






DARPA(美国国防高级研究计划局)于2015年制定了可解释人工智能(eXplainable Artificial Intelligence,XAI)计划。XAI项目旨在推动可解释人工智能的研究和发展,使人类用户能够理解和信任人工智能系统的决策过程,提高人工智能系统的透明度和可信度。该项目的研究方向包括解释性技术的开发、解释的生成、解释的评估和验证、用户界面和人机交互设计、以及应用领域研究等。目前,DARPA的XAI项目已经结束,本文对XAI项目的目标、研究进展以及经验予以总结。
1
项目背景
近年来,以深度神经网络为代表的人工智能技术飞速发展,在计算机视觉、自然语言处理和强化学习领域都取得了显著成就,持续的进步有望产生能够感知、学习、决策和行动的自主系统。尽管这些系统为人们带来了巨大的便利,但他们的有效性受到机器无法向人类用户解释其决策和行动的原因的限制,因而常常被视为是“黑箱模型”。
可解释人工智能(eXplainable AI,XAI)则致力于打开这些“黑箱模型”,理解模型的构建过程与推理机制,实现模型透明化。对于某些人工智能应用来说,解释可能不是必要的;但是对于国防、医学、金融、法律等领域的人工智能应用来说,解释对于用户理解、信任和有效管理这些人工智能合作伙伴是至关重要的。XAI的目的是通过提供解释使其行动更容易被人类理解,旨在解释系统如何产生其输出。有一些通用的原则可以帮助创建有效的更容易被人类理解的人工智能系统,例如XAI系统应该能够解释他的能力和理解;解释它做了什么,现在做什么,接下来会发生什么;揭示他它的作用等重要信息[1]。
从某种意义上来说,可解释性的问题是人工智能发展的结果。在人工智能发展的早期,主要的推理方法是基于逻辑和符号,因此其产生的推理步骤能够成为可解释AI的基础,也有大量研究对这些系统的可解释性做了研究。然而,早期的AI系统对于复杂世界的预测大多是低效的。最近AI的成功很大程度上归功于机器学习技术的发展,其中包括支持向量机、随机森林、强化学习和深度学习神经网络等。这些模型表现出高性能的预测效果,但是他们是不透明的黑箱模型。因此,性能和可解释性似乎存在着相互制约的关系(如图1):通常情况下性能最高的方法(例如深度学习)是最不可解释的,而可解释性最高的方法(例如决策树)却是最不准确的。
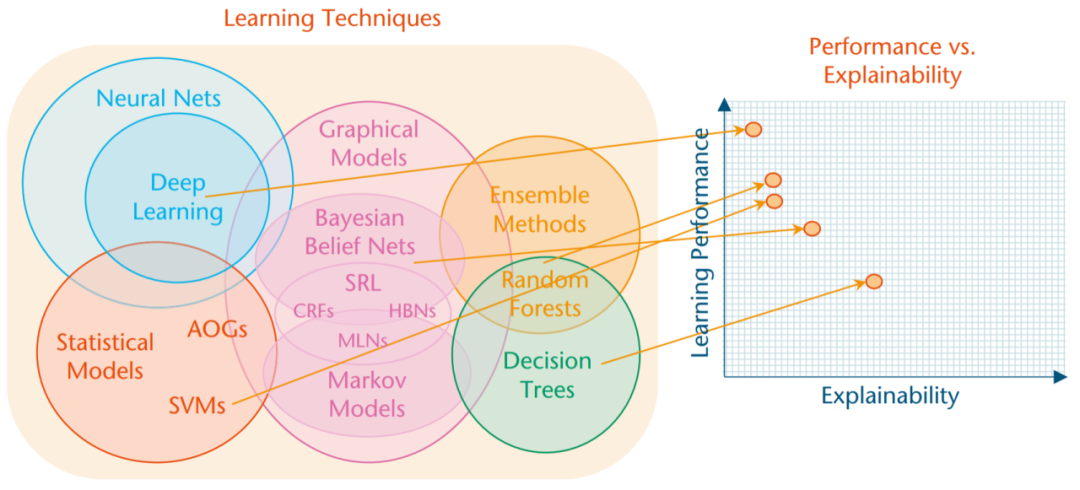
图 1 模型性能与可解释性的权衡
2015年是对于XAI需求的转折点。一方面,数据分析和机器学习经历了十年的快速发展,并随着2012年ImageNet的突破性发展,深度学习带来了人工智能新发展。人们对于超级人工智能开展了激烈的讨论,希望理解这些看似神秘的人工智能系统。另一方面,2015年还出现了关于提供可解释性的初步想法:一些研究人员尝试探索深度学习技术,如使用反卷积网络来可视化卷积层;也有学者探索更多可解释AI的技术,如贝叶斯规则列表;其他学者将机器学习模型作为黑箱开展实验,以推导出近似可解释的模型,如LIME;还有学者使用心理学理论和人机交互理论来评估AI[2]。
在此背景下,DARPA的可解释人工智能(XAI)项目孕育而生。该计划致力于创建使最终用户能够更好理解和信任的人工智能系统,并有效地管理人工智能系统。为了实现这一目标,DARPA将研究重点落在学习更多可解释模型、设计更有效的解释界面和研究心理学理论。XAI项目与美国国防部推动采用的自助系统开发和部署的一套五项道德原则相适应:即负责任、公平、可追溯、可靠和可治理。
2
XAI项目概况
2.1. XAI项目的目标
XAI项目希望创建一套新的或修正的机器学习技术,产生可解释的模型。当与有效的解释相结合时,能够创建使最终用户理解、适当信任并有效管理的新一代AI系统。
DARPA将可解释人工智能定义为可以向人类用户解释其原理、描述其优势和劣势,并传达对其行为方式的理解的人工智能系统,也许还允许用户纠正系统的错误。将这一项目命名为XAI,反映了DARPA的目标,即通过使用有效的解释来创建更多人类可理解的人工智能系统;同时该项目借鉴了社会科学领域大量研究和专业知识,也反映了XAI团队对于人类解释心理学的兴趣。
XAI的目标群体是依赖AI系统产生的决策与建议,或采取行动的终端用户,例如,从大数据分析系统接受建议的情报分析师需要理解AI问什么推荐进一步调查某些活动;操作员让自动驾驶汽车在一条路线上行驶,就需要了解系统的决策模型,以便在未来的任务中适当地使用它。该项目假定机器学习的学习性能和可解释性之间存在着固有的矛盾。因此他希望创建一个新的机器学习和解释技术的组合,为未来的从业者提供更广泛的选择,涵盖更多可解释的选择空间。具体而言,如果一个应用程序需要更高的性能,那么XAI将提供含有更多解释的高性能的深度学习技术;如果需要更多的解释,那么XAI将提供可解释的较高性能的模型。
至于XAI所给出的解释,通常有如下几种分类方法。根据解释的范围可以分为局部解释和全局解释,局部解释提供对单个数据点(例如图像)的解释,而全局解释试图在数据集级别总结模型。根据解释的透明度,也可分为白盒解释和黑盒解释,这取决于解释所需的模型访问量。此外,除了事后解释,模型也可以本身就是可解释的[3]。
2.1 时间线
2015年,DARPA制定了可解释人工智能(XAI)计划,并历时一年时间调查研究人员,分析可能的研究策略,制定项目的目标和内容。2016年8月,DARPA发布了DARPA-BAA-16-53征求方案。
最初的项目计划包括两个阶段。第一阶段:技术演示(18个月),该阶段于2017年5月开始,开发人员针对其测试问题演示技术,即AI系统的初步技术演示。第二阶段:比较评估(30个月)。最初的计划是让开发人员针对政府评估人员定义的两个常见问题(数据分析和自治系统)之一(图2)测试他们的技术,但在项目开展过程中评估的问题并不局限于这两个问题。在第二阶段结束前,项目要求开发人员为开源的XAI工具包(XAITK)设计原型软件。
为了科学评估XAI技术的有效性,项目的研究人员设计并开展了用户研究。XAI项目共进行了三次评估,第一阶段进行了一次评估,第二阶段进行了两次评估。在用户研究中,大约有12700名参与者,其中大约有1900名有监督的参与者(个人由研究团队指导完成实验),有10800名无监督的参与者(个人自我指导完成实验,而非由研究团队指导)。根据美国国防部资助的人类受试者研究政策,每个研究方案均由当地机构审查委员会(IRB)审查[4]。
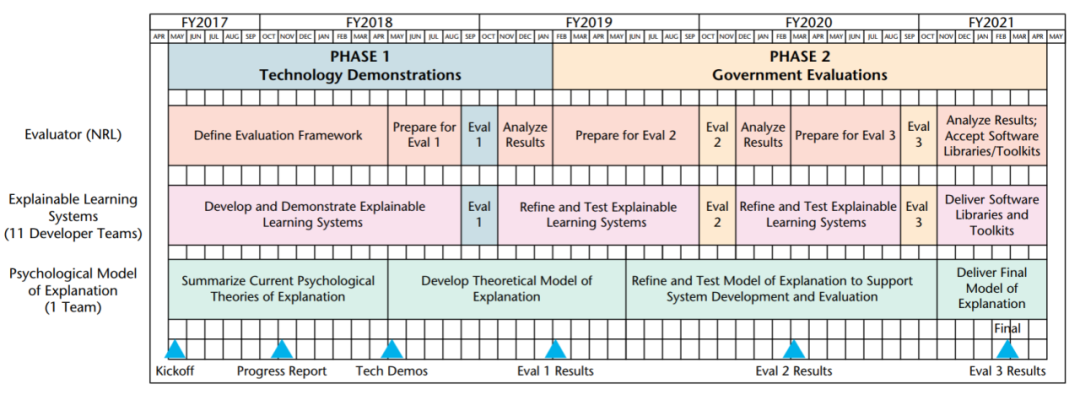
图 2 XAI项目时间表
2.2 XAI的三大技术领域
这种以用户为中心的概念也提出了相关的研究挑战:①如何产生更可解释的模型②如何设计解释界面③如何理解有效解释的心理需求。基于此,DARPA为XAI项目设计了三个主要的技术领域。如图3所示,技术1(TA1):开发新的XAI机器学习和解释技术,以生成有效的解释;技术2(TA2):通过总结、扩展和应用理论心理学来理解解释心理学;技术3(TA3):评估新的XAI技术在数据分析和自治两个挑战性问题的应用。
2017年5月,XAI项目开始。项目选择了11个研究小组来负责TA1,他们开发新的ML技术来产生可解释的模型,并使用新的原则、策略和人机交互HCI(例如可视化、语言理解、语言生成)来产生有效的解释;选择一个小组(IHMC)来开发可解释的心理学模型;评估则由海军研究实验室完成。下面将分别总结可解释AI项目各项工作的开展情况。
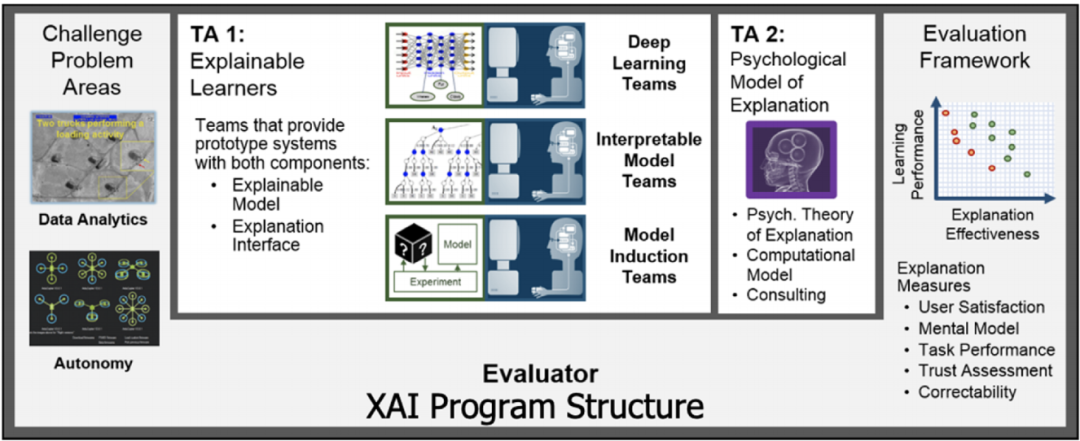
图 3 DARPA XAI 项目的架构
2.2.1 可解释模型
负责TA1模块的研究人员将检查训练过程、模型表示以及重要的解释界面(如图3)。对于模型表示,DARPA采用了三种策略在提升可解释性的同时保持高水平的学习性能:可解释模型、深度学习、模型推断。对于解释接口,DARPA希望其能成为XAI的关键元素,它将用户连接到模型,使得用户能够理解决策制定过程,并与之交互。
其中,深度学习模型是指利用深度学习或混合深度学习方法,通过学习更多可解释的特征或表示,或涵盖解释生成措施,来产生除预测之外的解释。一些模型设计可能会产生更可解释的表示,例如训练数据的选择、架构层、损失函数、正则化、优化技术、训练序列等。可解释模型是学习更结构化、可解释或因果模型的机器学习技术。早期的研究包括贝叶斯规则列表、贝叶斯程序学习、因果关系的学习模型,以及使用随机算法来学习更多可解释的结构。模型推断是指对任何给定的黑箱模型进行实验,从而推断出一个近似的可解释模型的技术。例如,Ribeiro等[5]的模型不可知解释系统通过观察和分析黑箱模型的输入-输出行为来推断解释。
11个TA1技术团队探索了许多机器学习方法,例如处理的概率模型、因果模型,以及解释技术,例如由强化学习算法生成的状态机、贝叶斯教学、视觉显著图[6][7]、以及网络和GAN解剖[8][9]。最具挑战和独特的贡献当属机器学习和解释技术的结合[10],并进行精心设计的心理学实验来评估解释的有效性[11]。随着项目的进展,研究团队也获得了对目标用户范围和开发时间线更精确的理解。
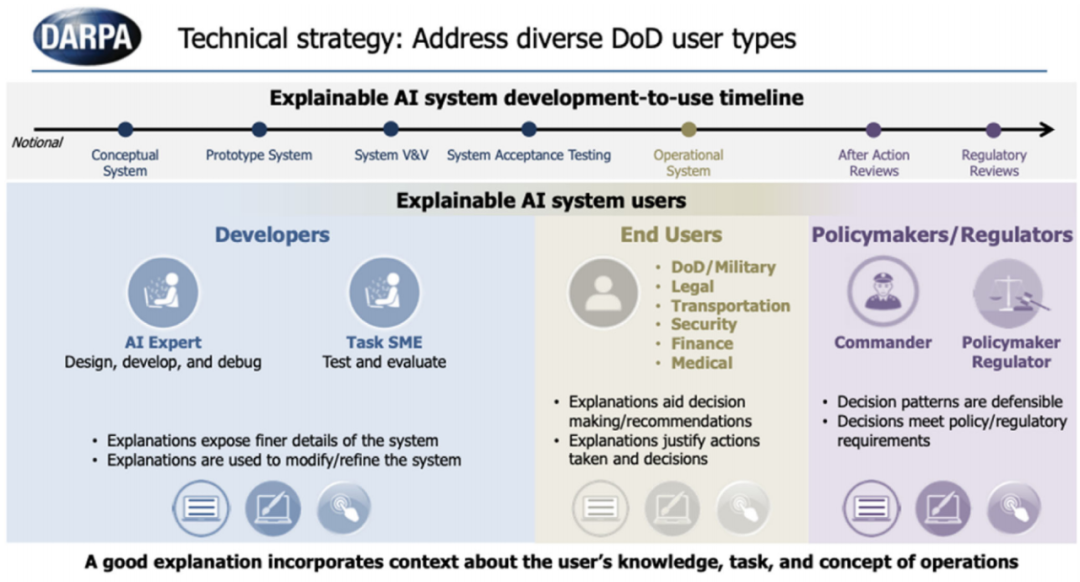
图 4 可解释的人工智能(XAI)的用户和开发时间线
2.2.2 解释心理学模型
一个研究小组(IHMC团队,包括来自MacroCognition和密歇根理工大学的研究人员)负责总结当前的心理学解释理论,以协助XAI开发人员和评估人员的工作。该团队的主要工作包括:对当前的解释理论进行总结、根据这些理论开发解释的计算模型、以及根据XAI开发人员的评估结果验证计算模型。尽管开发计算模型被认为是一个超前的工作,但是该团队通过回顾科学哲学和心理学专业的相关文献和分析大量案例,从中建立了评估解释好坏标准的模型。这些描述性模型对于支持建立有效的评估方法至关重要。评估方法涉及精心设计的研究,下图展示了IHMC团队建立的XAI解释过程的描述性模型,其中黄色框表示底层流程,绿色框表示度量维度,白色框表示潜在的结果。
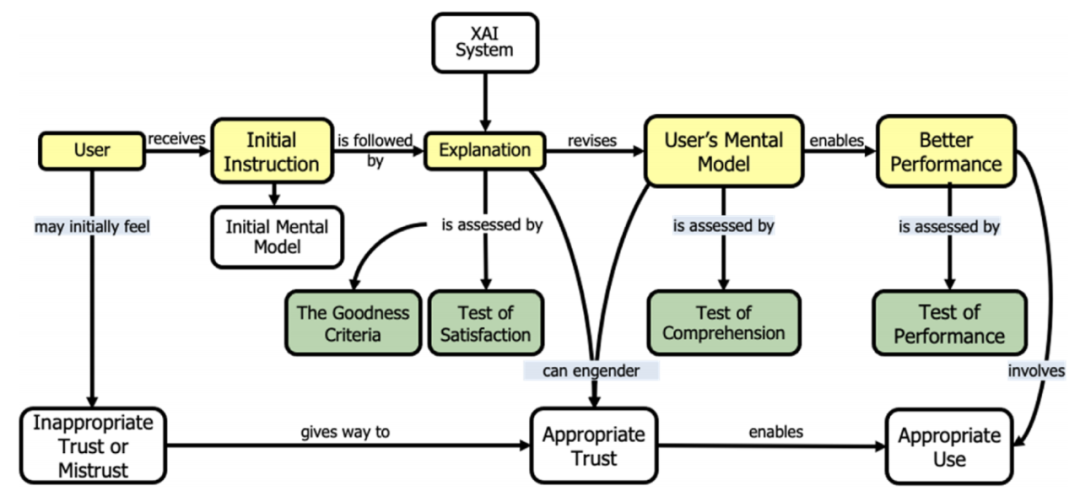
图 5 心理学解释模型
该心理学解释模型展示了评估解释有效性的度量类别,包括解释质量、用户心智模型和用户任务表现的度量方法,由此用户可以对何时信任或怀疑系统做出合理准确的判断。用户收到来自XAI系统的建议或决定,以及可以测试好坏和用户满意度的解释,通过用户对该解释的判断,有助于建立用户的心智模型。人工智能系统的建议和用户的心智模型可能会提高或降低用户的任务表现,这同样可以被衡量。经过上述过程,有助于用户对AI系统的形成适当(或不适当)的信任。XAI评估员使用这个模型来测试开发团队的XAI系统。
2.2.3 应用和评估
评估最初的设想是基于数据分析和自治领域内的一组常见问题。其中,数据分析是指对异构多模态数据中感兴趣的事件进行分类,自治是指自治系统和决策策略。这两个问题代表了两个重要的机器学习分类问题(监督学习和强化学习)和国防部的兴趣(情报分析和自主系统)。
数据分析源于一个常见的问题需求:情报分析师面临着来自大数据分析算法的决策和建议,并必须决定在分析中报告哪些作为支持依据,哪些需要进一步研究。这些算法经常产生假警告,受到概念混乱的影响;且这些算法通常会提出建议,分析师必须评估这些建议,以确定证据是否支持或反驳他们的假设。有效的解释将有助于解决这些问题。
自治挑战的动机源于有效管理人工智能合作伙伴。例如,国防部寻求半自主系统来增强作战人员的能力,使用者需要了解他们的行为方式,以便决定在未来的任务中在最好的时机使用它们。有效的解释也将促成这样的决策。
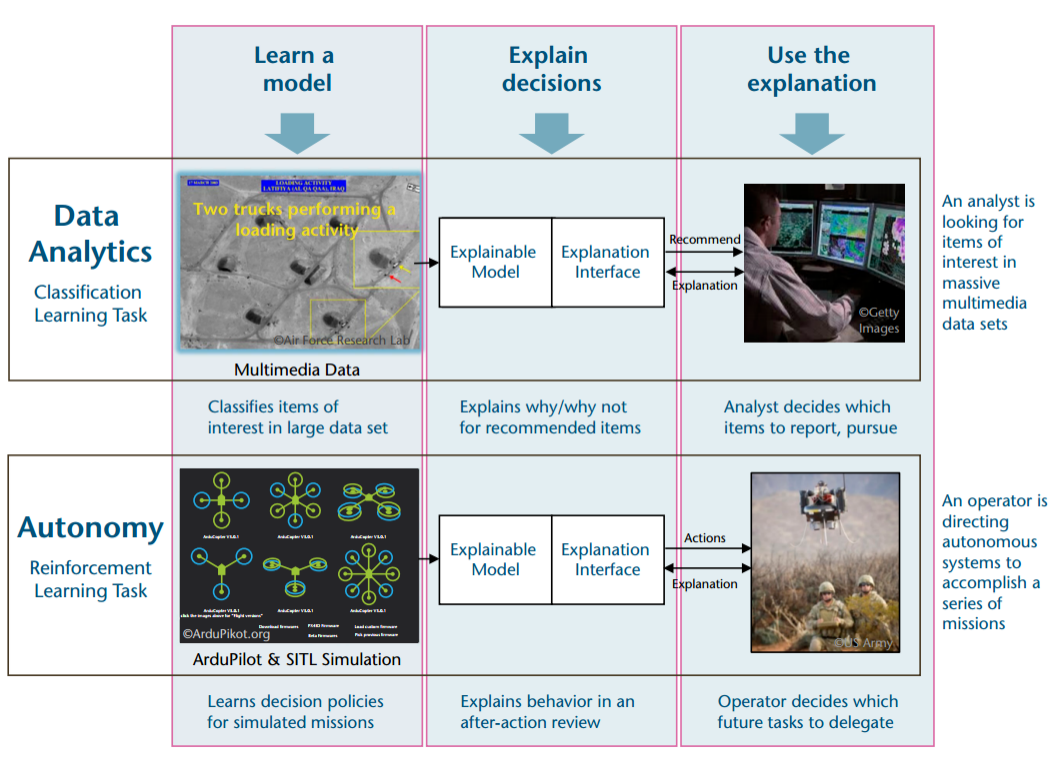
图 6 XAI两个挑战性领域
对于这两个挑战问题领域,衡量解释的有效性是至关重要的。虽然如果学习模型的可解释性可以自动测量,这将是很方便的,但是XAI系统的解释有效性必须根据其解释如何帮助人类用户来评估。这就需要用户心理实验来衡量用户的满意度、心智模型、任务表现和适当的信任。
但是在项目推进过程中,研究组发现在更广泛的领域中探索各种方法将更有价值。为了评估项目最后一年的表现,由美国海军研究实验室(NRL)的埃里克·沃姆博士领导的评估小组开发了一个解释评分系统(EES),该评分系统提供了一种定量的方法,用于评估XAI用户研究设计在技术和方法上的适当性和稳健性。ESS能够对每一个用户研究的多个要素进行评估,包括任务、领域、解释、解释界面、用户、假设、数据收集和分析,以确保每个研究符合人类被试研究的标准。XAI具体的评估指标如图所示,包括功能指标、学习性能指标和解释有效性指标。
EES解释评分系统能够为TA1团队设计和实施他们的评估实验。他们将在数据分析或自治的挑战问题领域中选择一个或多个测试问题,然后应用他们的新的机器学习技术,为他们的问题学习一个可解释的模型,并评估他们的机器学习模型的性能。将他们的学习模型与他们的解释界面结合起来,创建他们的可解释学习系统。随后进行实验,用户使用可解释的学习系统执行给定的任务,并采用IHMC的心理学解释过程模型(图5)和ESS解释评分系统(图7)来测量解释的有效性。
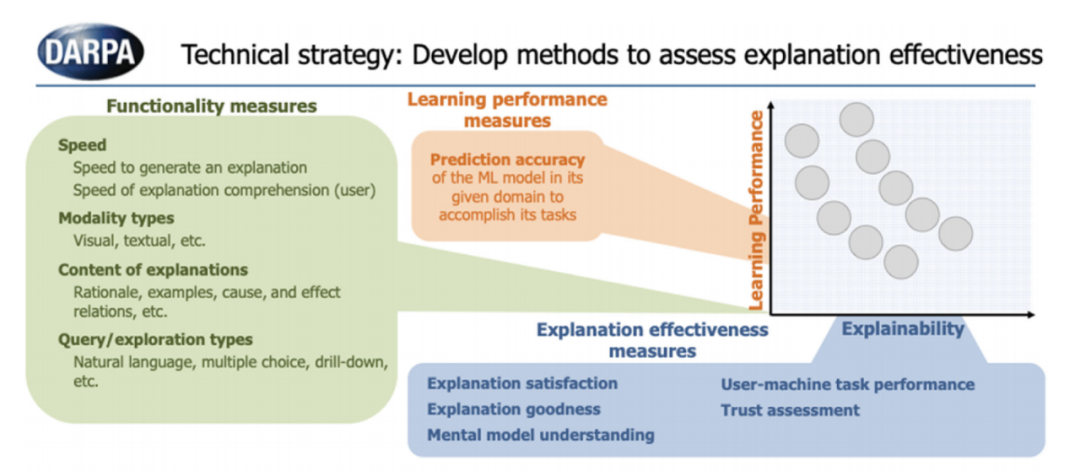
图 7 可解释人工智能(XAI)算法的评估体系
DARPA的XAI项目明确展示了精心设计用户研究的重要性,以便从增加人类用户的使用和信任等角度准确评估解释的有效性,并适当地支持人机合作。在研究过程中,DARPA发现最有效的研究团队是具有跨学科专业知识(计算机科学与人机交互或实验心理学等)的团队。
2.3 研究成果总结
2.3.1 TA1团队研究成果
按照前文所述的三个重点技术领域研究方向,由11个XAI技术领域TA1开发团队和TA2团队的研究结果。在11个TA1团队中,有三个TA1团队同时研究自治和数据分析,3个团队只研究自治,5个团队只研究数据分析。TA2团队则是来自弗罗里达人类和机器认知研究所IHMC负责开发解释的心理模型。下图展示了11个TA1团队和1个心里模型开发团队负责的研究方向。
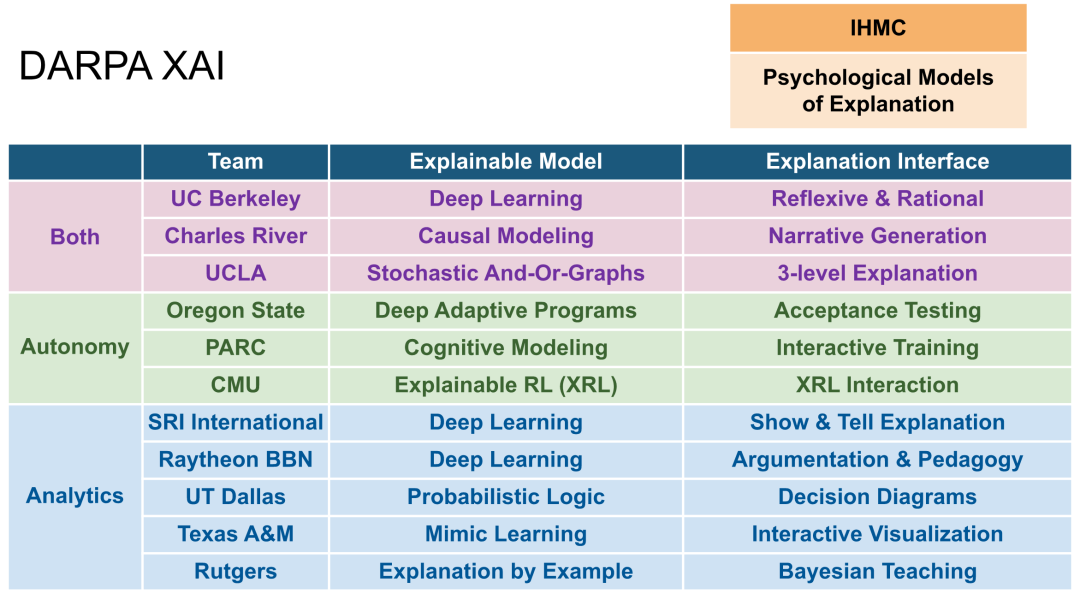
图 8 DARPA XAI研究团队与研究方向
下表总结了TA1团队研究开发可解释模型和解释接口的各种技术和成果,以及IHMC团队解释心理学模型的研究成果。
表 1 DARPA XAI 研究团队及其成果
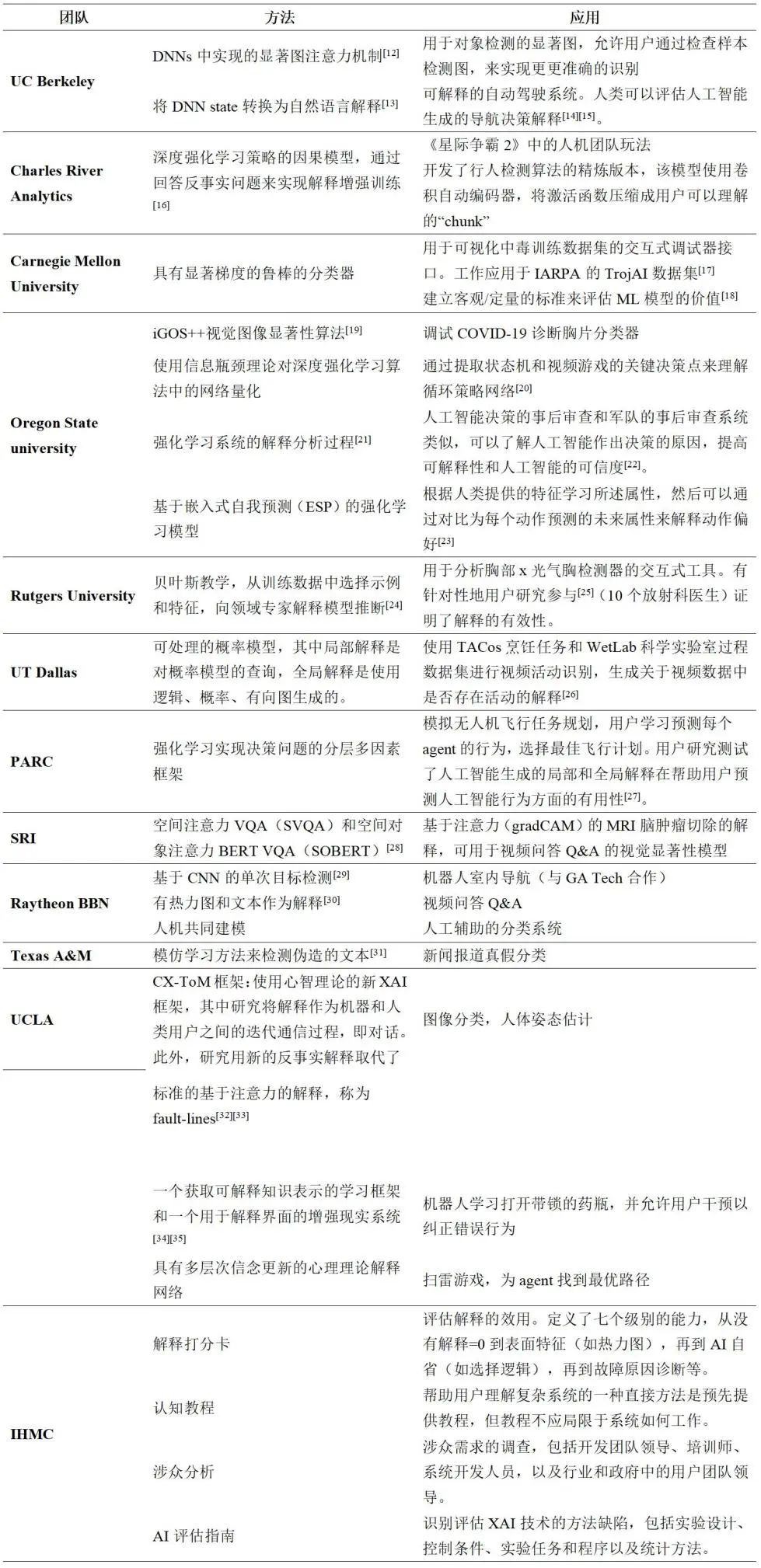
2.3.2 用户研究成果
在用户研究过程中,DARPA的研究团队确定了如下几个关键结论:
1)用户更喜欢为决策提供解释的系统,而非只提供决策的系统。解释能够提供最大价值的任务是那些用户需要理解AI系统如何做出决策的内部工作原理的任务。
2)为了使解释能够提高用户任务表现,任务必须足够困难使得人工智能可以提供帮助。(PARC, UT Dallas)。
3)用户对于解释的认知负担会影响用户的表现。结合上一点解释和任务的难度需要匹配,才能够提高用户的表现。((PARC, UT Dallas)。)
4)当人工智能不正确时,解释会更有帮助,对于边缘情况尤其有价值。(PARC, UT Dallas)
5)解释有效性的度量可以随着时间变化。(PARC, UT Dallas)
6)XAI可用于测量并调整用户和XAI系统的心理模型。(Rutgers, SRI)
7)最后,由于XAI的最后一年发生在COVID-19大流行时期,团队开发了设计web界面,以便在无法面对面研究时进行XAI用户研究。(OSU, UCLA)
尽管如前所述,在模型的学习表现和可解释性之间存在着一种天然的张力,但是在项目进行过程中,团队发现了可解释性可以提高模型性能的证据。从直观的角度来看,训练系统产生解释提供了额外的监督,通过额外的损失函数、训练数据或其他机制,鼓励系统学习更有效地表征。虽然这可能不是在所有情况下都是正确的,但是它提供了研究思路,未来的XAI系统可以比当前系统更加有效,同时满足用户对于解释的需求。
2.3.3. XAITK工具包
此外该研究团队还创建了一个XAI工具包,将各种资料(例如代码、论文、报告等)和从4年DARPA XAI项目中吸取的经验总结收集到一起,可以公开访问(https://xaitk.org/)。
XAITK分析和自治软件框架是基于python的框架,专注于特定的XAI领域,旨在为来自DARPA XAI的多个算法实现提供单个集成功能。每个框架都为系统级数据提供通用API,同时为现有和未来的算法实现提供插件接口。工具包致力于为希望在操作环境中部署人工智能并需要在广泛的现实世界和应用领域中验证和信任人工智能性能的用户提供科学的技术指导。为此,DARPA设立了XAI工具包工作组(XTWG)负责管理不同的工具包组件和特定领域的软件框架,并与潜在合作伙伴沟通以确定XAI相关用例。
XAITK将DARPA的XAI计划的所有输出作为一个工具包,将所有的程序组件集成到一起。工具包涵盖了软件组件和非软件组件,面向不同类型的用户。其中,软件组件包括特定领域的软件框架(例如用于分析或自治)和不同的XAI功能的演示,非软件组件包括出版物、报告和指南、数据源。出版物和报告等大多为静态的,软件和模型大多是动态更新和维护的。下图展示了DARPA不同的团队对不同类型工具包的贡献。
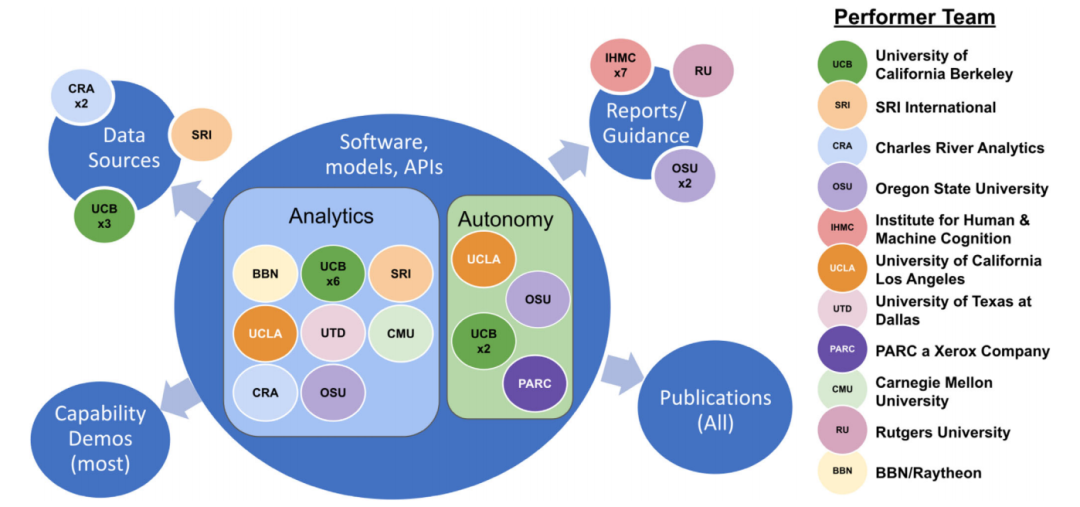
图 9 XAITK研究团队贡献与工具包架构
网站提供两种检索入口,可通过关键词检索,也可通过交互图定位。对于网站的每一个功能,都包含相关的论文和软件资源,以及附加的相关元数据标签,可以根据导航定位到对应的资源。
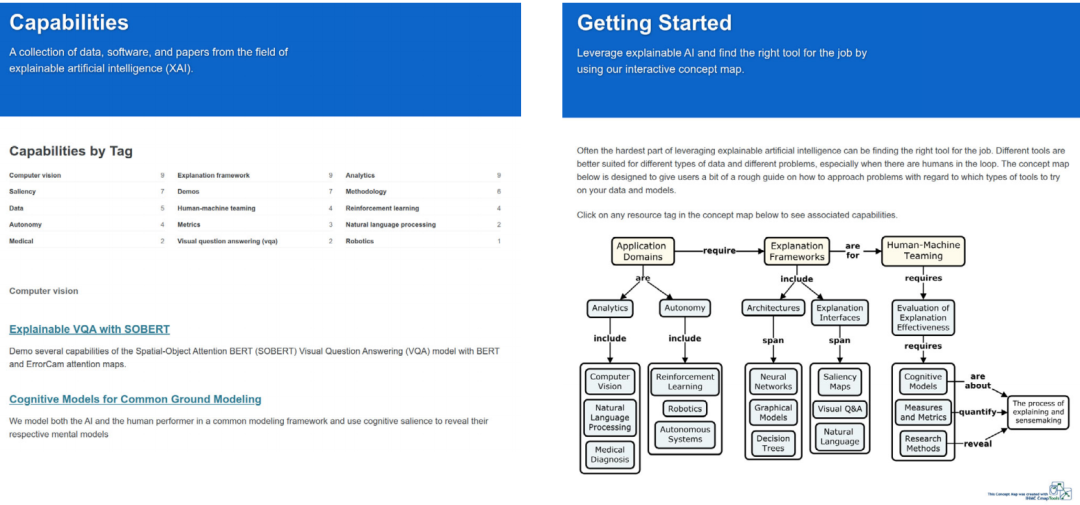
图 10 XAITK工具包 关键词检索(左)交互图定位(右)
XAITK工具包提供了集中的论文、数据集和代码的开源集合,不仅能够跟踪DARPA的XAI计划的四年工作成果,还能够集成可解释人工智能领域的研究成果。随着XAI领域的发展,该工具包将进一步扩展新的算法和发现,也将长期可持续性的发展完善,服务于学界、业界和政府政策制定者等相关人员。
3
DARPA XAI 项目展望
目前还没有通用的XAI解决方案,如前所述,不同的用户类型需要不同的类型的解释。也许未来的XAI系统能够在大范围的用户类型中自动校准并向特定用户传达解释,但是这远远超出了当前的技术水平。
开发XAI的挑战之一是衡量解释的有效性。DARPA的XAI项目帮助开发了这一领域的基础技术,但是还有很多工作要做,包括从人的因素和心理学领域中汲取更多的知识。为了使有效的解释成为ML系统的核心能力,需要更好地建立和实现解释有效性的度量。这就需要跨度各学科的紧密合作,包括计算机科学、机器学习、人工智能、心理学等,。也许在未来,一个特定的AI研究学科将建立在多学科的交叉点上。
UC Berkeley[36]的研究结果表明,人工智能系统采纳用户建议的能力,能够提高用户的信任,而不仅仅是解释。换言之,用户可能更喜欢能够快速纠正系统行为的系统,就像人类能够互相提供反馈一样。这种技能产生解释,又能消费和利用解释的明智的人工智能系统,将是事项人类与人工智能系统之间更密切合作的关键。
今天,我们对于人工智能的理解比2015年更加深入,同样我们对于深度学习的可能性和局限性也有了更加准确的理解。那么类似地,XAI项目的结果使得人们对于XAI的用户、心理、解释的有效性以及ML和HCI技术的新组合有了更细致的了解。未来随着新的人工智能技术的发展,我们还有更多的工作要做。但是XAI计划无疑为这个活跃的研究领域做出了重大的贡献。
[1] V. Bellotti, K. Edwards, Intelligibility and accountability: Human considerations in context-aware systems. Hum. Comput. Interact. 16, 193–212 (2009).
[2] Gunning D, Vorm E, Wang Y, et al. DARPA’s explainable AI (XAI) program: A retrospective[J]. Authorea Preprints, 2021.
[3] Hu B, Tunison P, Vasu B, et al. XAITK: The explainable AI toolkit[J]. Applied AI Letters, 2021, 2(4): e40.
[4] Gunning D, Aha D. DARPA’s explainable artificial intelligence (XAI) program[J]. AI magazine, 2019, 40(2): 44-58.
[5] Ribeiro, M. T.; Singh, S.; and Guestrin, C. 2016. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 1135–44. New York: Association for Computing Machinery. doi.org/10.1145/2939672.2939778
[6] Alipour K, Ray A, Lin X, et al. Improving users' mental model with attention-directed counterfactual edits. Appl AI Lett. 2021;2(4):e47.
[7] Ebrahimi S, Petryk S, Gokul A, et al. Remembering for the right reasons: explanations reduce catastrophic forgetting. Appl AI Lett. 2021;2(4):e44.
[8] Hu R, Andreas J, Darrell T, Saenko K. Explainable neural computation via stack neural module networks. Appl AI Lett. 2021;2(4):e39.
[9] Taylor E, Shekhar S, Taylor G. Neural response time analysis: XAI using only a stopwatch. Appl AI Lett 2021;2(4):e48.
[10] Clancey W, Hoffman R. Methods and standards for research on explainable artificial intelligence: lessons from intelligent tutoring systems. Appl AI Lett. 2021;2(4):e53.
[11] Hamidi-Haines M, Qi Z, Fern AP, Fuxin L, Tadepalli P. User-guided global explanations for deep image recognition: a user study. ApplAI Lett. 2021;2(4):e42.
[12] Vasu B, Hu B, Dong B, et al. Explainable, interactive content-based image retrieval. Appl AI Lett. 2021;2(4):e41.
[13] Hendricks LA, Rohrbach A, Schiele B, Darrell T, Akata Z. Generating visual explanations with natural language. Appl AI Lett. 2021;2(4):e55.
[14] Kim J, Rohrback A, Akata Z, et al. Toward explainable and advisable model for self-driving cars. Appl AI Lett. 2021;2(4):e56.
[15] Watkins O, Huang S, Frost J, et al. Explaining robot policies. Appl AI Lett. 2021;2(4):e52.
[16] Witty S, Lee JK, Tosch E, et al. Measuring and characterizing generalization in deep reinforcement learning. Appl AI Lett. 2021;2(4):e45.
[17] Sun M, Siddhant A, Kolter JZ. Poisoned classifiers are not only backdoored, they are fundamentally broken. arXiv preprint arXiv:2010.09080; 2020.
[18] Yeh CK, Ravikumar P. Objective criteria for explanations of machine learning models. Appl AI Lett. 2021;2(4):e57.
[19] Li F, Qi Z, Khorram S. From Heatmaps to structural explanations of image classifiers. Appl AI Lett. 2021;2(4):e46.
[20] Danesh MH, Koul A, Fern A, Khorram S. Re-understanding finite-state representations of recurrent policy networks. Paper presentedat: International Conference on Machine Learning. PMLR; 2021:2388-2397.
[21] Dodge J, Anderson A, Roli K, et al. From "no clear winner" to an effective XAI process: an empirical journey. Appl AI Lett. 2021;2(4):e36.
[22] Mai T, Khanna R, Dodge J, et al. Keeping it "organized and logical" after-action review for AI (AAR/AI). Paper presented at: Proceedings of the 25th International Conference on Intelligent User Interfaces; 2000:465-476.
[23] Lin Z, Lam KH, Fern A. Contrastive explanations for reinforcement learning via embedded self predictions. arXiv preprint arXiv:2010.05180; 2020.
[24] Yang SC, Folke T, Shafto P. Abstraction, validation, and generalization for explainable artificial intelligence. Appl AI Lett. 2021;2(4):e37.
[25] Folke T, Yang SCH, Anderson S, et al. Explainable AI for medical imaging: explaining pneumothorax diagnoses with Bayesian teaching.arXiv preprint arXiv:2106.04684; 2021.
[26] Roy C, Honeycutt D, Block J, et al. Explainable activity recognition in videos: lessons learned. Appl AI Lett. 2021;2(4):e59.
[27] Stefik M, Youngblood M, Pirolli P, et al. Explaining autonomous drones: an XAI journey. Appl AI Lett. 2021;2(4):e54.
[28] Ray A, Cogswell M, Lin X, et al. Generating and evaluating explanations of attended and error-inducing input regions for VQA models.Appl AI Lett. 2021;2(4):e51.
[29] Bau D, Zhu JY, Strobelt H, et al. GAN dissection: visualizing and understanding generative adversarial networks. arXiv preprint arXiv:1811.10597; 2018.
[30] Selvaraju RR, Das A, Vedantam R, et al. Grad-CAM: why did you say that? arXiv preprint arXiv:1611.07450; 2016.
[31] Linder R, Mohseni S, Yang F. How level of explanation detail affects human performance in interpretable intelligent systems: a study on explainable fact checking. Appl AI Lett. 2021;2(4):e49.
[32] Akula AR, Wang K, Liu C, et al. CX-ToM: counterfactual explanations with theory-of-mind for enhancing human trust in image recognition models. arXiv preprint arXiv:2109.01401; 2021.
[33] Akula AR, Wang S, Zhu SC. Cocox: generating conceptual and counterfactual explanations via fault-lines. Proc AAAI Conf Artif Intell.2020;34(3):2594-2601.
[34] Liu H, Zhu Y, Zhu SC. Patching interpretable and-or-graph knowledge representation using augmented reality. Appl AI Lett. 2021;2(4):e43.
[35] Edmonds M, Gao F, Liu H, et al. A tale of two explanations: enhancing human trust by explaining robot behavior. Sci Robot. 2019;4(37).
[36] Kim J, Rohrback A, Akata Z, et al. Toward explainable and advisable model for self-driving cars. Appl AI Lett. 2021;2(4):e56.
撰稿 | 宋明烜,清华大学智能法治研究院实习生
选题&指导 | 刘云
编辑 | 王欣辰
注:本公众号原创文章的著作权均归属于清华大学智能法治研究院,需转载者请在本公众号后台留言或者发送申请至computational_law@tsinghua.edu.cn,申请需注明拟转载公众号/网站名称、主理者基本信息、拟转载的文章标题等基本信息。


















 60
60

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









