








本博客根据 许利杰前前辈发送的文档的基础上进行修改和扩展,特此感谢许前辈的帮助,谢谢!
线性回归
线性回归假设每个输入都被当做一个特征数据,每个特征至少有一个未知的参数与其对应,特征和结果满足线性关系。其实线性关系的表达能力非常强大,每个特征对结果的影响强弱可以有前面的参数体现,而且每个特征变量可以首先映射到一个函数,然后再参与线性计算。这样就可以表达特征与结果之间的非线性关系。
我们用X1,X2..Xn 去描述feature里面的分量,比如x1=房间的面积,x2=房间的朝向,等等。
我们可以做出一个估计函数:
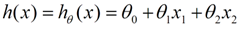
θ在这儿称为参数,在这的意思是调整feature中每个分量的影响力,就是到底是房屋的面积更重要还是房屋的地段更重要。如果我们令X0 = 1,就可以用向量的方式来表示了:
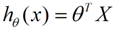
我们程序也需要一个机制去评估我们θ是否比较好,所以说需要对我们做出的h函数进行评估,一般这个函数称为损失函数(loss function)或者错误函数(error function),描述h函数不好的程度,在下面,我们称这个函数为J函数
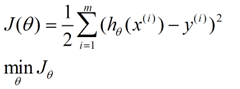
这个错误估计函数是去对x(i)的估计值与真实值y(i)差的平方和作为错误估计函数,前面乘上的1/2是为了在求导的时候,这个系数就不见了。
至于为何选择平方和作为错误估计函数,讲义后面从概率分布的角度讲解了该公式的来源。
如何调整θ以使得J(θ)取得最小值有很多方法,其中有最小二乘法(min square)(是一种完全是数学描述的方法)和梯度下降法。
局部加权线性回归
基本假设是
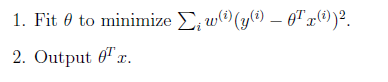
其中假设w^((i))符合公式
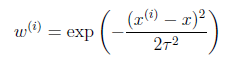
其中x是要预测的特征,这样假设的道理是离x越近的样本权重越大,越远的影响越小。这个公式与高斯分布类似,但不一样,因为w^((i))不是随机变量。
此方法称为非参数学习算法,因为误差函数随着预测值的不同而不同,这样θ无法事先确定,每一次预测 都需要临时计算,感觉类似KNN。
Logistic回归
一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大。如果非要应用进入,可以使用Logistic回归。
Logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把特征线性求和,然后使用函数g(z)作为假设函数来预测。g(z)可以将连续值映射到0和1上。
Logistic回归的假设函数(即sigmiod函数)如下,线性回归假设函数只是θ^T x。
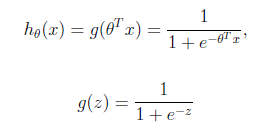
Logistic回归用来分类0/1问题,也就是预测结果属于0或者1的二值分类问题。这里假设了二值满足伯努利分布,也就是
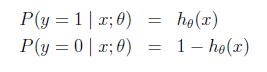
当然假设它满足泊松分布、指数分布等等也可以,只是比较复杂,后面会提到线性回归的一般形式。仍然求的是最大似然估计,然后求导,得到迭代公式结果为:
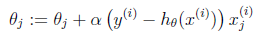
可以看到与线性回归类似,只是θ^T x^((i))换成了h_θ (x^((i) )),而h_θ (x^((i) ))实际上就是θ^T x^((i))经过g(z)映射过来的。
牛顿法来解最大似然估计
第7和第9节使用的解最大似然估计的方法都是求导迭代的方法,这里介绍了牛顿下降法,使结果能够快速的收敛。当要求解f(θ)=0时,如果f可导,那么可以通过迭代公式
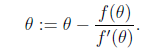
来迭代求解最小值。
当应用于求解最大似然估计的最大值时,变成求解L’ (θ)=0的问题。那么迭代公式如下:
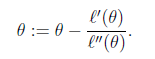
当θ是向量时,牛顿法可以使用下面式子表示
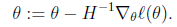
其中
是n×n的Hessian矩阵。
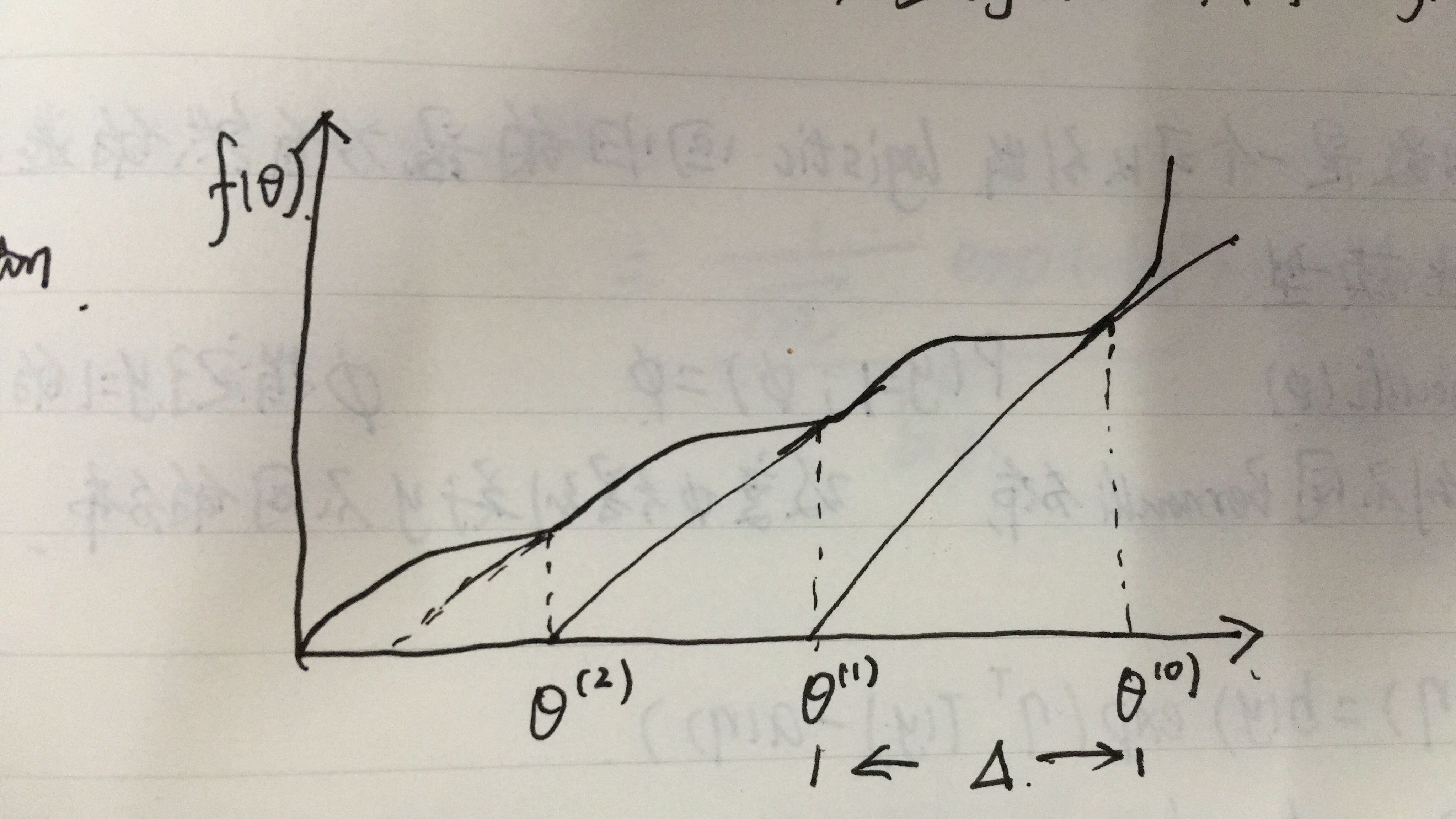
牛顿法收敛速度虽然很快,但求Hessian矩阵的逆的时候比较耗费时间。
当初始点X0靠近极小值X时,牛顿法的收敛速度是最快的。但是当X0远离极小值时,牛顿法可能不收敛,甚至连下降都保证不了。原因是迭代点Xk+1不一定是目标函数f在牛顿方向上的极小点。
手画图表示
这里贴一个机器学习实战中Logistic回归实现的Python代码。博主用的Anaconda2作为Python的实现方式,之前用了Python官网的软件,需要下载科学计算包,不方便,后来使用了Python(x,y),不知为何打不开,好像是作者已经不维护了。Anaconda2很好用,建议使用!
送上下载链接Anaconda2-2.4.0-Windows-x86_64.exe
'''
Created on Oct 27, 2010
Logistic Regression Working Module
@author: Peter
'''
from numpy import *
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #convert to NumPy matrix
labelMat = mat(classLabels).transpose() #convert to NumPy matrix
m,n = shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles): #heavy on matrix operations
h = sigmoid(dataMatrix*weights) #matrix mult
error = (labelMat - h) #vector subtraction
weights = weights + alpha * dataMatrix.transpose()* error #matrix mult
return weights
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
def colicTest():
frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print "the error rate of this test is: %f" % errorRate
return errorRate
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print "after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))
上面代码对应的文件夹下载链接
具体操作可百度一下。
一般线性回归
之所以在对数回归时使用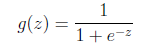
这个理论便是一般线性模型。
首先,如果一个概率分布可以表示成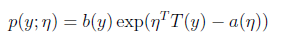
伯努利分布,高斯分布,泊松分布,贝塔分布,狄特里特分布都属于指数分布。
在Logistic回归时采用的是伯努利分布,伯努利分布的概率可以表示成
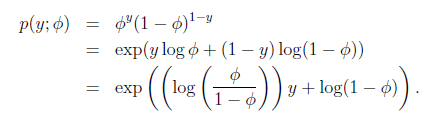
其中
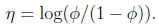
得到
Φ=1/(1+e^η )
这就解释了对数回归时为了要用这个函数。
一般线性模型的要点是
1.y|x; θ 满足一个以η为参数的指数分布,那么可以求得η的表达式。
2.给定x,我们的目标是要确定T(y),大多数情况下T(y)=y,那么我们实际上要确定的是h(x),而h(x)=E[y|x]。(在对数回归中期望值是Φ,因此h是Φ;在线性回归中期望值是μ,而高斯分布中η=μ,因此线性回归中h=θ^T x)。
3.η=θ^T x
Softmax回归
Softmax回归属于一般线性回归的一种,也可以当做是对Logistic回归的扩展,在Logistic回归中,将所有的数据回归成0和1两类,而Softmax回归则将数据回归成0到K若干类。
假设预测值y有k种可能,即y∈{1,2,…,k},比如k=3时,可以看作是要将一封未知邮件分为垃圾邮件、个人邮件还是工作邮件这三类。
定义
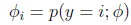
那么
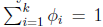
这样
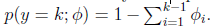
即式子左边可以有其他的概率表示,因此可以当做是k-1维的问题。
T(y)这时候一组k-1维的向量,不再是y。即T(y)要给出y=i(i从1到k-1)的概率
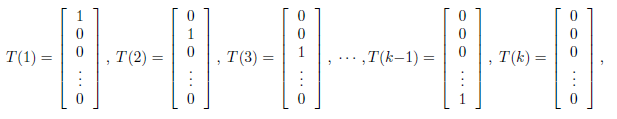
应用于一般线性模型
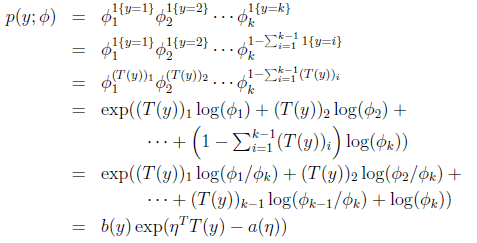
那么
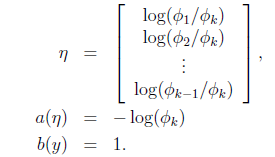
最后求得
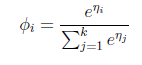
而y=i时
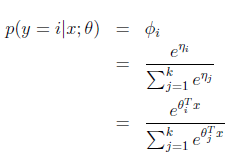
求得期望值

那么就建立了假设函数,最后就获得了最大似然估计
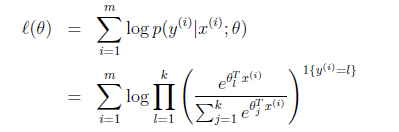
对该公式可以使用梯度下降或者牛顿法迭代求解。
解决了多值模型建立与预测问题。















 1182
1182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









