







©PaperWeekly 原创 · 作者 | 张林峰
单位 | 上海交通大学人工智能学院

背景
随着人工智能的广泛应用,尤其在视觉和语言处理领域,模型的可解释性变得至关重要。在高风险场景(如医疗和金融)中,理解 AI 决策过程对于确保系统的可靠性、公平性和合规性至关重要。
然而,许多先进的深度学习模型,尤其是 Transformer 架构的黑盒模型,虽然在任务中表现卓越,但其缺乏透明度,限制了实际应用。
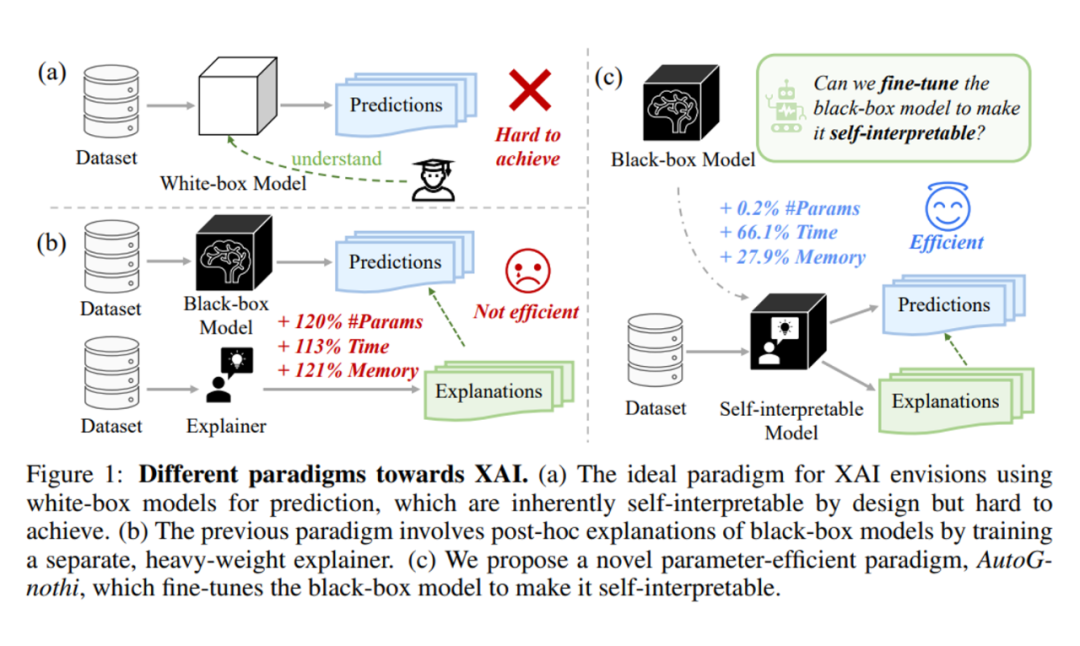
现有的可解释人工智能(XAI)方法大致分为两类:自解释模型和事后解释方法。自解释模型通过将决策与人类可理解的概念关联来提供解释,但常常牺牲性能;事后解释方法如基于 Shapley Value 方法的 ViT-Shapley 方法(如下图(b)所示),尽管有理论保障,但计算代价高,难以高效应用于复杂模型。
为弥合这两者之间的差距,AutoGnothi 提出了一种新方法(如下图(c)所示),结合了参数高效迁移学习(PETL)和 Shapley Value,旨在使黑盒模型在不牺牲性能的前提下实现高效自解释。
通过集成附加的旁路网络,AutoGnothi 大幅降低了训练、推理和显存占用等开销,并提供了具有理论保证的解释。

介绍
已有的基于 Shapley Value 对 Vision Transformer(ViT)模型进行解释的办法(ViT-Shapley)通过额外训练两个模型(Surrogate 和 Explainer)来生成解释,计算成本开销较大。
AutoGnothi 方法提出了一种高效的自解释性新型框架,通过在黑盒模型基础上加入一个轻量级的旁路网络,实现了模型高效的自解释能力。该方法在保持模型原有性能的同时,提供了具有理论保证的解释。


论文标题:
Gnothi Seauton: Empowering Faithful Self-Interpretability in Black-Box Transformers
收录会议:
ICLR 2025
论文链接:
https://openreview.net/forum?id=UvMSKonce8&invitationId=ICLR.cc/2025/Conference/Submission357
联系方式:
shaobowang1009@sjtu.edu.cn
通讯作者:
zhanglinfeng@sjtu.edu.cn
AutoGnothi 的三大核心贡献:
(1)高效解释:提出了一种新的参数高效的自解释性方法,将黑盒模型(如 ViT 和 BERT)转变为自解释模型,即通过引入轻量级的旁路网络(side network)来生成基于 Shapley Value 的解释,并且冻结主干网络只微调旁路网络,从而减少了训练、推理和显存占用成本,无需使用额外的事后解释器模型。
(2)自解释性:实现了黑盒模型的自解释能力,能够在不影响原模型预测性能的同时输出基于 Shapley Value 的可靠解释。
(3)广泛适用性:已在多个视觉和语言任务上进行了验证,包括使用 ViT、BERT 等常用 Transformer 模型等,具有可扩展性和广泛适用性。

方法
AutoGnothi 的核心思想通过引入旁路微调(side-tuning)技术,减少模型的训练、推理和显存等开销,同时使模型具备自解释能力。
具体而言,AutoGnothi 在原始黑盒模型的基础上,添加了一个旁路网络(side network)。通过只对该旁路网络微调且冻结模型主干,使得黑盒模型能够生成基于 Shapley Value 的解释,而无需进行全量微调。
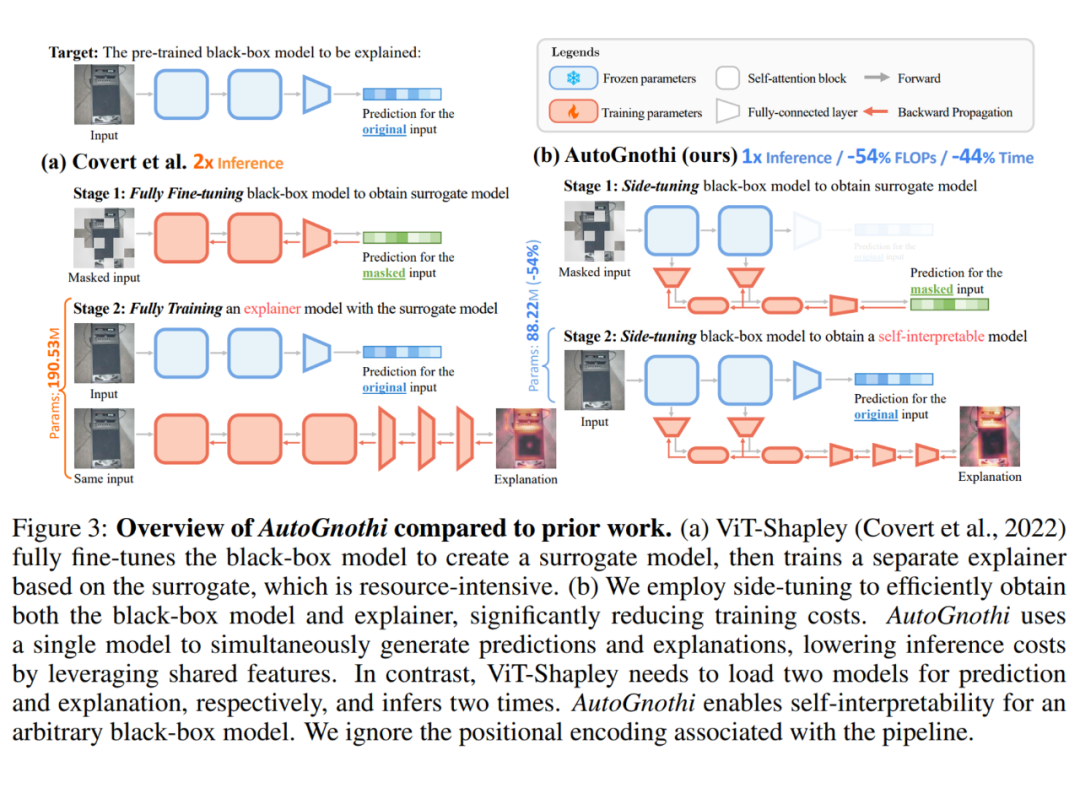
如上图(b)中所示,通过在被解释模型主干上加入低秩旁路网络构建了 Surrogate 模型和 Explainer 模型,Surrogate 是为使模型适应输入存在掩码的情况,在训练中通过 KL 散度最小化来优化;Explainer 则为原始黑盒模型通过如下损失函数生成基于 ShapleyValue 的解释:
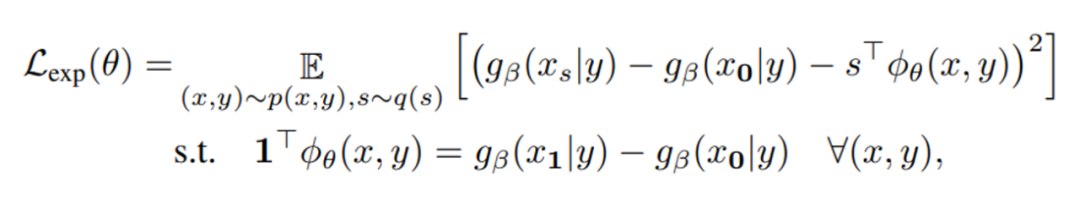
对于 Surrogate 和 Explainer,AutoGnothi 在旁路网络中使用与被解释的黑盒模型相同数量的 causal self-attention 块,并在 ImageNette 和 Oxford IIIT Pets 数据集上采用 r=8 的缩减因子,在 MURA 和 Yelp Review Polarity 数据集上采用 r=4 的缩减因子。
Surrogate 使用与被解释模型相同的任务头即 Prediction head。Explainer 则在旁路网络多个 MSA 块之后,增加了三个全连接层作为解释头即 Explanation head 用以输出解释。

实验结果
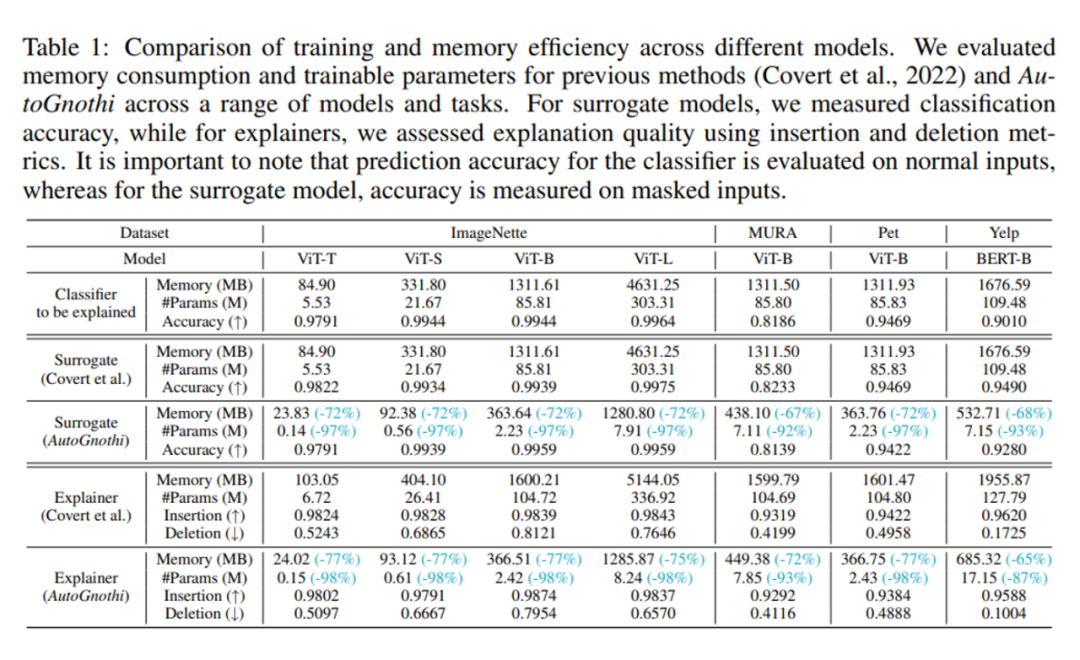
1. 在训练成本和显存占用方面的评估
训练阶段,相较于 ViT-Shapley 这一 baseline,针对在 ImageNette、MURA 和 Oxford-IIIT Pet 三类数据集上的图像分类任务,tiny、small、base、large 四种规模的 ViT 模型应用 AutoGnothi 后,surrogate 模型减少了 67% 以上的显存占用,并且参数量减少了 92% 以上;explainer 模型减少了 72% 以上的显存占用,并且参数量减少了 93% 以上。
而在 Yelp 上的文本分类任务中,Bert 模型应用 AutoGnothi 后,surrogate 模型减少了 68% 的显存占用,并且参数量减少了 93%;explainer 模型减少了 65% 的显存占用,并且参数量减少了 87%。
2. 在推理成本上的评估
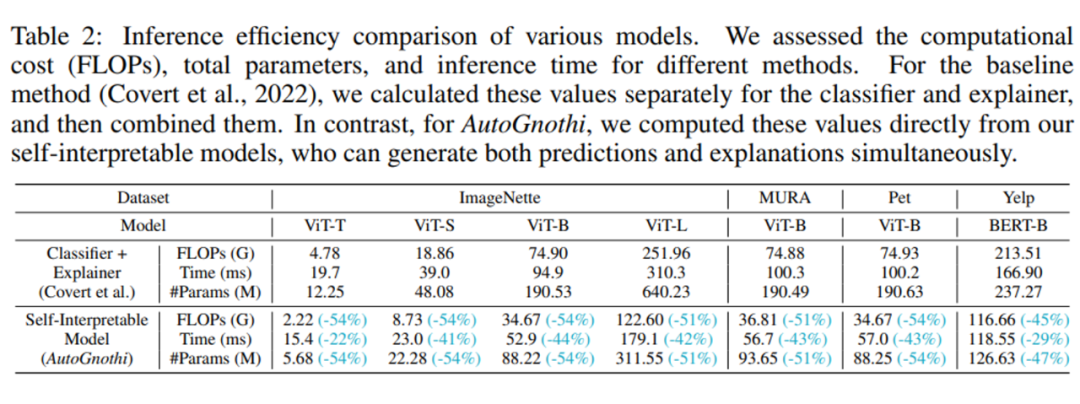
如表 2 所示,为实现模型的自解释能力,针对图像分类任务,应用 AutoGnothi 后推理所需的时间减少 22% 以上,每秒浮点运算次数(FLOPS)下降 51% 以上,并且参数量下降 51% 以上。
针对文本分类任务,应用 AutoGnothi 后推理所需的时间减少 29% 以上,每秒浮点运算次数(FLOPS)下降 45% 以上,并且参数量下降 47% 以上。
3. 在解释指标上的评估
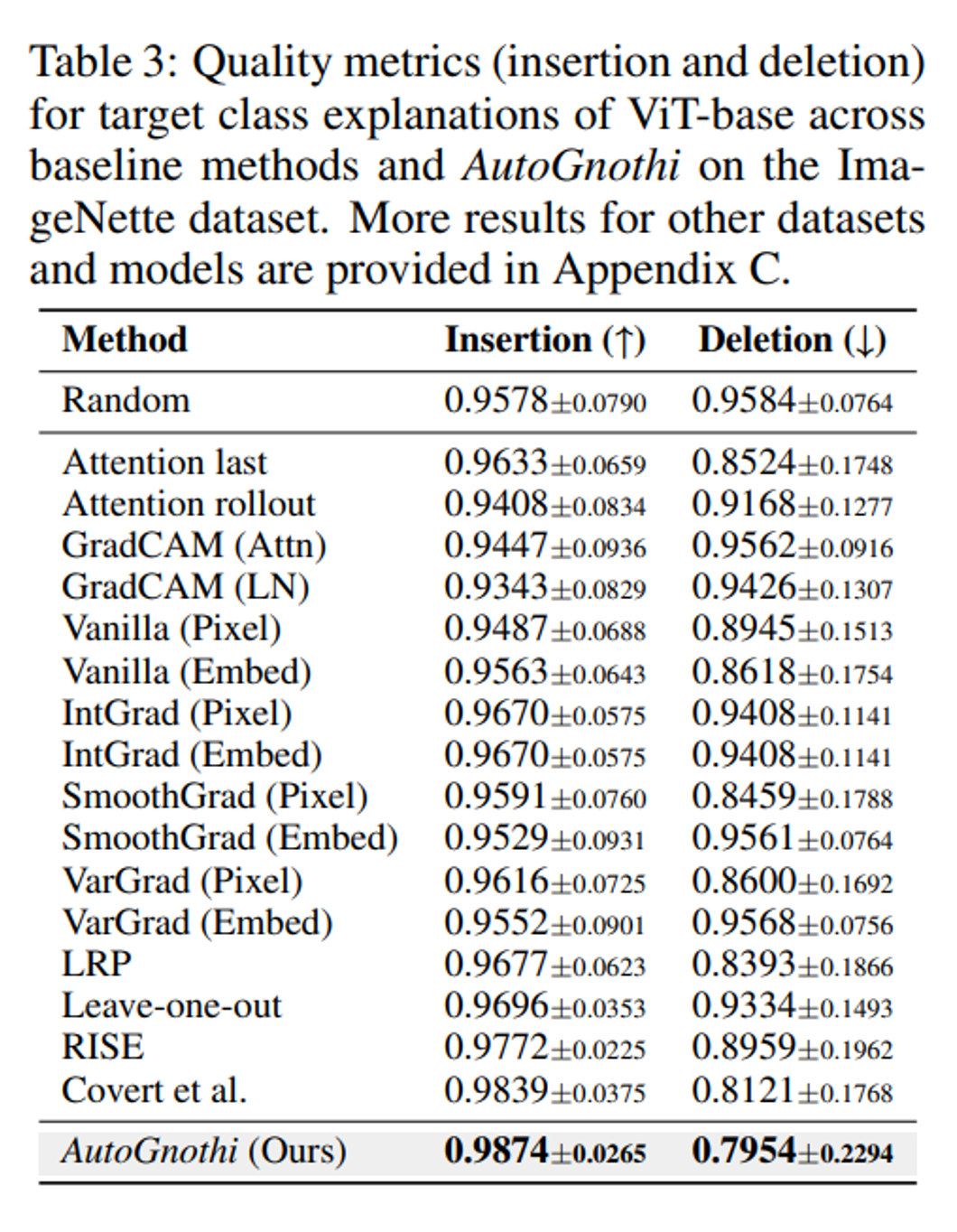
如下表 3 所示,在 ImageNette 数据集上,ViT-base 模型应用 AutoGnothi 后的解释指标 Insertion 和 Deletion 分数均优于 IntGrad,SmoothGrad,VarGrad,LRP,GradCAM,leaveone-out 和 RISE 等一众传统解释方法。
4. 在解释效果图上的评估
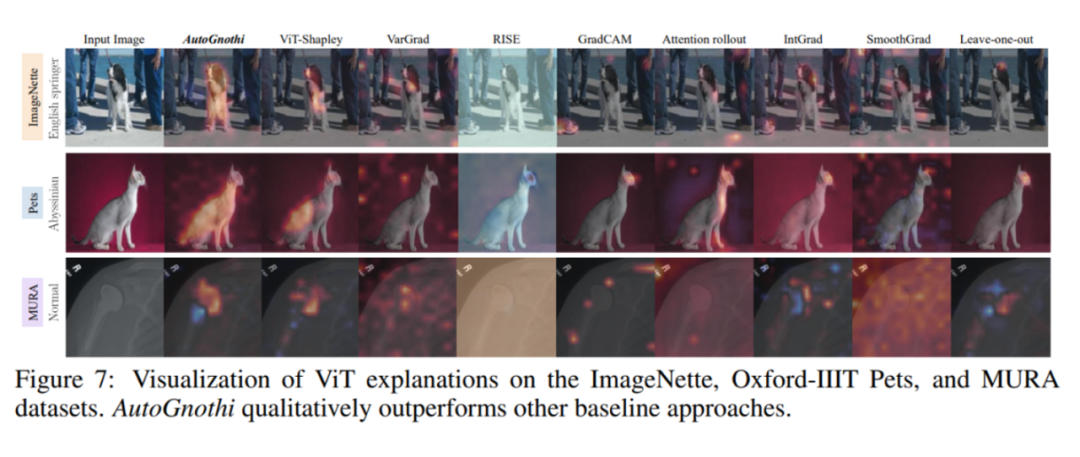
如下图所示,在三类图像数据集上,AutoGnothi 的解释效果明显优于其他传统解释方法。
5. surrogate 和 explainer 的评估
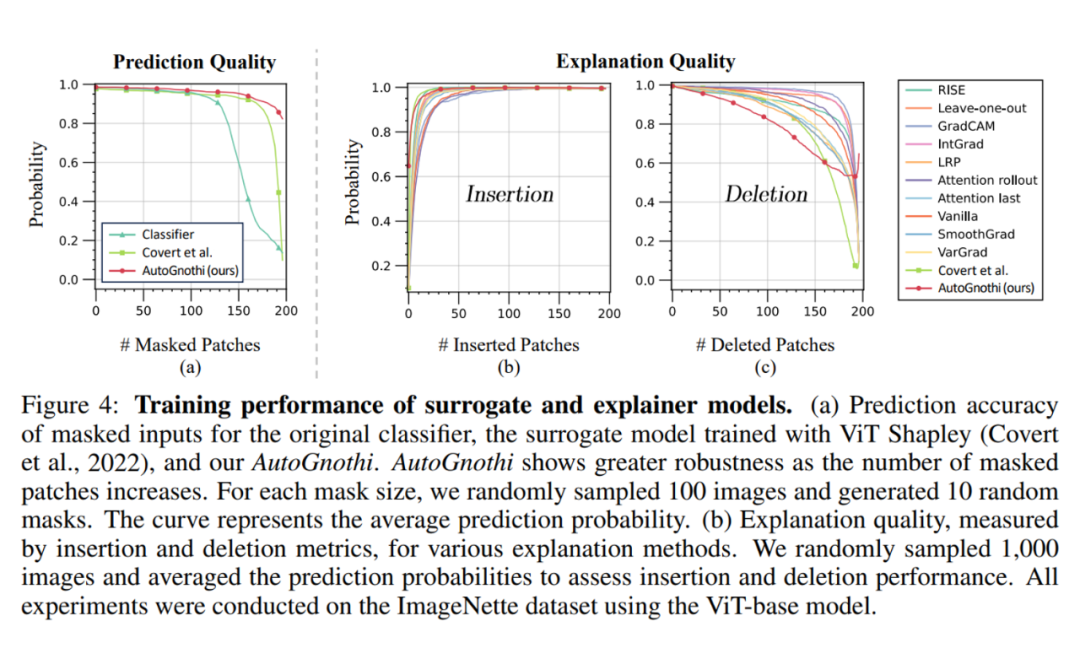
如下图所示,针对 ImageNette 数据集上 ViT-base 在 AutoGnothi 方法中的 Surrogate 模型和 Explainer 模型各自相应的指标均优于 ViT-Shapley 等一众解释方法。

其他自解释性方案探究
在 ImageNette 数据集上针对 ViT 模型,在其 Encoder 模块之后添加 Explanation head:
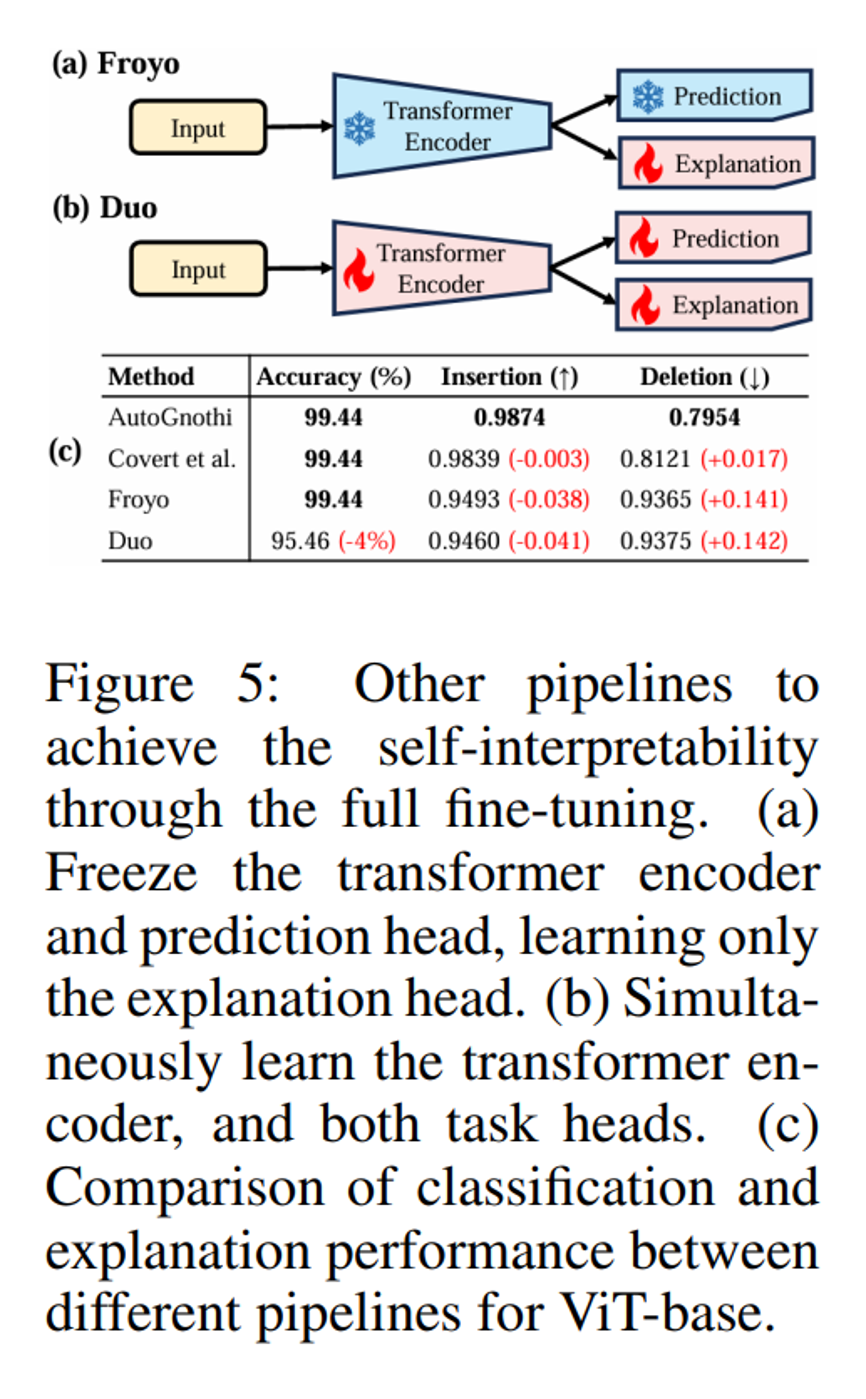
1. Froyo
如下图(a)中的 Froyo 所示,通过将 Transformer Encoder和 Prediction head 冻结并只训练添加的 Explanation head,该方法最终解释指标的 Insertion 和 Deletion 分数均不及 AutoGnothi。
2. Duo
如下图(b)中的 Duo 所示,通过全量微调来同时训练模型的预测和解释任务,与 AutoGnothi 相比,其预测任务的准确率下降 4%,且针对解释指标的 Insertion 和 Deletion 分数均不及 AutoGnothi 方法。值得注意的是,此类方法也导致了忒修斯之船悖论,即“需要被解释的东西,不应该发生变化”。
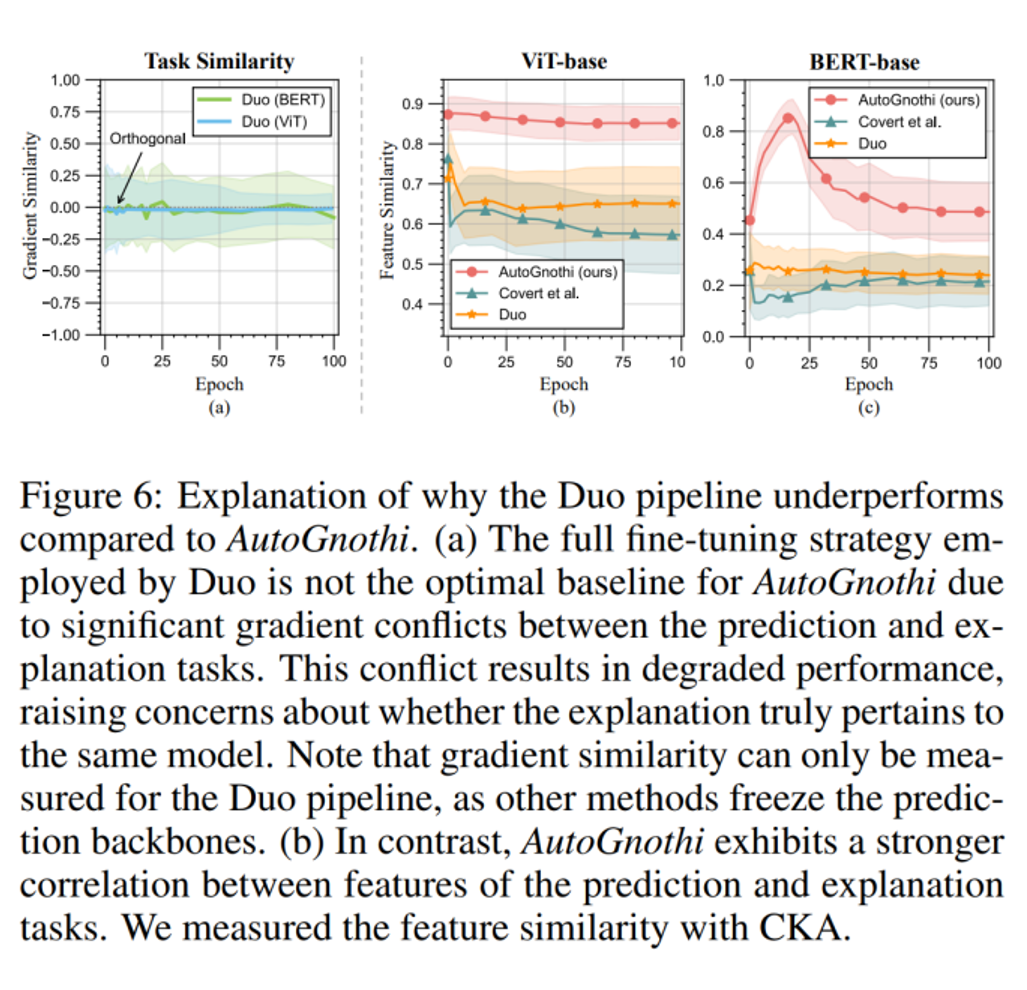
进一步,为研究全量微调 Duo 方法的解释指标结果不及 AutoGnothi 的原因,通过计算 CKA(Correlation of Kernel Activations)指标来衡量模型的预测和解释任务之间的相似性。
根据下图中(a)可知,Duo 方法在训练过程中,预测任务和解释任务之间的梯度存在冲突从而导致整体并没有较高的正相似度;而在下图中(b)和(c)可看出 AutoGnothi 在保持预测和解释任务之间的特征相似度方面表现更好,明显优于 Duo 和 ViT-Shapley。

总结
AutoGnothi,旨在弥合自解释模型与事后解释方法之间的鸿沟,推动可解释人工智能(Explainable AI)领域的发展。
受参数高效迁移学习(PETL)的启发,AutoGnothi 采用了一个轻量级的旁路网络,使黑盒模型能够生成忠实的 Shapley Value 解释,而不会影响原始预测。并且 AutoGnothi 的表现明显优于通过全量微调进行解释的方法。
这种方法赋予黑盒模型自解释能力,优于传统的事后解释方法,后者通常需要在两个独立且计算量大的推理过程中生成预测和解释。通过在 ViT 和 BERT 上的实验,结果表明,AutoGnothi 在训练和推理阶段均展现出了在计算、存储和内存方面的优越效率。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









