲,这个方案却是不 Work 的——连最基本的 PPL 不爆炸都做不到!
对这个现象的深入分析,先后诞生《LM-Infinite: Simple On-the-Fly Length Generaliz
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









