







©PaperWeekly 原创 · 作者 | 许修为
单位 | 清华大学博士生
研究方向 | 计算机视觉,具身智能
在这篇文章中,我们提出了 EmbodiedSAM,一个实时在线的 3D 分割一切模型。可以直接读入 RGB-D 流视频进行 efficient 且 fine-grained 的在线三维实例分割,这也是对我们之前 CVPR 2024 工作 Online3D 的一个延续(更快、更细!),代码、数据和模型权重均在 github 开源,欢迎访问。

论文标题:
EmbodiedSAM: Online Segment Any 3D Thing in Real Time
论文地址:
https://arxiv.org/pdf/2408.11811
代码仓库:
https://github.com/xuxw98/ESAM
项目主页:
https://xuxw98.github.io/ESAM

简介
EmbodiedSAM 的出发点来自于一个思考:具身智能需要什么形式的场景感知?考虑到最为普遍的具身场景是机器人在未知环境中同时完成对场景的探索和感知,我们认为一个好的具身感知模型应该具有四点性质:
1. 在线。不同于先重建再感知,在线意味着机器人一边读入 RGB-D 视频流,一边就要进行场景感知,在每一时刻对未来是不可知的;
2. 实时。一个快速的感知模型才能让决策规划的模块没有负担地进行调用,每秒钟至少需要能够处理上十帧的数据(当前水平 10+FPS,未来目标 30+FPS);
3. 细粒度。希望能将场景中一切物体进行分割,包括各种小目标(未来可以考虑进一步细化到物体的 part);
4. 泛化性。一个模型即可以处理多样化的场景,甚至可以适配不同型号的传感器,即不同内参的 RGB-D 相机。这是一个美好的想法,但目前 3D 数据的质量和规模还难以满足仅通过 3D 训练出具备上述能力的模型。
如何解决这个问题?目前一个常用的思路是充分利用现有的高质量 2D 视觉基础模型,目前已经有很多又快又好的模型可以以很快的速度实现细粒度的 2D 分割,如 FastSAM [1] 等。
目前SAM3D [2,3] 之类的 3D 分割工作通过 2D 基础模型进行图像分割,将结果映射到深度图转化的点云中,再在三维空间中设计基于点云的合并策略以完成 3D 实例分割。这一套思路仅利用2D模型就可以完成较高细粒度和泛化性的 3D 实例分割,但存在诸多问题:
1. 只能用于离线数据,无法在线处理流视频;
2. 速度极慢,处理一个场景需要数分钟甚至数十分钟的时间;
3. 缺乏 3D 感知能力,仅独立对每一帧 RGB-D 图像中的 RGB 信息进行分割,没有利用深度信息,也没有利用多视角的几何关联。
为此,我们的 EmbodiedSAM 采用先 2D 后 3D 的分割范式,对每一张 RGB 图像利用高效率的基础模型进行分割,得到初始的单帧分割结果,将此结果在 3D 空间进行可学习的优化和帧间融合,从而实现实时在线的 3D Segment Anything。
由于分割的任务交给了 2D 模型,我们的 3D 模型只需要充分利用时序和几何信息对来自 2D 的 mask 进行优化,以及对不同帧的相同物体进行融合,学习难度大大降低,目前的 3D 数据集完全可以满足需求。

以上是一个简单的示例 demo(更详细的视频可以在我们的项目主页观看),和 SAM3D 等离线 3D 分割方法相比,我们的方法可以用于更难的在线任务,且性能大幅提升,速度快将近 20 倍,处理一个完整的室内场景只需要5s左右的时间。

方法
下面是我们的整体框架,个人一直觉得方法部分看原文就好,中文解读更重要的是 motivation 和整体思路,因此这次也是从比较 high-level 的角度介绍一下方法(其实是翻译太累了)。
EmbodiedSAM 的输入为已知相机内外参的 RGB-D 视频流,我们整体分为三个环节,对于每一时刻新读取的 RGB-D 帧,首先是 Query Lifting 阶段,将 2D 基础模型的分割结果转换到 3D 空间,并用 query 特征的形式来表示,一个 query 对应一个 2D 模型分割出来的物体。
这种表示形式一方面可以充分将 3D 和时序特征进行融入,另一方面也便于后续的 Mask 优化和帧间融合;之后是 Query Refinement 环节,通过物体 query 之间的交互,以及和场景特征的交互,更新 query 特征,并将 3D 中的分割结果进行更新优化。注意 Query Lifting 和 Query Refinement 操作都只对当前帧的物体进行操作。
最后在 Query Merging 环节中,我们将当前帧分割出的物体与过去的物体进行融合,例如当前帧和之前帧都观测到了同一把椅子,那它们的全局 instance id 应该相同,这也就是所谓的 instance merge,如果是之前帧没见过的新物体,那便在全局 instance id 中注册新物体即可。
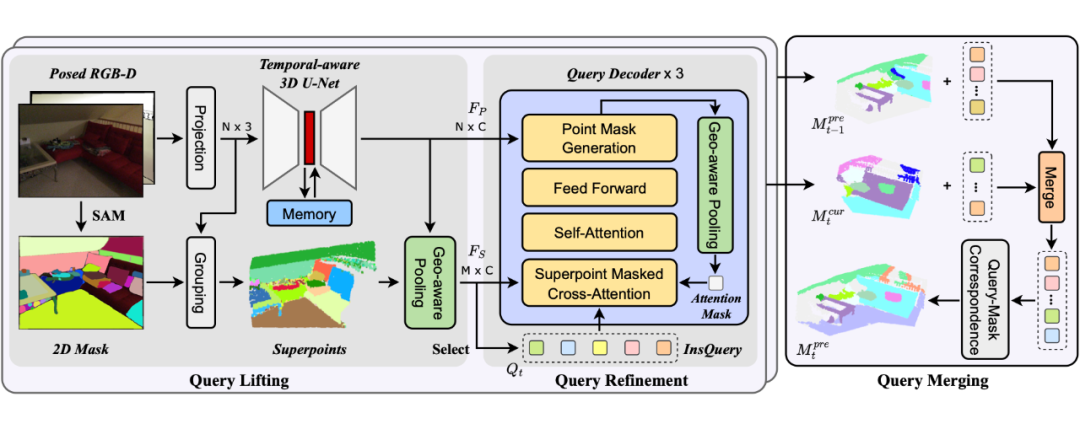
2.1 Query Lifting
对于当前时刻新观测的 RGB-D,我们首先用 2D 基础模型(VFM)对 RGB 进行分割,并将分割结果映射到深度图上转换为点云,从而得到 3D 点云上的分割结果。不同于之前的方法直接对 3D 分割结果进行融合,我们认为仅通过 2D VFM 分割,虽然细粒度和泛化性很强,但对于空间信息的利用不够充分,容易有较大误差。
因此我们用一个具有时序能力的 3D 骨干网络 [4] 提取点云特征(可以挖掘当前帧和过去帧点云的关联),并将 3D 分割结果视为 superpoint,引导 point-wise 特征池化到 superpoint-wise 特征,从而获取各物体的 query 表示。
我们额外设计了一个具有几何感知能力的池化方法(Geo-aware Pooling),对于落入同一个 superpoint 内的点云特征,不仅仅是做 max pooling 或者 average pooling,而是考虑到 superpoint 自身的几何形状,给不同空间位置的特征赋予不同的权重。
2.2 Query Refinement
类似于基于 Mask2Former [5] 等基于 Transformer 的实例分割架构,我们也利用若干层 Transformer 对每个物体的 query 信息进行更新优化,在每层Transformer 中,query 特征分别和当前帧点云特征进行 cross-attention,和自身进行 self-attention,并最终和当前帧点云特征交互得到优化后的 3D Mask。
该过程有几个不同的设计,首先是我们采用了不同层次的点云特征,来获取最好的 efficiency-accuracy tradeoff。
对于 cross-attention,我们采用 superpoint-wise 特征进行交互,superpoint 数量少但是包含了场景中的所有信息,有利于加速运算。对于 3D Mask 预测,我们则将 query 和 point-wise 特征进行交互,从而得到细粒度的分割结果。
其次,在每层 Transformer 拿到 point-wise 的分割结果后,我们会利用之前 Geo-aware Pooling 的权重将分割结果池化为 superpoint-wise,用于下一层中进行 masked cross-attention(即通过初步的分割结果限定 cross-attention 的作用范围)。
2.3 Query Merging
完成上述阶段后,我们拿到了当前帧优化后的 3D Mask,基于和 3D Mask一一对应的 query 特征,同时我们还有之前帧的全局 3D Mask。这一阶段需要将当前帧 3D Mask 与之前的 Mask 进行全局融合,判断当前帧每个物体是融入到过去已存在的某个物体,还是注册为新物体。
这一过程也是时间上最大的瓶颈,之前如 SAM3D 等手工融合的方法不仅对超参数较为敏感,而且速度极慢,能否又快又准完成 3D Mask 的全局融合是一个非常有挑战的问题。
这里得益于我们的 query 表示,我们可以将 3D Mask 的融合问题转换为 query 融合问题。不同物体的 3D Mask 含点云数量不同,难以高效率并行计算,只能在循环中计算 3D Mask 间的空间距离设置阈值完成融合。
而不同物体的 query 尺寸是相同的,例如之前帧一共有 M 个物体,当前帧一共 N 个物体,由于每个物体都有一一对应的 query,因此这个问题可以通过矩阵乘法直接完成相似度计算!
假设 query 特征维度为 C,我们将 MxC 和 NxC 的特征相乘便得到 MxN 的相似度矩阵,再通过二分图匹配的方法在该矩阵上得到匹配关系。对于匹配上的物体,我们将其 3D Mask 合并,并将对应的 query 特征加权融合;对于未匹配上的物体则直接注册为全局新物体。
实际中,仅依靠 query 表示虽然高效,却仍存在表示能力不够的问题。我们在不影响速度的前提下设计了三种更细致的判据,通过不同的 MLP head 在 query 上预测出三种表示:1)物体的外接框;2)物体的对比表示;3)物体的语义表示。这三种表示具体含义如下图所示。
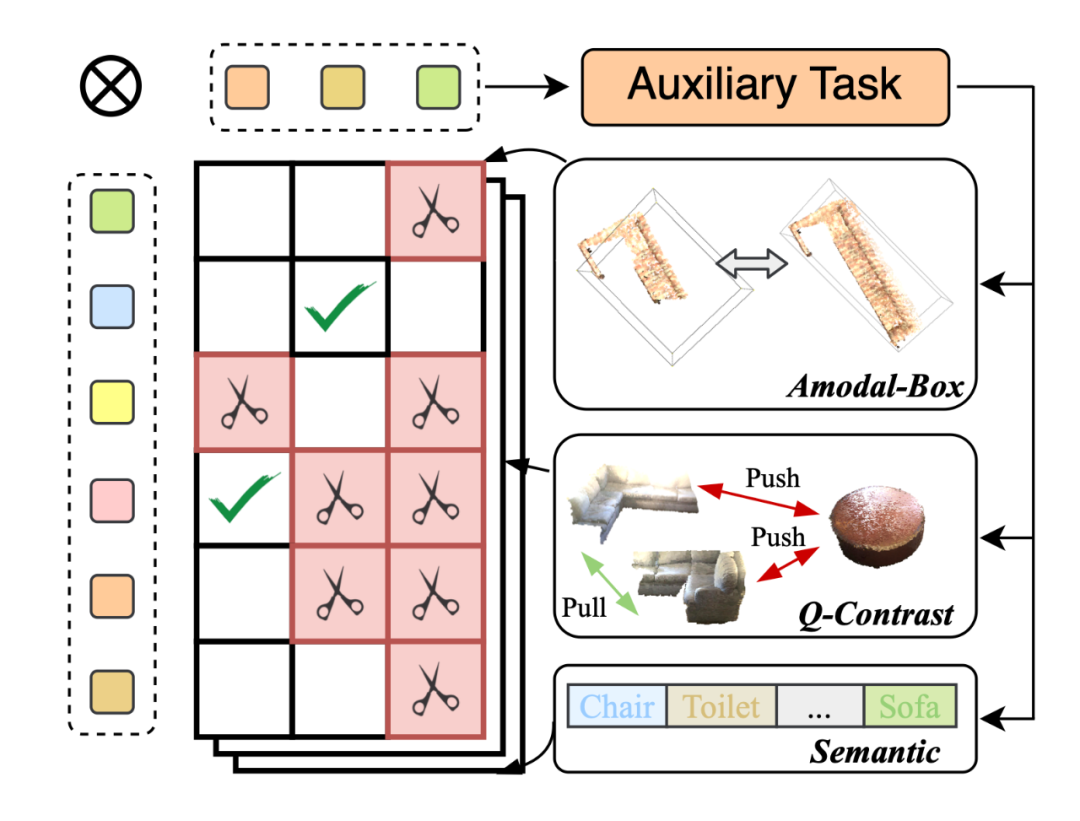
每次进行 3D Mask 的融合后,这三种表示也会进行对应的加权融合,并作为“过去帧”再次与未来的“当前帧”进行高效融合。由于所有操作仅需要矩阵乘法和二分图匹配,所需时间在 5ms 以内,相比手工融合的策略快数百倍,且性能更强!

实验结果
我们进行了多种设置的实验。首先是 class-agnostic 3D instance segmentation,对标 SAM3D 等文章的设置。由于这些文章大多数为 zero-shot,而我们需要训练,为了更公平展示泛化性,我们还进行了 zero-shot 迁移实验,从 ScanNet200 迁移到 SceneNN 和 3RScan 上。
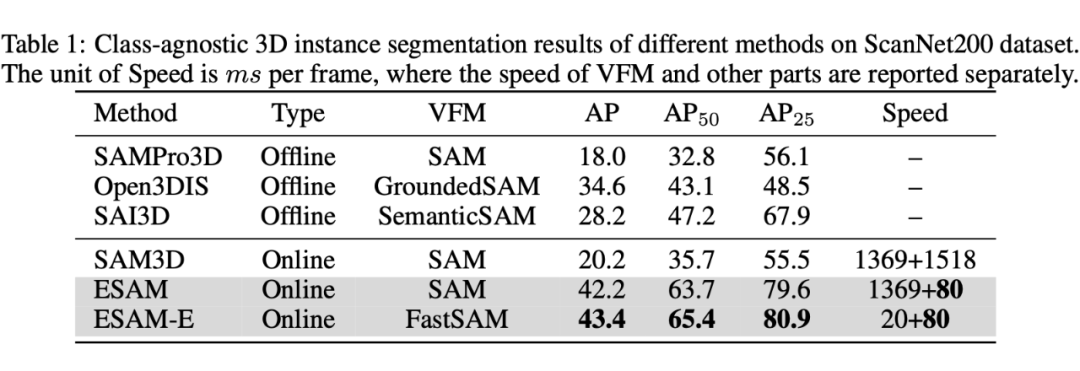
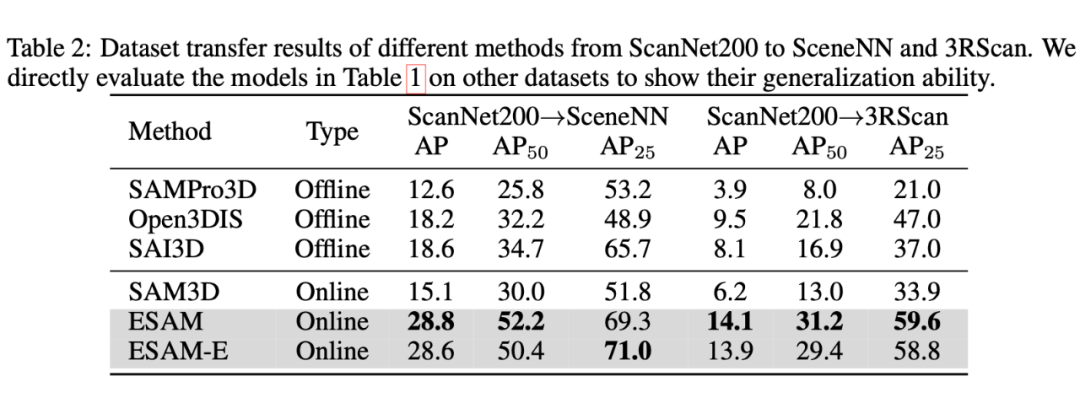
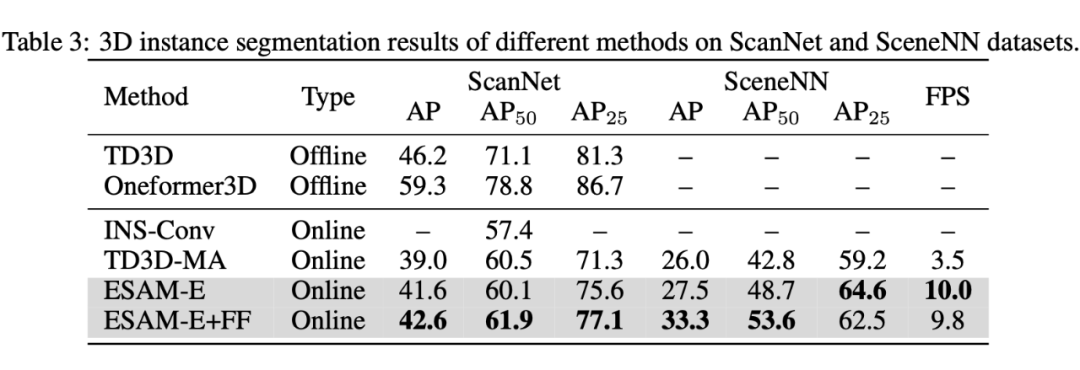
此外我们还进行了 online 3D instance segmentation 的实验,对标之前的在线 3D 实例分割工作。在两种任务上我们都取得了 SOTA 的性能和速度。
我们还分析了 EmbodiedSAM 的推理时间分布,发现速度的瓶颈主要在 3D 特征提取部分,我们的 merging 策略的开销几乎可以忽略不记。如何加速 3D 骨干网络的特征提取是一个非常有价值的问题,也是未来突破 30FPS 的最后阻碍。

更多实验、可视化和 Demo 视频可以参考我们的论文以及项目主页。如有问题欢迎大家在 github 上开 issue 讨论。

参考文献
[1] Zhao, Xu, et al. 'Fast segment anything.'arXiv preprint arXiv:2306.12156(2023).
[2] Yang, Yunhan, et al. 'Sam3d: Segment anything in 3d scenes.'arXiv preprint arXiv:2306.03908(2023).
[3] Yin, Yingda, et al. 'Sai3d: Segment any instance in 3d scenes.'Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[4] Xu, Xiuwei, et al. 'Memory-based Adapters for Online 3D Scene Perception.'Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024.
[5] Cheng, Bowen, et al. 'Masked-attention mask transformer for universal image segmentation.'Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
·


















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









