








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 月之暗面
研究方向 | NLP、神经网络
我们知道,Scaled-Dot Product Attention 的 Scale 因子是,其中 是 的维度。这个 Scale 因子的一般解释是:如果不除以 ,那么初始的 Attention 就会很接近 one hot 分布,这会造成梯度消失,导致模型训练不起来。然而,可以证明的是,当 Scale 等于 0 时同样也会有梯度消失问题,这也就是说 Scale 太大太小都不行。
那么多大的 Scale 才适合呢? 是最佳的 Scale 了吗?本文试图从梯度角度来回答这个问题。

已有结果
在《浅谈Transformer的初始化、参数化与标准化》[1] 中,我们已经推导过标准的 Scale 因子 ,推导的思路很简单,假设初始阶段 都采样自“均值为 0、方差为 1”的分布,那么可以算得
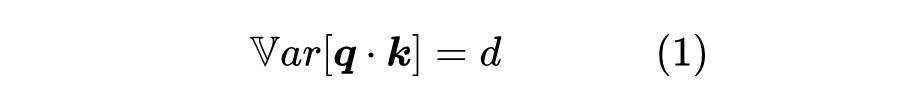
于是我们将 除以 ,将 Attention Score 的方差变为 1。也就是说,之前的推导纯粹是基于“均值为 0、方差为 1” 就会更好的信仰来得到的结果,但没有解释让 Attention Score 的方差为 1,也没有评估 是否真的就解决了梯度消失问题。
当然,从已有的实验来看, 至少一定程度上是缓解了这个问题,但这毕竟是实验结果,我们还是希望能从理论上知道“一定程度”究竟是多少。

计算梯度
既然涉及到了梯度,那么最好的办法就是把梯度算出来,然后定一个优化目标。设 ,, 是归一化因子,那么可以直接算得:
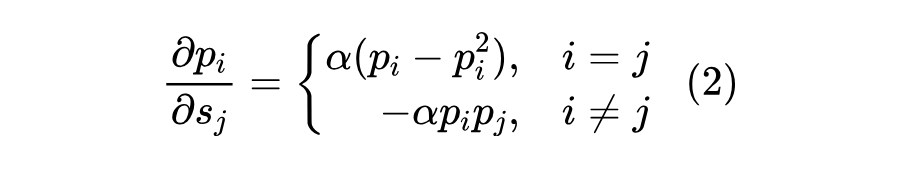
或者可以简写成 。很明显,当 时梯度为 0;当 时, 之中只有一个 1、其余都是 0(假设 中只有唯一的最大值),梯度也是 0。
为了更有利
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1206
1206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









