







在这项工作中,我们利用语言序列的内在分段特性,设计了一种新的位置编码方法来达到更好的长度外推效果,称为双层位置编码(BiPE)。对于每个位置,我们的 BiPE 融合了段内编码和段间编码。段内编码通过绝对位置编码标识段内位置,并帮助模型捕捉其中的语义信息。段间编码指定段索引,通过相对位置编码建模段间关系,旨在提高外推能力。
理论分析表明,这种位置信息的解耦使学习更加有效。实证结果也表明,我们的 BiPE 在各种文本模态的广泛任务中具有优越的长度外推能力。这一研究已被 ICML 2024 接收。

论文标题:
Two Stones Hit One Bird: Bilevel Positional Encoding for Better Length Extrapolation
论文链接:
https://arxiv.org/abs/2401.16421
代码链接:
https://github.com/zhenyuhe00/BiPE

研究背景
在许多场景中,文本可以有效地分解为模块化的段落,每个段落都表达一个自成一体的思想单元 [1]。在自然语言中,文档通常由句子组成。每个句子描述一个独特的想法或论点。在编程语言中,代码被组织成行或函数类,以定义连贯的操作或功能。在数学中,证明通过一系列演绎步骤展开,每一步代表从前面的步骤到最终答案的逻辑进展。
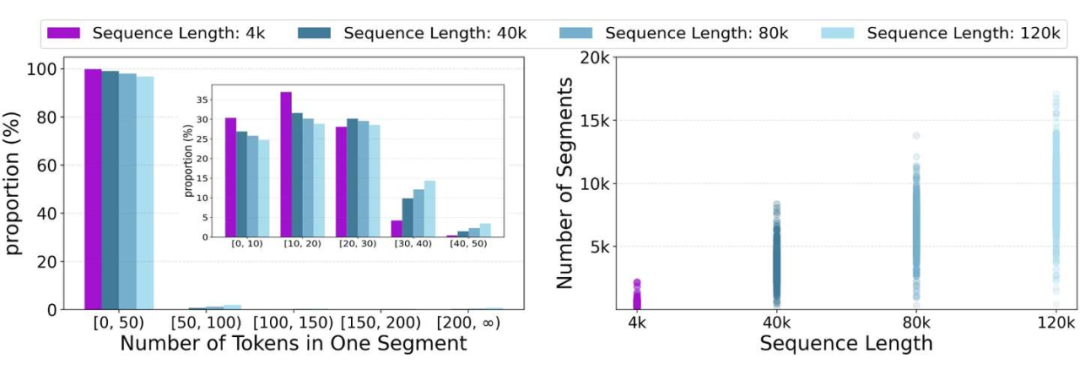
不同文本序列的长度可能有显著差异。有趣的是,我们实证观察到,对于不同长度的序列,每个模块段中的 token 数量分布通常是有界的,并且趋于大致相似。在图 1 中,我们使用了广泛使用的 PG-19 文本语料库进行可视化。显然,每个段落(即句子)中的 token 数量分布无论总序列长度如何,都保持了显著的一致性。相比之下,随着序列长度的增加,句子的数量呈线性增长。

方法
在本文中,我们介绍一种简单但有效的用于改善长度外推的定位编码方案:BiPE。与现有的长度外推方法不同,BiPE 为每个位置采用了两种不同的编码:段内编码和段间编码。
段内编码标识标记在其段内的位置。作为补充,段间编码指定其所属的段。以自然语言为例,同一句子中的不同词语共享相同的段间位置编码,但具有不同的段内编码。相反,不同句子中但占据相同段间位置的词语(例如,不同句子中的第一个 token)共享相同的段内编码,而具有不同的段间编码。请参见图 2 以获取示意图。


BiPE的理论分析
我们利用了在理论计算机科学领域广泛使用的(非确定性)有限自动机(NFA)。Alur [2] 等人提出了分层有限自动机,作为表示此类语言结构的实用方法。受该框架的启发,我们引入了一种简化模型——Bi-NFA,该模型将分层有限自动机的层级限制为两层。
我们比较了 Transformer 在表示 NFA 和 Bi-NFA 方面的参数效率,并展示了 BiPE 在现有位置编码方案上具有理论优势(理论细节敬请参考原文)。

实验结果
在 BiPE 的框架下,我们实例化了两种位置编码:BiPE-RoPE 和 BiPE-ALiBi。他们两者都使用绝对位置编码来作为段内编码。BiPE-RoPE 使用 RoPE 作为段间位置编码,BiPE-ALiBi 使用 ALiBi 作为段间位置编码。
我们首先验证了在思维链数学推理任务上,BiPE 在同参数量的情况下效果更好。在图 3 中可以清楚地看到,给定相似数量的参数,基于 BiPE 的语言模型在此任务上始终优于其他基线方法。
例如,当隐藏维度为 48 时,其他位置编码方法的准确率较低(低于 70%),而 BiPE-ALiBi 和 BiPE-RoPE 的准确率分别高达 97% 和 95%。这一结果确实很好地与我们的理论结果一致,这进一步强有力地支持了我们 BiPE 的双层设计。

我们对采用不同位置编码的 Transformer 模型在 Pile 数据集预训练过后,测试长度外推的能力。结果如图 4 所示。我们的 BiPE 方法在长度大于训练长度的序列上始终表现出更优越的性能。例如,在序列长度为 8192 的 PG19 数据集上,我们的 BiPE-ALiBi 以 25.24 的困惑度(perplexity)优于它的对标方法 ALiBi(28.59 的困惑度),领先了 3.35 点。
相比之下,RoPE 尽管在分布内长度的序列上表现良好,但在较长序列上的性能显著下降,而我们的 BiPE 方法显著提升了其长度外推能力,例如,在序列长度为 4096 的 PG19 数据集上,困惑度为 19.67,而 RoPE 的困惑度为 158。
值得注意的是,我们的 BiPE 方法在全部三个覆盖不同模态文本数据的评估数据集上均表现出一致的优势,突显了 BiPE 在实际任务中的更佳长度外推能力。

将 BiPE-RoPE 和对 RoPE 做微调的方法结合: 最近在长度外推方面的改进之一来自于使用位置插值(Position Interpolation)技术对基于 RoPE 的语言模型进行持续微调 [3,4]。
为了进一步研究我们的 BiPE 方法与位置插值的兼容性,我们使用 YaRN [4] 对在 Pile 数据集上预训练的 RoPE 和我们的 BiPE-RoPE 进行微调,并检查在下游数据集上的改进。结果如图 5 所示,我们的 BiPE-RoPE 在微调后对较长序列始终表现出更好的性能。
进一步来说,虽然 YaRN 在一定程度上提升了 RoPE 的长度外推能力,但在评估非常长的序列时仍然会出现性能下降,例如在 PG19/ArXiv/Github 数据集上评估 11k/16k/16k 长度的序列时。而相比之下,我们结合 YaRN 的 BiPE-RoPE 展现出更强的长度外推能力,即在长度高达 20k 的序列上保持了一致的低困惑度。

为了进一步评测长文本能力,我们将不同位置编码的预训练模型在SCROLLS数据集上微调并测试,结果如表 1 所示,首先,BiPE-RoPE 和 BiPE-ALiBi 分别表现优于 RoPE 和 ALiBi。例如,我们的 BiPE-RoPE 以 22.36 的平均分数超过了其对标方法 RoPE(18.38 的平均分数),领先了 3.98 分。
此外,BiPE-RoPE 取得了最高的平均分数,超过其他方法 3 分以上。在逐任务评估中,BiPE-RoPE 在 7 个任务中的 4 个任务中取得了最高分。我们还比较了两种经过 YaRN 微调的模型,即 BiPE-RoPE 和 RoPE。可以看到,BiPE-RoPE 在 7 个任务中的 6 个任务上仍然持续由于 RoPE, 并取得了更好的平均分数。这些结果进一步强化了 BiPE 在长上下文建模中的有效性。


总结
在本文中,我们介绍了 BiPE,一种旨在改进长度外推的新型双层位置编码方案。对于每个位置,我们的 BiPE 结合了 1)通过 APE 确定其在段内位置的段内编码,以及 2)通过 RPE 指定其所属段的段间编码。
段内编码帮助模型捕捉每个段内的语义信息,而段间编码则建模段与段之间的关系。这种双层设计很好地契合了文本数据的内在分段结构,并增强了长度外推能力。我们的 BiPE 还通过其表达能力的理论分析得到了进一步支持。所有实验均验证了 BiPE 在不同文本模态任务中的长度外推能力。

参考文献
[1] Halliday, M. A. K. and Matthiessen, C. M. Halliday’s introduction to functional grammar. Routledge, 2013.
[2] Alur, R., Kannan, S., and Yannakakis, M. Communicating hierarchical state machines. In Automata, Languages and Programming: 26th International Colloquium, ICALP’99 Prague, Czech Republic, July 11–15, 1999 Proceedings 26, pp. 169–178. Springer, 1999.
[3] Chen, S., Wong, S., Chen, L., and Tian, Y. Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595, 2023b.
[4] Peng, B., Quesnelle, J., Fan, H., and Shippole, E. Yarn: Efficient context window extension of large language models, 2023.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·
















 2277
2277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









