








 超级会员免费看
超级会员免费看

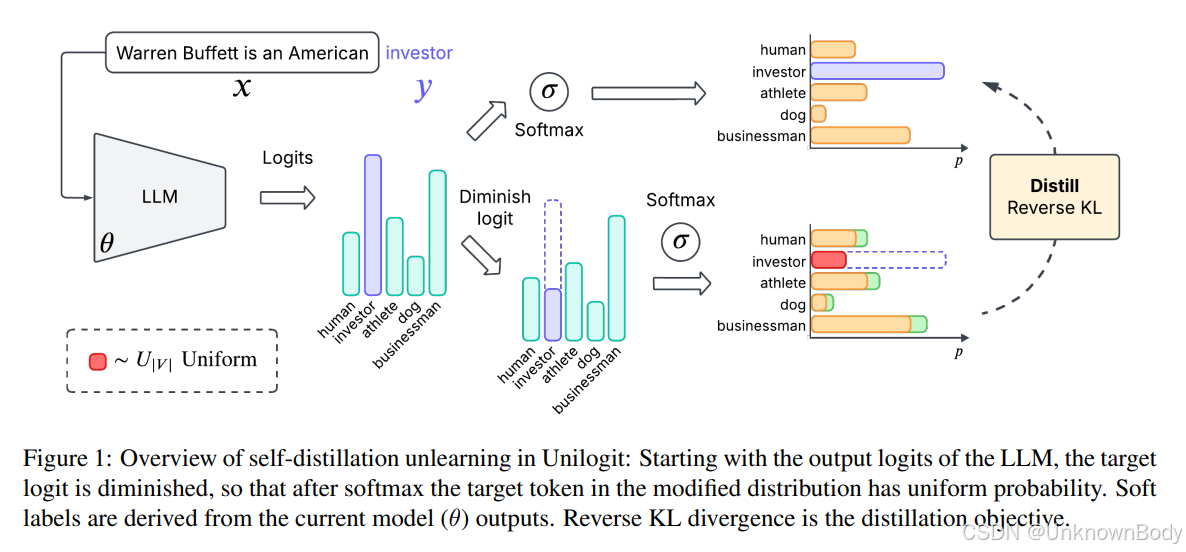
一、文章主要内容总结
本文聚焦于大语言模型(LLMs)的机器遗忘(Machine Unlearning)领域,提出了一种名为Unilogit的自蒸馏方法,旨在解决模型在选择性遗忘敏感信息的同时保持整体性能的挑战,以满足数据隐私法规(如GDPR)的要求。
1. 核心方法
- 动态均匀目标自蒸馏:通过调整目标对数几率(logits),使目标标记的概率在软最大化(softmax)后变为均匀分布(uniform probability),并利用当前模型的输出生成更准确的软标签(soft labels)。
- 反向KL散度损失:采用反向KL散度(Reverse KL divergence)作为遗忘损失函数,抑制模型对遗忘信息的高置信度预测,同时通过保留损失(retain loss)维持模型在保留数据上的性能。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











