








©PaperWeekly 原创 · 作者 | 张逸骅
单位 | 密歇根州立大学博士生
研究方向 | 可信人工智能
过去的两周里,DeepSeek 在社交媒体上宣告这是他们的开源周(OpenSourceWeek),并连续五天放出了多款软件库。
前段时间分别发布了 FlashMLA(高效 Hopper GPU MLA 解码核)、DeepEP(面向 MoE 的专家并行通信库)以及 DeepGEMM(支持 FP8 的 GEMM 库)。而就在第 4 天,他们一口气开源了三大组件:DualPipe、EPLB 以及 profile-data,其中的 DualPipe 因为引入了“双向流水线并行”这一核心理念,引起了广泛讨论。
本文将聚焦于 DualPipe 的核心思路:如何在大模型的训练阶段,实现前向(forward)与后向(backward)的完全重叠,从而大幅降低流水线中的「空闲时间(bubble)」。
为了让读者们更好地理解这些概念,本文从一个通俗易懂的类比——“机械加工中的工艺优化”——切入,并在每个部分先讲清楚比喻场景,再与深度学习中的并行训练一一对应,让读者可以在脑海中形成清晰的“具象”画面。
同时,文末我们将深入到 DualPipe 技术的源码层面,探讨它如何进一步减少流水线气泡、实现前后向交叠、将通信带来的压力减小到极致,且如何在较复杂的混合并行场景下落地。

引言
在大语言模型(Large Language Model)如 GPT-3、PaLM、LLama 等火热的当下,分布式训练已成为突破单卡 GPU 极限、成功训练超大模型的必备手段。
我们经常听到诸如“数据并行”“模型并行”“流水线并行”等名词,但对初学者来说,很难直观把握它们之间的区别与联系。尤其是当大家阅读到一些高级用法,如 DeepSeek-V3 里采用的 DualPipe 技术,可能会觉得晦涩难懂。
与此同时,在工业领域,优化生产工艺需要经过无数次试错;在人工智能领域,训练大语言模型同样需要反复调整参数。这两件事看似毫不相关,却有着惊人的相似性。让我们跟随老王机械加工厂的故事,看看如何用车间里的机床与工序,理解大模型训练中的四大并行技术。
1.1 单卡时代:从手工小作坊说起
在苏州工业园区,老王拥有一个不大不小的机械公司,他的公司的主要业务是为机械产品的优化加工工艺,比如铸造温度、淬火时间、切削角度等等。
每当一个新的订单到来时,老王会根据经验设计一份初始工艺手册,按照这个工艺手册进行加工,对加工后的零件进行质量检测,并根据当前加工出来的零件缺陷,从后往前,对每一道工艺进行参数调整:比如当前加工出来的产品有空隙缺陷,就告诉我们铸造温度应该升高一些。
老王的工艺流程其实和大模型训练非常契合:所谓的工艺手册就像大模型的参数一样、而加工的零件就是大模型的训练数据、不同的工艺对应大模型的各种层,机床就像 GPU 一样,最后所谓的质量检测就是损失函数的计算、而根据之间结果对工艺进行调整也正是大模型的梯度回传和参数更新的过程。
在创业初期,老王最初只接螺丝钉加工订单。这类零件加工简单,只需在一台多功能机床上完成切削、打磨两道工序。每当出现次品,老师傅就会对着成品倒推问题:如果是打磨不匀,就调整打磨参数;若是切削误差,就修改刀具角度。
整个过程都在同一台机床上闭环完成。老王的工厂就像一个手工小作坊:不成体系不成规模,但对于简单的零件还是够用的。
这就像单 GPU 训练场景。模型的所有层(工序)都在同一块 GPU(机床)上顺序执行,前向传播(加工零件)和反向传播(参数调整)都在单一设备内完成。虽然简单可靠,但面对复杂任务时,设备性能就会成为瓶颈。
1.2 模型并行(Model Parallelism):工艺手册的拆分艺术
有一天老王接到了一个以前没有遇到过的大单子:发动机曲轴的工艺优化,老王发现自己的单台机床根本无法胜任这个工作。他将铸造、热处理、精密加工等工序拆分到三台专业机床上。每台机床的操作手册都只记录对应工序的参数标准,且调整铸造参数时必须同步考虑对后续工序的影响。
此时,老王发现了一个以前没有遇到过的问题:机床的闲置问题。在零件进行铸造阶段,热处理和精密加工的机床好像没有事做;于此同时,把一个机床的加工结果搬运到另一个机床上加工的过程好像也需要时间,而在“搬运”的过程中如果不做合理的安排可能会使机床闲置的问题更加严重。
在大语言模型中,这对应“模型并行”(Model Parallel)。当模型的体量过大,单个 GPU 无法容纳所有参数时,就把模型本身(如不同层、不同模块)拆分到多个 GPU 上。
在上边的例子中,铸造就像是模型的输入层、热处理是中间层、而精密加工是输出层。模型训练时每个 GPU 负责特定层的计算,必须通过设备间通信传递中间结果。这种方法的代价是不可避免的 GPU 闲置以及需要频繁的跨设备数据传输。老王遇到的问题正是 GPU 之间的调度和通信的问题。
1.3 数据并行 (Data Parallelism):克隆车间计划
为加速工艺参数优化,资金充裕的老王在隔壁建了三个完全相同的车间。每个车间都配备全套四条产线,分别加工不同批次的涡轮盘(数据分片)。收工时,四个车间的工艺主任会开会比对数据,统一修订工艺标准。原本收到的 10,000 块原材料加工优化需要一个月,现在只需要半个月了。
老王很好奇,为什么我的车间数量翻了四倍,而速度只提升了两倍呢?和车间主任们沟通了解到,原来虽然工艺相同,不同的原材料在加工的过程中会遇到一些独特的问题,导致四个车间的收工时间不一样,你等等我、我等等你,时间就这么被浪费了。
这对应“数据并行”(Data Parallel)。每个车间(GPU)都持有完整的工艺手册(模型参数副本),但加工不同的原材料批次(数据分片)。当遇到次品(计算损失)时,各车间独立推导本批次的工艺调整方案(本地梯度),但需要将所有调整方案汇总平均(All-Reduce)后,才能更新统一的工艺标准(全局参数)。
这种方法的瓶颈在于:最慢的车间(straggler GPU)会拖累整体会议进度(通信同步开销),且车间间的沟通耗时(All-Reduce 带宽)随着车间数量增加而显著上升。
1.4 张量并行(Tensor Parallelism):协作加工超大单件
有一天老王出息了,接到了一个超级订单:飞机机体制造的工艺优化。这种订单加工的零件本身极其巨大,比如飞机机翼。尽管机翼只是某一道工序里的一个大部件,但仍然需要调用很多台同样的机床进行协同。
也就是说,这个单件虽然属于某个特定的工序模块,但其体量依然超出了单台机床的处理能力。因此,老王就安排多台相同功能的机床一同来完成同一个大零件的加工。
在大语言模型训练中,这对应“张量并行”(Tensor Parallel)。即便将模型分割成不同模块后,某些单个模块本身依然很大。
此时,需要把这部分网络层对应的张量再进行更细粒度地拆分,分别放到多个 GPU 进行并行计算。比如把一个巨大的矩阵分割成不同的块,分别放到不同 GPU 上并行做矩阵乘法,再把结果合并。这样,单层的计算负载也能够通过多卡来分摊。
这时,老王发现对机床的调度已经成了提升他工作效率的重中之重,因为此时不同机床间的协作非常密切,大部分机床都只负责某一部分或者某一小部分的零件加工,零件需要频繁地运送到某个机床又运送出去,后边工序的机床必须要前一个工序结束后才能工作,在质检后的反馈阶段,前一个工序的参数调整又必须等待后一个工序的参数调整完毕。
这样就留下了大量的闲置问题:同时加工同一个零件的机床在等着他的兄弟机床结束任务、后一个机床在等前一个机床的工件送过来,又或是前一个机床在等后一个机床的反馈报告。老王觉得必须做点什么才能让自己公司的效率更高了。
这对应”张量并行”(Tensor Parallel)的深层逻辑。当单个工序(模型层)的处理需求超过单台机床(GPU)的承载能力时,就需要将巨型零件(大张量)拆分为多个部件,分发给相同功能的机床组(GPU 组)协同加工。比如机翼的抛光工序需要四台机床分别处理不同区域的表面,再通过拼接(张量通信)确保接缝处的完美衔接。
但这类协作带来了三重挑战:零件拆分/组装需要额外运输时间(张量切分与合并的通信开销)、任何机床的延迟都会拖慢整组进度(同步等待)、质检反馈需要在机床组内部完成多轮协商(梯度同步),这些因素共同导致了新的闲置形态——”协作气泡”。
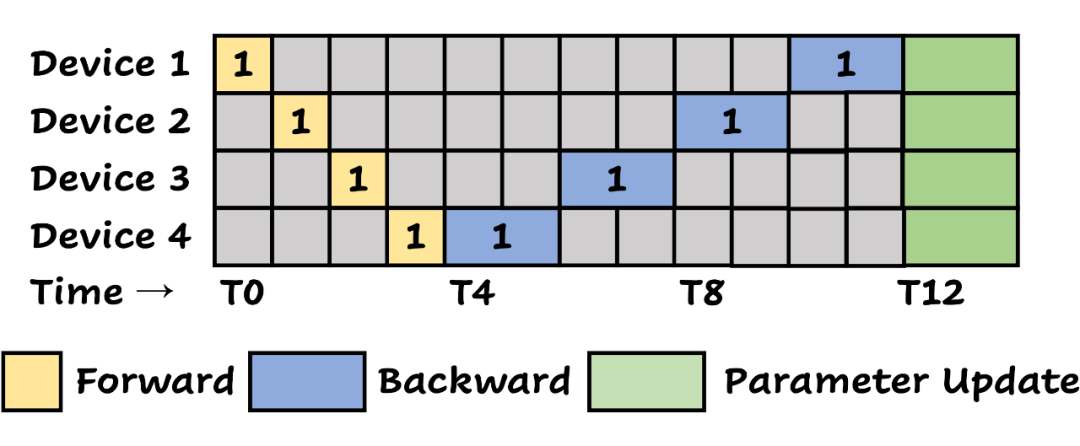
1.5 流水线并行(Pipeline Parallelization):让不同机床同时高效运转
针对不同工序间的协作困境,老王设计了一套精巧的流水线系统:如果原始的加工路线是:铸造 - 锻造 - 热处理 - 抛光,当铸造机床完成第一批零件的初加工时,这批零件立即被送往锻造,而此时铸造机床已开始处理第二批零件;当第一批零件完成锻造进入热处理线时,第二批零件恰好在锻造线就位——就像多米诺骨牌般环环相扣。
▲ 不采用流水线并行时,数据的传输流程:数据在模型的不同部位依次传递,每次只有一个 GPU 在工作,大量的等待时间使得 GPU 的利用效率非常低。
具体得讲,在未实行流水线系统之前,四个车间的工作模式就像上图展示的这样,第一批原料在被加工成成品等待检验前(T1~T4),每个时刻仅有一台机床在工作,而当质检报告生成后,参数调整又按顺序原路返回,导致在参数调整阶段(T5-T12),仍然只有一台设备没有处于闲置状态。
在上图汇总,灰色区域表示在对应时间段,该车间处于闲置状态。
聪明的老王一眼就看出来问
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









