







摘抄“GPU Programming And Cg Language Primer 1rd Edition” 中文名“GPU编程与CG语言之阳春白雪下里巴人”第一章。
第1章 绪论
面纱掩盖了过去、现在和将来,历史学家的使命是发现它现在是什么,而不是过去是什么。
------Henry David Thoreau
1.1 Programmable Graphics Processing Unit发展历程
Programmable Graphics Processing Unit(GPU),即可编程图形处理单元,通常也称之为可编程图形硬件。GPU概念在20世纪70年代末和80年代初被提出,使用单片集成电路(monolithic)作为图形芯片,此时的GPU已经被用于视频游戏和动画方面,它能够很快地进行几张图片的合成(仅限于此)。在20世纪80年代末到90年代初这段时间内,基于数字信号处理芯片(digital signal processor chip)的GPU被研发出来,与前代相比速度更快、功能更强,当然价格是非常的昂贵。在1991年,S3 Graphics公司研制出第一个单芯片2D加速器,到了1995年,主流的PC图形芯片厂商都在自己的芯片上增加了对2D加速器的支持。与此同时,固定功能的视窗加速器(fixed-function Windows accelerators)由于其高昂的价格而慢慢退出PC市场。
1998年NVIDIA公司宣布modern GPU的研发成功,标志着GPU研发的历史性突破成为现实。通常将20世纪70年代末到1998年的这一段时间称之为pre-GPU时期,而自1998年往后的GPU称之为modern GPU。在pre-GPU时期,一些图形厂商,如SGI、Evans & Sutherland,都研发了各自的GPU,这些GPU在现在并没有被淘汰,依然在持续改进和被广泛的使用,当然价格也是非常的高昂。
modern GPU使用晶体管(transistors)进行计算,在微芯片(microchip)中,GPU所使用的晶体管已经远远超过CPU。例如,Intel在 2.4GHz的Pentium IV上使用5千5百万(55 million)个晶体管;而NVIDIA在GeForce FX GPU上使用超过1亿2千5百万(125 million)个晶体管,在NVIDDIA 7800 GXT上的晶体管达到3亿2百万(302 million)个。
回顾Modern GPU的发展历史,自1998年后可以分为4个阶段。NVIDIA于1998年宣布Modern GPU研发成功,这标志着第一代Modern GPU的诞生,第一代Modern GPU包括NVIDIA TNT2,ATI的Rage和3Dfx的Voodoo3。这些GPU可以独立于CPU进行像素缓存区的更新,并可以光栅化三角面片以及进行纹理操作,但是缺乏三维顶点的空间坐标变换能力,这意味着“必须依赖于GPU执行顶点坐标变换的计算”。这一时期的GPU功能非常有限,只能用于纹理组合的数学计算或者像素颜色值的计算。
从1999到2000年,是第二代modern GPU的发展时期。这一时期的GPU可以进行三维坐标转换和光照计算(3D Object Transformation and Lighting, T&L),并且OpenGL和DirectX7都提供了开发接口,支持应用程序使用基于硬件的坐标变换。这是一个非常重要的时期,在此之前只有高级工作站(workstation)的图形硬件才支持快速的顶点变换。同时,这一阶段的GPU对于纹理的操作也扩展到了立方体纹理(cube map)。NVIDIA的GeForce256,GeForce MAX,ATI的Radeon 7500等都是在这一阶段研发的。
2001年是第三代modern GPU的发展时期,这一时期研发的GPU提供vertex programmability(顶点编程能力),如GeForce 3,GeForce 4Ti,ATI的8500等。这些GPU允许应用程序指定一个序列的指令进行顶点操作控制(GPU编程的本质!),这同样是一个具有开创意义的时期,这一时期确立的GPU编程思想一直延续到2009年的今天,不但深入到工程领域帮助改善人类日常生活(医疗、地质勘探、游戏、电影等),而且开创或延伸了计算机科学的诸多研究领域(体绘制、光照模拟、人群动画、通用计算等)。同时,Direct8和OpenGL都本着与时俱进的精神,提供了支持vertex programmability的扩展。不过,这一时期的GPU还不支持像素级的编程能力,即fragment programmability(片段编程能力),在第四代modern GPU时期,我们将迎来同时支持vertex programmability和fragment programmability的GPU。
第四代modern GPU的发展时期从2002年末到2003年。NVIDIA的GeForce FX和ATI Radeon 9700同时在市场的舞台上闪亮登场,这两种GPU都支持vertex programmability和fragment programmability。同时DirectX和OpenGL也扩展了自身的API,用以支持vertex programmability和fragment programmability。自2003年起,可编程图形硬件正式诞生,并且由于DirectX和OpenGL锲而不舍的追赶潮流,导致基于图形硬件的编程技术,简称GPU编程,也宣告诞生。恭喜GeForce和ATI的硬件研发人员,你们终于可以歇口气了,不用较着劲地出显卡了,同时也恭喜 DirectX和OpenGL的研发人员,你们也可以休息下了,不用斗鸡一般的工作了,最后恭喜广大工作在图形图像领域的程序员,你们可以继续学而不倦。
目前最新的可编程图形硬件已经具备了如下功能:
1. 支持vertex programmability和fragment programmability;
2. 支持IEEE32位浮点运算;
3. 支持4元向量,4阶矩阵计算;
4. 提供分支指令,支持循环控制语句;
5. 具有高带宽的内存传输能力(>27.1GB/s);
6. 支持1D、2D、3D纹理像素查询和使用,且速度极快;
7. 支持绘制到纹理功能(Render to Texture,RTT)。
关于GPU发展历史的相关数据参考了Feng Liu的“Platform Independent Real-time X3D Shaders and Their Applications in Bioinformatics Visualization”一文
1.2 GPU VS CPU
从上节阐述了GPU的发展历史,那么为什么在CPU之外要发展GPU?GPU的vertex programmability和fragment programmability究竟在何处有着怎样的优势?引用在文献【2】第6页的一段话为:
Modern GPUs implement a number of graphics primitive operations in a way that make running them much faster than drawing directly to the screen with the host CPU. They are efficient at manipulating and displaying computer graphics, and their highly parallel structure makes them more effective than typical CPUs for a range of complex algorithms.
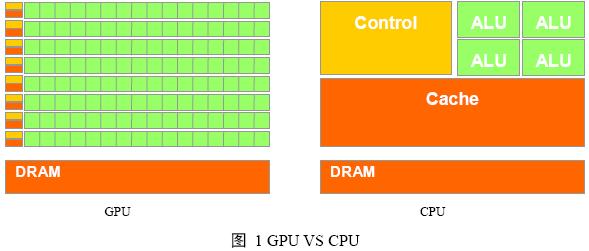
这段话的意思是,由于GPU具有高并行结构(highly parallel structure),所以GPU在处理图形数据和复杂算法方面拥有比CPU更高的效率。图 1 GPU VS CPU展示了GPU和CPU在结构上的差异,CPU大部分面积为控制器和寄存器,与之相比,GPU拥有更多的ALU(Arithmetic Logic Unit,逻辑运算单元)用于数据处理,而非数据高速缓存和流控制,这样的结构适合对密集型数据进行并行处理。CPU执行计算任务时,一个时刻只处理一个数据,不存在真正意义上的并行(请回忆OS教程上的时间片轮转算法),而GPU具有多个处理器核,在一个时刻可以并行处理多个数据。
GPU采用流式并行计算模式,可对每个数据进行独立的并行计算,所谓“对数据进行独立计算”,即,流内任意元素的计算不依赖于其它同类型数据,例如,计算一个顶点的世界位置坐标,不依赖于其他顶点的位置。而所谓“并行计算”是指“多个数据可以同时被使用,多个数据并行运算的时间和1个数据单独执行的时间是一样的”。图 2中代码目的是提取2D图像上每个像素点的颜色值,在CPU上运算的C++代码通过循环语句依次遍历像素;而在GPU上,则只需要一条语句就足够。

可能有人会问道:既然GPU在数据处理速度方面远胜CPU,为什么不用GPU完全取代CPU呢?实际上,关于GPU取代CPU的论调时有出现,但是作者本人并不同意这种观点,因为GPU在许多方面与CPU相比尚有不如。
首先,虽然GPU采用数据并行处理方式极大加快了运算速度,但正是由于“任意一个元素的计算不依赖于其它同类型数据”,导致“需要知道数据之间相关性的” 算法,在GPU上难以得到实现(但在CPU上则可以方便的实现),一个典型的例子是射线与不规则物体的求交运算。
此外,GPU在控制流方面弱于CPU,在图中可以看到,GPU中的控制器少于CPU,而控制器的主要功能是取指令,并指出下一条指令在内存中的位置,控制和协调计算机的各个部件有条不紊地工作。 在早期的OpenGL fp2.0,fp3.0以及DirectX的ps_4_0之前的pro
最后进行GPU编程必须掌握计算机图像学相关知识,以及图形处理API,入门门槛较高,学习周期较长,尤其国内关于GPU编程的资料较为匮乏,这些都导致了学习的难度。在早期,GPU编程只能使用汇编语言,开发难度高、效率低,不过,随着高级Shader language的兴起,在GPU上编程已经容易多了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









