







©PaperWeekly 原创 · 作者 | 郎皓
单位 | 阿里巴巴

论文标题:
Fine-Tuning Language Models with Reward Learning on Policy
论文作者:
郎皓、黄非、李永彬
收录会议:
NAACL 2024
论文链接:
https://arxiv.org/abs/2403.19279
代码和数据:
https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/rlp

引言
目前,大语言模型(LLMs)在遵循开放域用户指令方面表现出强大能力 [1]。这项能力主要归功于利用人类偏好数据微调预训练大语言模型(Reinforcement Learning from Human Feedback,RLHF)[2]。
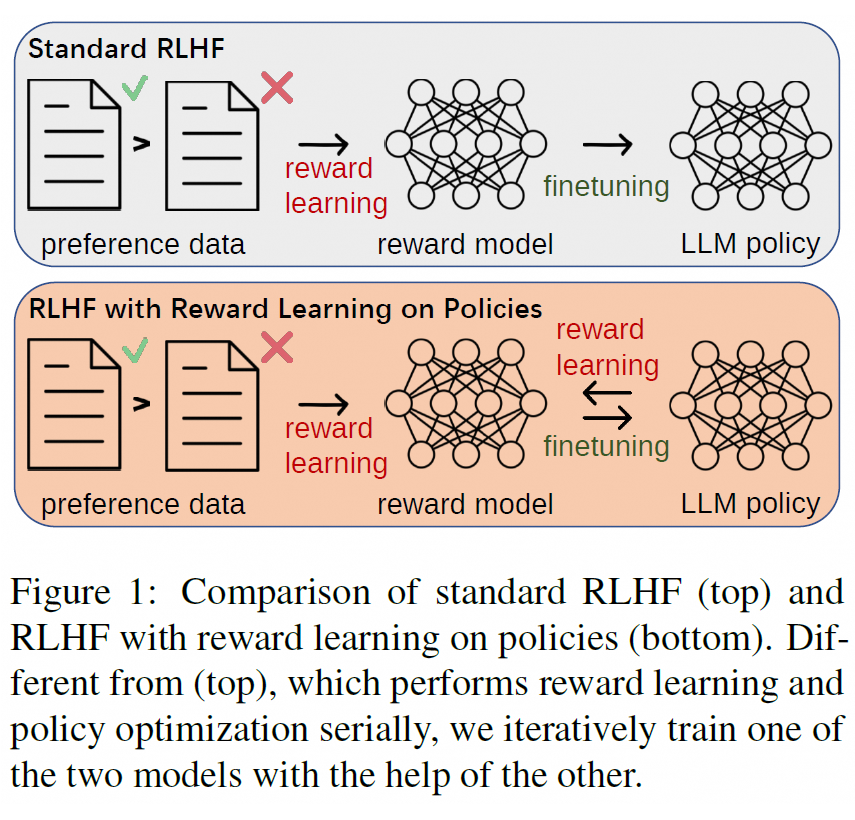
一个典型的 RLHF 过程包括三个相关步骤 [3]:人类偏好数据搜集、奖励模型学习(reward learning)和策略优化(policy optimization),如下图(top)所示。
上述 RLHF 的三个步骤通常先后串行执行。因为策略优化在微调大语言模型过程中改变了其数据分布,导致基于离线数据训练的(fixed)奖励模型存在不准确地分布偏离问题(inaccurate off-distribution)。
因此,奖励模型准确率会快速下降并相应地损害策略模型的性能。该问题可以通过持续从最新策略模型采样并标注人类偏好数据解决,但是这样会显著增加系统的复杂度使其难以优化。与此同时,在该设定中长期维护数据质量将消耗大量资源。
在这篇论文中,我们展现在不需要持续标注新的偏好数据前提下,如何基于策略模型优化奖励模型并使之分布准确(on-distribution)。我们提出 Reward Learning on Policy(RLP)框架:以无监督的方式,利用策略模型的采样数据优化奖励模型。
RLP 先基于典型的 RLHF 方法从头训练一个奖励模型和一个策略模型,然后考虑已训练策略模型的数据分布重新训练奖励模型,最后基于重新训练的奖励模型重新训练策略模型,如下图(bottom)所示。
具体地,RLP 提出两种方法利用策略模型的采样数据重新训练奖励模型:无监督多视角学习(Unsupervised Multi-View Learning,UML)和伪偏好数据生成(Synthetic Preference Generation,SPG)。
RLP-UML 通过策略模型生成两个结果的方式构建一个输入的两个视角,然后在奖励模型拟合人类偏好数据的同时优化一个多视角信息瓶颈损失函数(multi-view information bottleneck loss)。
此外,RLP-SPG 利用策略模型的采样数据模拟偏好数据。与经典的 RLAIF 方式(基于 LLMs 生成一个输入的两个结果并打分)不同,RLP-SPG 生成一个输入的多个结果并构成一个集合。这样 RLP-SPG 可以通过度量结果集合最大簇的大小,推断模型生成结果的不确定性并决定何时相信模型的预测结果。
该采样策略与自一致性(self-consistency)假设相符,即从结果集合最大簇挑选被选择结果(preferred output),从剩余的其它簇随机挑选未被选择结果(non-preferred output)。
我们的实验表明在三个标准的测试集,RLP 效果优于其它基于人类反馈的方法,包括基于 PPO 的 RLHF 方法。

RLP的实现

我们提出一个新的 RLHF 框架,共包括以下 5 个步骤:
Step 0,监督微调:
基于指令遵循示例数据 ,有监督微调预训练语言模型,得到 SFT 模型 。
Step 1,人类偏好数据搜集:
首先,SFT 模型对输入指令 生成两个结果 。然后,展示给标注人员并让其表达偏好 ,其中 为被选择结果、 为未被选择结果。
Step 2,奖励模型学习:
基于损失函数 训练奖励模型 ,其中 为偏好数据集, 为 sigmoid 函数。
Step 3,策略优化:
基于奖励模型 微调语言模型,最大化 得到策略模型 ,其中 为未标注的指令集合, 通常为 SFT 模型。该优化目标通常基于 PPO 算法进行优化。
Step 4,奖励模型再学习:
我们首先构建策略模型的采样集合 ,其中 是策略模型 生成的 个结果集合。
然后,我们基于 和 重新训练奖励模型。具体地,我们提出两种方法:无监督多视角学习(Unsupervised Multi-View Learning,UML)和伪偏好数据生成(Synthetic Preference Generation,SPG)。
无监督多视角学习
对于 ,我们首先构建多视角:。我们基于高斯分布参数化视角的表示 。
然后,我们基于多视角信息瓶颈损失函数(multi-view information bottleneck loss)做无监督表示学习:,其中 表示两个随机变量的互信息, 表示对称 KL 距离。
伪偏好数据生成
对于 ,我们假设结果集合 中最频繁的样本为正确结果,并且其频次为置信度。具体地,我们先把 中样本聚类成簇 , 的置信度可表示为 ,其中 为 中最大的簇。
这样我们可以有选择的生成偏好数据 ,其中 从最大的簇 采样出, 从其它的簇采样。
再学习的奖励模型 的损失函数为:。为简化计算复杂度,我们实现两个变体:1)RLP_UML 去除伪偏好集合 ;2)RLP_SPG 设置 。
Step 5,策略模型再学习:
我们基于重新训练的奖励模型 二次训练策略模型 ,最大化 。

实验
3.1 主实验
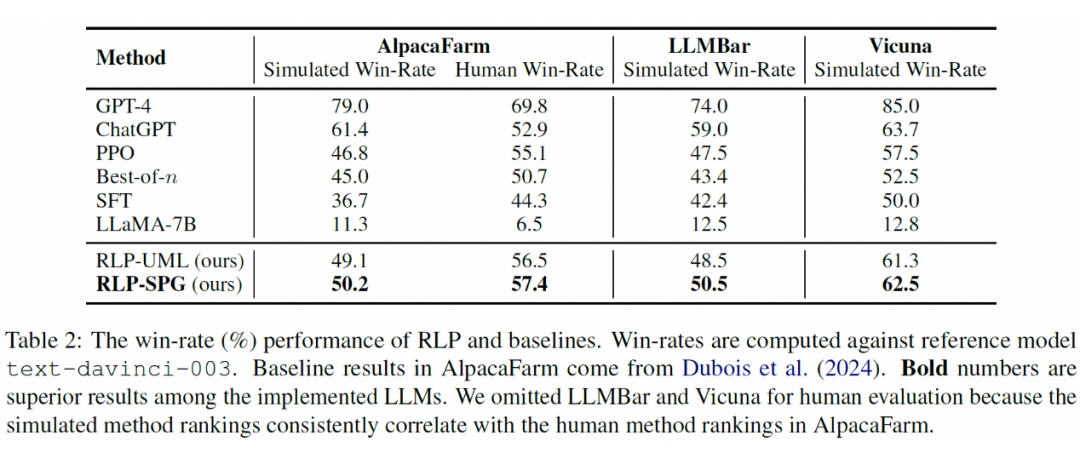
我们在 AlpacaFarm、LLMBar、Vicuna 三个标准测试集实验。评测指标基于广泛采样的 Win-Rate,其中 Simulated Win-Rate 利用 API LLMs 打分,Human Win-Rate 基于人工打分。
如下表所示,GPT-4 取得最好的结果。在我们实现的 LLMs 中,RLP-SPG 在三个测试集的两个指标均取得最好结果,超过 PPO 基准方法。
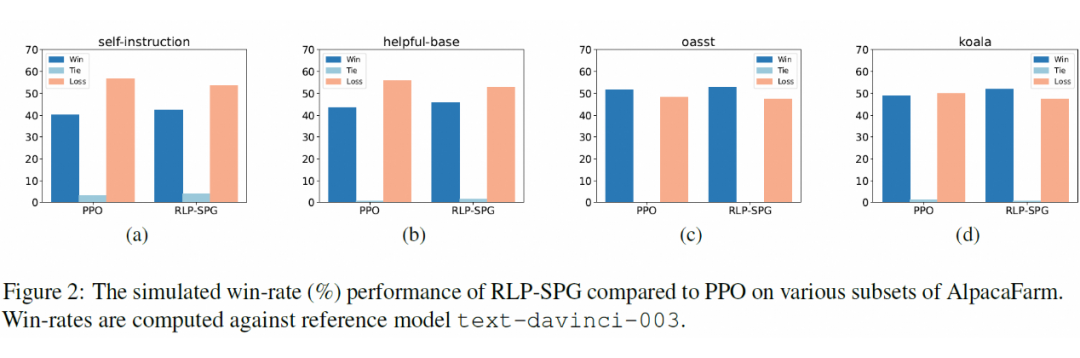
为进一步验证 RLP 相对其它基准方法的优势,下图展示了 RLP-SPG 在 AlpacaFarm 各个数据子集中相对 PPO 的表现。我们可以观察到 RLP-SPG 稳定的表现优于 PPO。
RLP 相对基准方法的优势也可以被定性的观察出来。下表展示的例子表明:相对于基准方法,RLP 生成的结果更加详尽。

3.2 消融实验
3.2.1 信息瓶颈损失函数
我们实验了信息瓶颈损失函数(information bottleneck loss)相对于其它无监督表示学习损失函数的优势,包括:1. InfoMax;2. MVI;3. CL(Contrastive Learning)。如下表所示,RLP-UML 采用的信息瓶颈损失函数比其它损失函数效果更加优异。

3.2.2 伪偏好数据生成
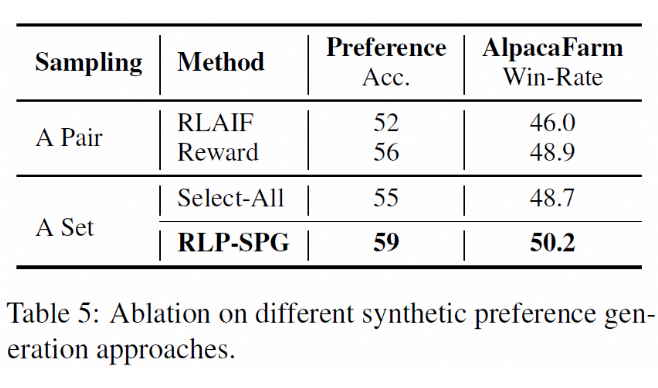
我们对比了两种类型的伪偏好数据的生成方法:1. LLMs生成两个结果并打分;2. LLMs 生成一个结果集合,并选取其中的被选择(preferred)结果和不被选择(non-preferred)结果。
对于第一类方法,我们实现了 RLAIF 基于策略模型排序,以及 Reward 基于奖励模型排序。对于第二类方法,我们实现了 Select-All,即通过设置不做生成结果过滤。如下表所示,RLP-SPG 在构造偏好数据的准确性以及微调 LLMs 的效果方面都超过其它方法。

总结
本文提出一种新的大语言模型与人类偏好对齐的方法,即基于策略模型进一步优化奖励模型 Reward Learning on Policy(RLP)。RLP 通过多视角信息瓶颈损失函数可鲁棒地学习策略模型样本分布的表示。RLP 通过构造策略模型的结果集合,有选择地生成高置信度的偏好数据集。大量实验表明 RLP 效果优于目前的 SOTA 基准方法。

参考文献
[1] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, and others. 2022. Training language models to follow instructions with human feedback. In NeurIPS.
[2] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. In NeurIPS.
[3] Stephen Casper, Xander Davies, Claudia Shi, and others. 2023. Open problems and fundamental limitations of reinforcement learning from human feedback. TMLR.
如果对我们的工作感兴趣的话,欢迎加入我们!
招聘岗位:Research Intern
工作地点:北京
团队介绍:阿里通义实验室对话智能团队,以大模型研究和应用为中心,推进大模型的大规模商业化应用,主要技术包括:对话、RAG 问答、Code、AI Agents、人类对齐、高效训练等。
过去三年发表 60+ 篇国际顶会论文, ACL 2023 中稿 9 篇,NeurIPS 2023 中稿 2 篇,EMNLP 2023 中稿 7 篇;主要业务场景包括通义晓蜜、通义灵码、通义听悟等。
团队Google scholar:
https://scholar.google.com/citations?user=5QkHNpkAAAAJ
团队Github:
https://github.com/AlibabaResearch/DAMO-ConvAI
岗位要求:
1. 在人工智能相关方向的硕士 / 博士,有 NeurIPS / ICLR / ICML / ACL / EMNLP / NAACL 等顶会论文者优先;
2. 热爱技术,理论扎实,有大模型经验者优先;
3. 具备优秀的分析问题和解决问题的能力,以及良好的沟通协作能力;
简历投递:hao.lang@alibaba-inc.com
邮件标题和简历标明:姓名-岗位名称-PaperWeekly
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









