







来源:脑机接口社区
运营/排版:何晨龙
人类天生具有分离各种音频信号的能力,比如区分不同的说话者的声音、或将声音与背景噪音区分开来。这种天生的能力被称为“鸡尾酒会效应”。
中枢听觉系统通过分析声音流中的模式的统计结构(例如频谱或包络),可以轻松地在混合的声音中识别特定的目标声音。
在 AI 领域,设计与人类一样强大的语音分离系统长期以来一直是一个重要目标。
先前的神经科学研究提示:人类大脑经常利用视觉信息来帮助听觉系统解决 “鸡尾酒会问题”。
受到这一发现的启发,视觉信息被纳入进来以改善语音分离质量,由此产生的方法被称为多模态语音分离方法。
如果系统能够捕捉到唇部运动,这一额外线索将有助于语音处理,因为它在嘈杂环境中补充了语音信号的信息丢失。
然而,现有的多模态语音分离方法的分离能力仍远远不及人类大脑。
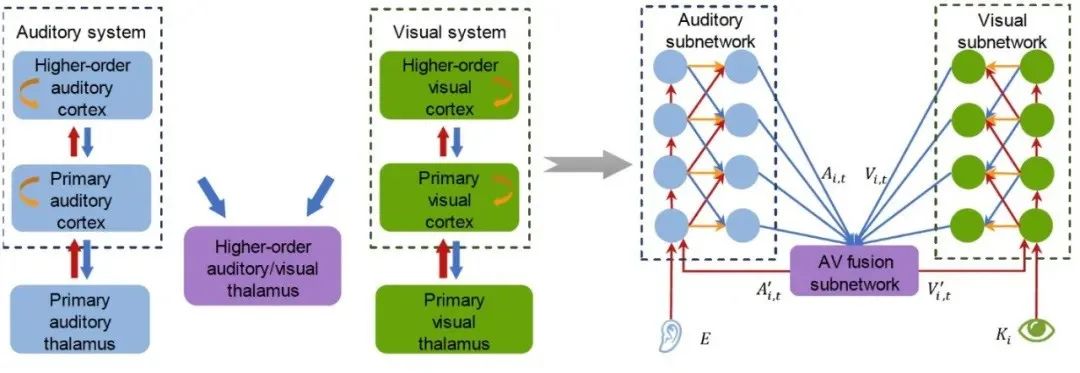
基于此,清华大学生物医学工程学院苑克鑫教授团队打造了一款脑启发 AI 模型(CTCNet,cortico-thalamo-cortical neural network)。

图 | 苑克鑫(来源:苑克鑫)
该模型的语音分离性能大幅领先于现有方法,不仅为计算机感知信息处理提供了新的脑启发范例,而且在智能助手、自动驾驶等领域有潜力发挥重要作用。
苑克鑫表示:“CTCNet 是在皮层-丘脑-皮层环路和 A-FRCNN 基础上的结果。”
近些年,苑克鑫课题组针对高级听觉丘脑及其皮层联接的架构和生理学特性进行了系统性研究。
在此基础上,结合清华大学计算机系胡晓林教授课题组之前的语音分离应用算法,他们提出了一种多模态语音分离方案。
然后,使用公开数据集进行了一系列的语音分离测试和调参,最终才得到了具有优异语音分离性能的 CTCNet。
(来源:TPAMI)
因此,本次研究是在机制研究的基础上引发的应用研究。
“总体而言,这是一个双向奔赴的合作过程。作为一名 AI 研究者,也许可以通过阅读脑科学领域的文献来获得灵感,但与脑科学研究者的直接沟通一定是最为高效。”苑克鑫说。
他继续表示,在没有相应知识的情况下,AI 研究者通过阅读文献来理解大脑的工作原理是有一定困难的。
而作为脑科学研究者,应该有将研究成果向 AI 领域转化的意识和意向,主动与 AI 领域的研究者接触、讨论,这样才有可能碰撞出火花。
事实上,AI 研究者在没有脑科学知识的情况下,已经在试图模拟大脑的部分功能,只不过脑科学研究者并不知道。
通过接触和了解,脑科学研究者就有机会将其研究成果迁移至 AI 研究者已经开展的脑功能模拟的尝试中,从而助力于开展真正有效的脑启发 AI 研究。
苑克鑫表示:“通过本次研究,我深切体会到了神经科学与 AI 领域的研究人员之间加强交流,对于有效开展脑启发 AI 相关工作的重要性。”

图 | 胡晓林(来源:百度百科)
据了解,苑克鑫与胡晓林都同时是清华大学与大脑研究相关的三个中心的兼职研究员,因此经常有机会互相听对方的工作报告,这成为了他们发起合作的契机。
另外,由于神经科学与 AI 是两个截然不同的学科,合作的成功离不开双方团队成员的密切交流。
虽然在交流过程中经常出现词同意不同的情况,甚至出现互相听不懂对方在说什么的情况,但是双方都有足够的耐心去理解对方措辞的内涵,这成为了最终合作成功的重要保障。
最终,相关论文以《由皮层-丘脑-皮层环路启发的视听语音分离模型》(An Audio-Visual Speech Separation Model Inspired by Cortico-Thalamo-Cortical Circuits)为题发在 Transactions on Pattern Analysis and Machine Intelligence(TPAMI)[1]。
胡晓林团队的硕士生李凯是第一作者,苑克鑫团队的博士后谢凤华、以及胡晓林团队的博士生陈航分别是第二作者和第三作者,苑克鑫和胡晓林担任共同通讯作者。

图 | 相关论文(来源:TPAMI)
下一步:
首先,他们将解析在单丘脑神经元水平上视、听觉信息的空间和时间整合模式,希望能够借助于该模式实现对 AI 模型的升级,进一步提高模型的语音分离性能,使其能够应对更加复杂的自然场景;
其次,他们将探索该模型在其他应用场景,如探索在噪音背景下的医学信号检测中的应用潜力;
最后,他们将解析在中枢感觉系统中处于更低层级脑区,如中脑中的多模态神经元的解剖、功能联接架构,进而探索这些联接架构启发 AI 模型构建的潜力。
预计拟构建的一系列 AI 模型,将能逆向揭示不同多模态感觉核团、及其中的神经元,在中枢感觉信息处理中可能扮演的重要角色和工作机制。
参考资料:
1.K. Li, F. Xie, H. Chen, K. Yuan and X. Hu, "An Audio-Visual Speech Separation Model Inspired by Cortico-Thalamo-Cortical Circuits" in IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. , no. 01, pp. 1-15, 5555.
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









