








 超级会员免费看
超级会员免费看

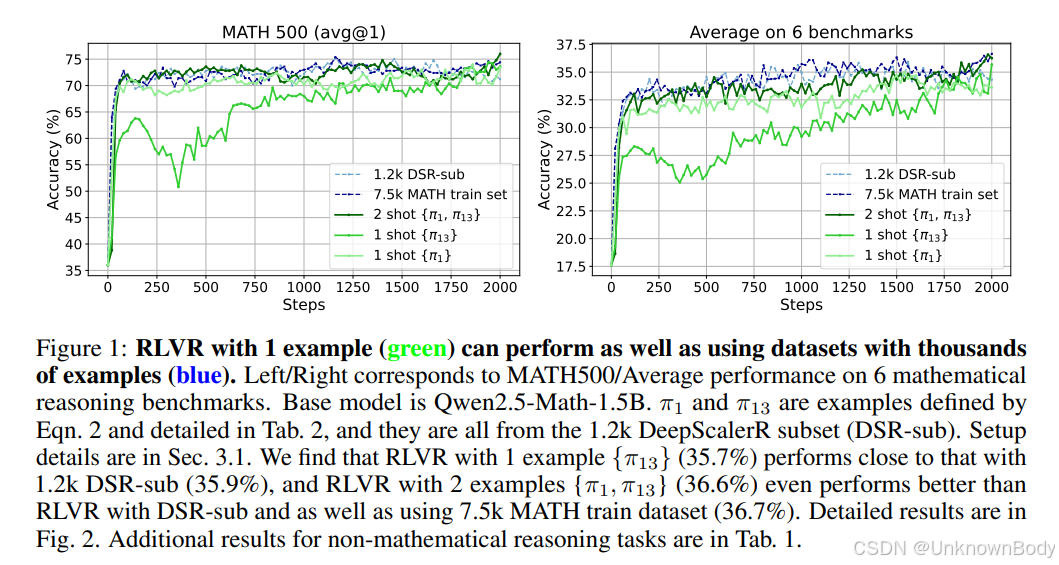
主要内容
- 研究背景:强化学习与可验证奖励(RLVR)在提升大语言模型(LLMs)推理能力方面取得显著进展,但RLVR数据方面的研究相对不足,如训练数据的数量、质量和有效性等问题有待探索。
- 研究方法
- 采用GRPO作为强化学习算法,其损失函数包含策略梯度损失、KL散度损失和熵损失。
- 提出基于历史方差分数的数据选择方法,通过训练模型获取每个示例的历史训练准确率列表,按其方差对数据进行排序。
- 实验设置
- 模型:以Qwen2.5 - Math - 1.5B为主进行实验,并验证了Qwen2.5 - Math - 7B、Llama - 3.2 - 3B - Instruct和DeepSeek - R1 - Distill - Qwen - 1.5B等模型。
- 数据集:从DeepScaleR - Preview - Dataset中随机选取1209个示例作为数据选择的实例池(DSR - sub),并使用MATH训练集进行对比。
- 训练与评估:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











