








 超级会员免费看
超级会员免费看

本文也是LLM相关的综述文章,针对《Aligning Large Language Models with Human: A Survey》的翻译。
对齐人类与大语言模型:综述
摘要
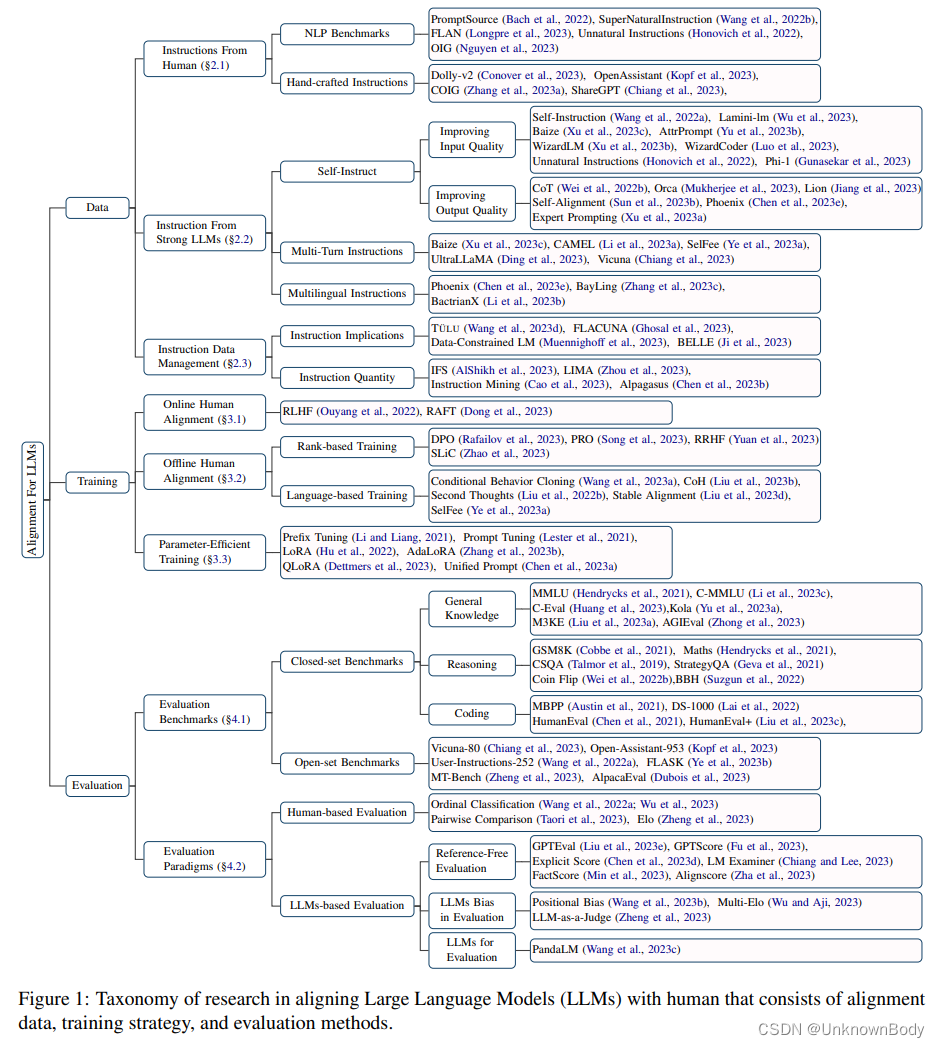
在大量文本语料库上训练的大型语言模型(LLM)已成为一系列自然语言处理(NLP)任务的领先解决方案。尽管这些模型具有显著的性能,但它们容易受到某些限制,如误解人类指令、生成潜在的偏见内容或事实上不正确(产生幻觉)的信息。因此,将LLM与人类期望相结合已成为研究界关注的一个活跃领域。本调查全面概述了这些对齐技术,包括以下方面。(1) 数据收集:有效收集LLM对齐的高质量指令的方法,包括使用NLP基准、人工注释和利用强大的LLM。(2) 训练方法:详细审查LLM调整所采用的主流训练方法。我们的探索包括监督微调,在线和离线人类偏好训练,以及参数有效的训练机制。(3) 模型评估:评估这些与人类一致的LLM有效性的方法,为其评估提供了多方面的方法。最后,我们整理和提炼了我们的发现,为该领域未来的几个有前景的研究途径提供了线索。因此,对于任何致力于理解和推进LLM调整以更好地适应以人为本的任务和期望的人来说,这项调查都是一项宝贵的资源。收集最新论文的相关GitHub链接可在https://github.com/GaryYufei/AlignLLMHhumanSurvey。
1 引言

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 208
208











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











