







切片的基本操作
切片的语法:
l = list(range(5)) # l = [0, 1, 2, 3, 4]
l[start:end:step]
从 start 开始(包含),到 end 结束(不包含),步长为 step。
- 步长为1时,可以省略不写:
l[start:end] - 表示从头开始时,
start可以省略:l[:end:step] - 表示持续到末尾时,
end可以省略:l[start::step] - 三者均省略,写成:
l[::](简写为l[:])它表示取l中所有元素。
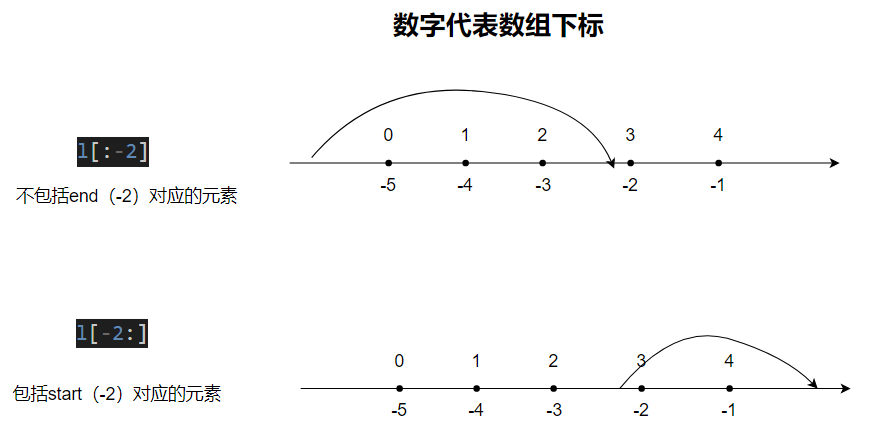
另外,可以用 -1 表示列表中最后一个元素,-2 表示倒数第二个,依次类推。
l[:-2] # everything except the last two items
l[-2:] # last two items in the array
图示:
步长为负数
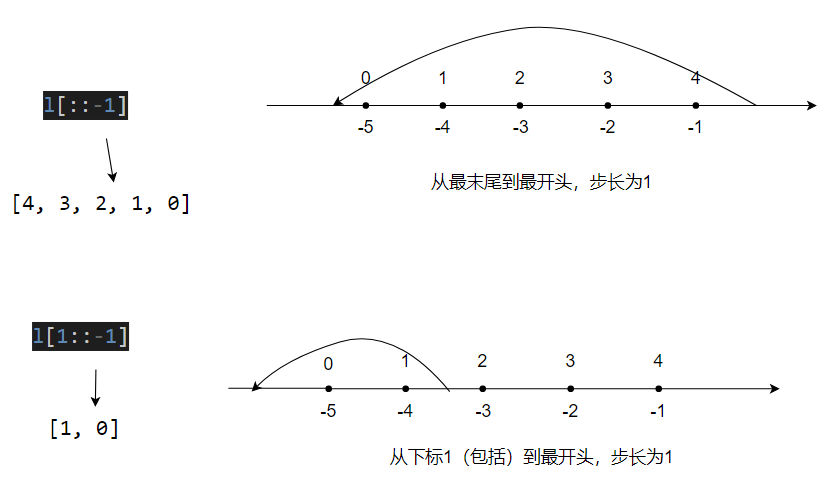
Understanding slicing:当步长为负数时,元素会以倒着的顺序被取出来 (in a reversed order)。
如果说步长为正数时,start 默认为列表/数组的最开头,end 默认为列表/数组的最末尾;那么步长为负数时恰好反过来:start 默认为列表/数组的最末尾,end 默认为列表/数组的最开头。
l[::-1] # all items in the array, reversed
l[1::-1] # the first two items, reversed
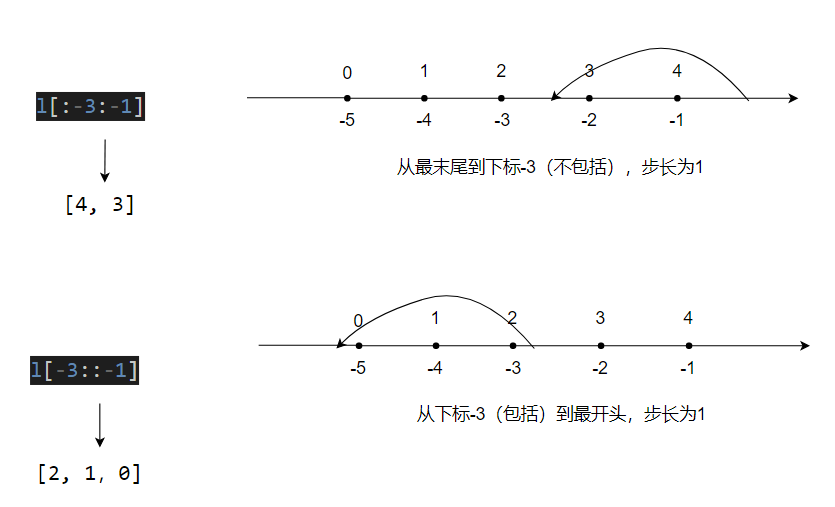
l[:-3:-1] # the last two items, reversed
l[-3::-1] # everything except the last two items, reversed
list 和 np.array 的切片基本语法是一样的,不过它们有不同的表现。
list 的切片表现
先说结论,list 的切片,
- 对“属于不可变对象的子元素”的修改,不会影响另一对象;
- 对“属于可变对象的子元素”的修改,会影响另一对象。
Rappel: 可变对象有:
list,dictionary,set; 不可变对象有:int,float,bool,string,tuple
举个例子:
l_a = [[0], 1, 2, 3, 4,]
l_b = l_a[:4]
print(f"l_b: {l_b}")
# 对 l_b[0] 的修改,会同时改变 l_a[0],因为 l_a[0] 是一个 list,是可变对象
l_b[0].append(8)
print(f"l_a: {l_a}")
# 同样, 对 l_a[0] 的修改,也会同时改变 l_b[0]
l_a[0].append(10)
print(f"l_b: {l_b}")
打印结果:
l_b: [[0], 1, 2, 3]
l_a: [[0, 8], 1, 2, 3, 4]
l_b: [[0, 8, 10], 1, 2, 3]
对不可变对象的修改,则不会互相影响:
l_a = [[0], 1, 2, 3, 4,]
l_b = l_a[:4]
print(f"l_b before: {l_b}")
l_b[1] = 9
print(f"l_b after: {l_b}")
print(f"l_a: {l_a}")
打印结果:
l_b before: [[0], 1, 2, 3]
l_b after: [[0], 9, 2, 3]
l_a: [[0], 1, 2, 3, 4] # l_a[1] 并没有变化
所以,list 的切片操作中,两个对象的依赖程度,和Python的浅拷贝 (copy.copy) 是一样的。
np.array 的切片表现
在说结论之前,先看一下 np.array的三种“复制”:
- 直接赋值
b = a。 这时a和b是一个东西,指向同一块内存地址。 - 创建
view:b = a.view()会创建a的一个view;它们的内存地址不相同,但数据是互通的,数据的修改会互相影响。切片操作会创建view:Views versus copies in NumPy
As its name is saying, it is simply another way of viewing the data of the array. Technically, that means that the data of both objects is shared. You can create views by selecting a slice of the original array, or also by changing the dtype (or a combination of both). These different kinds of views are described below.
- 创建
copy:b = a.copy()相当于深拷贝,它们的内存地址不相同,数据也不互通。
前面提到,切片操作会创建view,因此切片得到的新数组和原数组会相互影响。但是还有一点要注意,对数组进行加、减、乘、除等运算,得到的结果是一个新的对象,它和原来的数组互不影响。
例子:
import numpy as np
a = np.array([1,2,3])
b = a[:]
# b = b + 1
b[2] = 9
print(f"a: {a}")
print(f"b: {b}")
b是 a 的切片,所以更改 b 会相应地更改 a,上面代码的运行结果为:
a: [1 2 9]
b: [1 2 9]
再来看另一段代码:
a = np.array([1,2,3])
b = a[:]
b = b + 1
b[2] = 9
print(f"a: {a}")
print(f"b: {b}")
b=b+1 :将 b 里面的每一个元素加1,此时Python创建了一个新的对象,并将新的对象赋值给 b。所以现在的 b 和 a 已经完全没有关系了,更改 b 不会对 a 产生影响。上面程序的结果为:
a: [1 2 3]
b: [2 3 9]
如果你觉得明白了,稍等,再看一段程序:
a = np.array([1,2,3])
b = a[:]
b += 1
b[2] = 9
print(f"a: {a}")
print(f"b: {b}")
这段程序将 b=b+1 替换成了 b+=1,它们的效果都是将 b 里面的每一个元素加1。但此时程序的输出结果变成了 :
a: [2 3 9]
b: [2 3 9]
这是怎么回事呢?
这就要提到 i += x 和 i = i + x 的区别了:When is “i += x” different from “i = i + x” in Python?
这两个操作对于不可变对象来说,效果是一样的,都会返回一个新的对象。
但对于可变对象来说(比如这里的 np.array 和 list),i += x 会在原来的对象上做修改,不会生成新的对象;而 i = i + x 先产生了一个新的对象 i + x, 然后把这个对象赋值给了 i 。
所以我们就能理解,为什么 b += 1 的操作之后, b 和 a 依然能相互影响,因为 b += 1 没有创建新的对象。
判断 view 和 copy
要判断一个数组究竟是 view 还是 copy,可以检查它的 .base 的属性:numpy.ndarray.base
x = np.array([1,2,3,4])
x.base is None
>>> True
y = x[2:]
y.base is x
>>> True
当一个数组的 .base 为 None 时,它就是一个 copy;反之,它就是一个 view, .base 属性会显示该数组共享数据的“母数组”。
fancy indexing
fancy indexing 允许我们以连续或不连续的方式取出数组中的元素,就像这样:b = a[[1]]。fancy indexing 会创建一个新的对象,它和原对象互不影响。
注意: list 不支持 fancy indexing。
看一个例子加深理解:
a = np.array([1,2,3])
b = a[[1]]
b[0] = 4
print(f"a: {a}")
print(f"b: {b}")
>>> a: [1 2 3]
>>> b: [4]
a = np.array([1,2,3])
b = a[1:2]
b[0] = 4
print(f"a: {a}")
print(f"b: {b}")
>>> a: [1 4 3]
>>> b: [4]
尽管 a[[1]] 和 a[1:2] 拿到的元素是一样的,但是它们的实现大不一样。前者创建了一个新的对象(copy);后者创建了一个 view
结论
- 对
list切片,结果中的不可变对象与原来的list互不影响;结果中的可变对象与原来的list共享数据。 - 对
np.array切片,结果与原来的np.array共享数据,互相影响。 - 在
np.array基础上的四则运算会建立一个新的对象,独立于原对象。要注意i += x和i = i + x的区别 - Fancy indexing 会创建新的对象,独立于原对象;
list不支持 fancy indexing















 273
273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









