







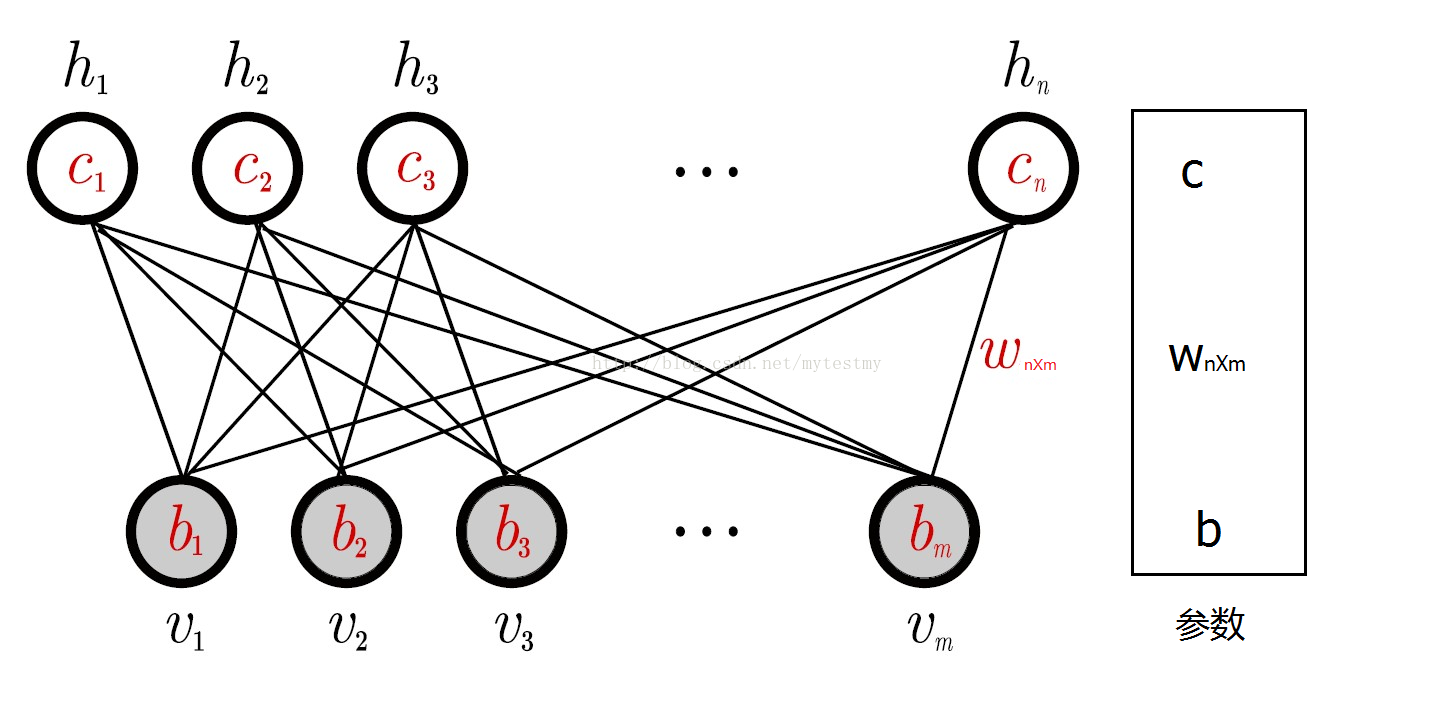
 本文介绍了hulu公司如何使用RBM(受限玻尔兹曼机)和NADE(神经自回归分布估计算法)进行协同过滤,特别是在电影推荐中的应用。内容涵盖了RBM的能量函数、似然函数、对比散度训练,以及NADE的可见层分布和参数更新。RBM-CF结合用户评分和观看历史,提高推荐准确性。
本文介绍了hulu公司如何使用RBM(受限玻尔兹曼机)和NADE(神经自回归分布估计算法)进行协同过滤,特别是在电影推荐中的应用。内容涵盖了RBM的能量函数、似然函数、对比散度训练,以及NADE的可见层分布和参数更新。RBM-CF结合用户评分和观看历史,提高推荐准确性。
RBM and NADE TO Collaborative Filtering
最近在看深度学习在推荐算法上应用,本篇是hulu公司同事的ICML的文章A Neural Autoregressive Approach to Collaborative Filtering,介绍了利用NADE进行电影推荐的方法,在NETFX的数据集上取得了不错的结果,本文主要是学习和记录笔记,学习NADE-CF,并记录所涉及的一些算法,供后续查看方便。
RBM
RBM主要参考受限波尔兹曼机简介-张春霞,同时也参考核复制了博客的很多内容 深度学习读书笔记之RBM(限制波尔兹曼机)。在这里主要简介RBM涉及的几个计算公式,方便后边实现的理解。
能量函数
能量函数。随机神经网络是根植于统计力学的。受统计力学中能量泛函的启发,引入了能量函数。能量函数是描述整个系统状态的一种测度。系统越有序或者概率分布越集中,系统的能量越小。反之,系统越无序或者概率分布越趋于均匀分布,则系统的能量越大。能量函数的最小值,对应于系统的最稳定状态。
E(v,h|θ)=−∑i=0naivi−∑j=0mbjhj−∑i=0n∑j=0mviWijhj
其中, ai 和 bj 为偏置, vi 为可见层, hj 为隐藏层。
似然函数
有了能量函数,定义可视节点和隐藏层的联合概率分布。
p(v,h|θ)=e−E(v,h|θ)Z(θ),
Z(θ)=∑v,he−E(v,h|θ)
由联合概率可以得到观测数据 v 的概率分布
p(v|θ)=−1Z(θ)∑he−E(v,h|θ)
同理,可以获得每个节点的激发函数,RBN层内节点不连接,同一层各节点独立分布。
p(vi=1|h,θ)=σ(ai+∑jhjWij)
p(hi=1|v,θ)=σ(bi+∑iviWij)
对比散度RBM参数训练
学习RBM的任务是求出参数 θ 的值, 以拟合给定的训练数据。 参数 θ 可以通过最大
化RBM在训练集昨假设包含T个样本昩上的对数似然函数学习得到, 即
Θ∗=argmaxθ(ξ(θ))=argmaxθ∑t=1Tlogp(vt|θ)
Hiton提出了RBM的一个快速学习算法, 即对比散度(Contrastive Divergence)。与吉布斯采样不同, CD指出当使用训练数据初始化 v0 时, 我们仅需要使用k步吉布斯采样便可以得到足够好的近似。在CD算法一开始, 可见单元的状态被设置成一个训练样本,并利用式 p(h|v,θ) 计算所有隐层单元的二值状态。在所有隐层单元的状态确定之后,来确定第i个可见单元 vi 取值为1的概率,进而产生可见层的一个重构。
- 输入:一个训练样本 m0 ,隐层单元个数 m ,学习率$$,最大训练周期$T$.
- 输出:连接权重矩阵W、可见层的偏置向量a、隐层的偏置向量b.
- 训练阶段:
- 初始化可见层单元的初始状态
v1=x0;Wa 和b为随机的较小数值。 - For t=1,2…T
- For j=1,2..m(对所有隐层单元)
- 计算隐层节点分布 p(h1j=1|v1) , p(h1j=1|v1)=σ(
- 初始化可见层单元的初始状态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1834
1834

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









