







来源:新基石科学基金会
导语:
2024年9月28日,南方科技大学、腾讯可持续社会价值事业部、新基石科学基金会联合主办第四届“青年科学家50²论坛”。香港科技大学校董会主席、美国国家工程院外籍院士沈向洋应邀出席论坛,并以《大模型时代的机遇和挑战》为题做了主旨演讲。本文根据演讲实录整理,略有修改,未经本人审阅。标题为编者所拟。

我接着姚先生讲的人工智能话题,跟大家报告一下在大模型时代,我们现在正在做的一些事情,特别是从技术融合、产业跃迁的角度怎么来看这个问题。
整个人类发展的历史就是一个技术发展的历史,没有技术就没有GDP的增长。我们就不回顾到什么钻木取火、发明轮子这些事情——我们就从这100年物理学上很多了不起的突破,过去70年人工智能、计算机科学的突破,就可以看得到,有很多发展的机会。
过去几年大家一定是一步一步被新的人工智能的体验所震撼,即使我做了一辈子的人工智能,几年前也很难想象今天这样的情况。
我想讲三个例子:第一个是从文生成文,第二个是从文生成图,第三个是从文生成视频。讲到ChatGPT人工智能的系统,不仅国际上有,国内也有。比如,我今天到这里来作演讲之前,我问ChatGPT,我要参加腾讯主办的青年科学家50²论坛,做一个演讲,作为我这样的背景应该讲什么样的话题。大家可能觉得有点搞笑,其实用下来,觉得还是非常好的。

ChatGPT大家都比较熟悉了,两年前OpenAI就出了一个文生图的系统,你给出一段话,它就生出一个图出来。7个月之前它又出来了Sora,你给它一段话,它给你生成一段60秒的高清视频,比如这个漫步在东京街头的视频,这都非常震撼。(时间关系我就不放视频了。)
我讲一下这个文生图的例子。我是做计算机图形学的,自以为对一张照片好和不好很有感觉。两年前,这张照片出来,这是人类历史上第一个人工智能生成的照片,登上了美国时尚杂志(《Cosmopolitan》)的封面。在旧金山有一个数字艺术家用了OpenAI的系统,问了一段话,产生了这样一个结果。这段话是:在浩瀚的星空中,一位女宇航员在火星上昂首阔步,走向一个广角镜头。我自己没有那么大的艺术天分,但是我看到这张图之后是非常震惊的,我想你也会同意我的讲法,人工智能画出这样的图来,它真的就是像一个女宇航员。所以这个人工智能已经到了相当智能的程度。今天有了这样一些了不起的技术,甚至是一些了不起的产品。
我们在国内也都非常努力,从技术到模型,到后面的应用,方方面面我们都在做。刚才姚院士也讲了很多清华最新的工作。所以我就想跟大家分享一下,在通用人工智能时代,我们应该怎么去思考大模型,我想谈几点自己的看法。
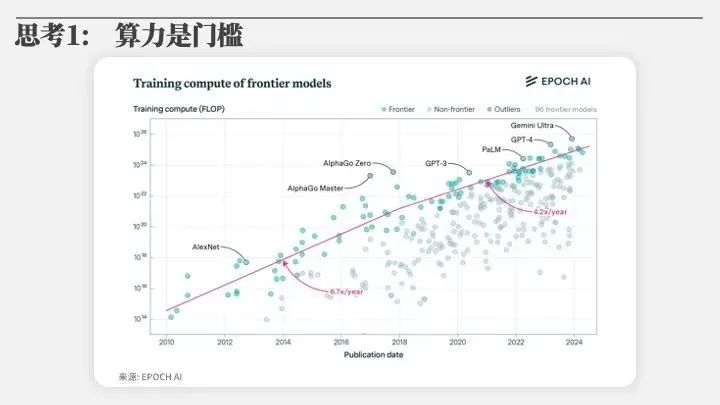
第一个思考,今天的通用人工智能、大模型、深度学习,最重要的一件事情是最近这些年整个人工智能算力的增长。
过去10年,大模型用到算力的增长,一开始是每年六七倍的增长,后来是每年超过4倍的增长。我现在问大家一个问题,如果一年涨4倍,10年会涨多少倍?
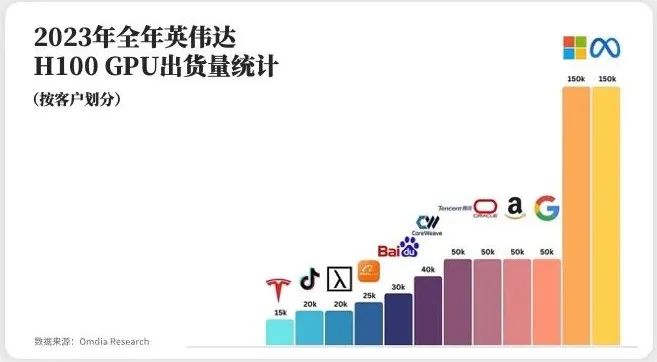
大家都知道这一波人工智能发展,最获益的公司就是英伟达,英伟达的芯片出货量逐年递增,算力逐步增强,整个公司的市值也成为全世界3个3万亿美元市值的公司(微软、苹果、英伟达)之一。最重要的还是因为每年大家对算力的需求。2024年购买英伟达芯片的数量还在急剧增长,比如埃隆·马斯克,他现在在建一个10万H100卡的集群,本身建万卡系统就非常困难了,建10万卡系统更困难,对网络的要求都非常高。
今天讲算力、大模型这件事情,最重要的就是(算力和数据)扩展(Scaling Laws),算力越多,智能越增长,现在大家都还没有摸到天花板。其中很不幸的是,整个数据量大了以后,算力的增长还不是线性增长,算力的增长更加像是一个平方的增长。
因为模型大了以后,要把模型训练出来,数据的量也要堆上去,所以相对来讲更加像是一个平方的增长。对算力的要求,过去10年的变化是非常巨大的。因此我就讲一句话,今天要做人工智能大模型,讲卡伤感情、没卡没感情。
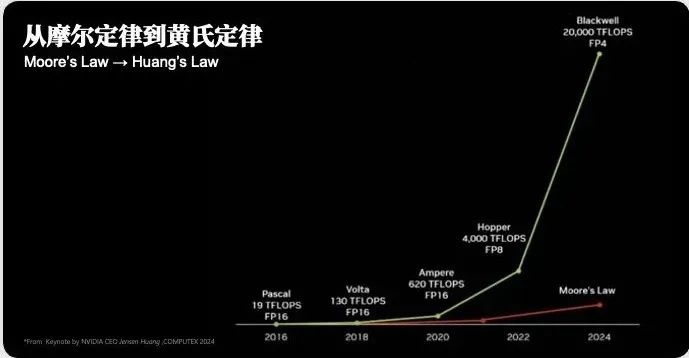
我刚才问了大家一个问题,算力每年涨4倍,10年涨多少倍?我们学计算机的人都知道“摩尔定律”,每18个月左右算力增长一倍,英特尔这么多年就是这样发展起来的。为什么英伟达现在已经超越了英特尔?很重要的原因就是它的增长速度不一样。如果18个月涨一倍,10年大概涨100倍,这也是非常了不起的事情;如果每年涨4倍,10年就是100万倍,这个增长是非常惊人的。如果你这样想问题,英伟达的市值过去这10年涨得这么快,也就是可以理解的。

第二个思考,关于数据的数据。算力、算法和数据,是人工智能重要的三个因素。前面我提到我们需要很多的数据才能训练通用人工智能。当ChatGPT3还只是在发表论文的阶段,说需要2万亿的Token的数据量;到GPT4出来的时候,大概是12万亿Token的数量,GPT4不断地训练,今天估计它已经超过20万亿Token的数量。对人工智能关心的人都知道,这么长时间以来大家一直等待着GPT5出来,但是它迟迟没出来,如果有GPT5出来,我个人判断可能会达到200万亿Token的数据量。回过头来问,互联网上有没有那么多好的数据。等你清洗完以后,可能20万亿Token就差不多到顶了,所以未来要做GPT5,除了现有的文本数据,还要更多的多模态数据,甚至人工合成的数据。
过去三四十年,大家把自己的信息放到网上分享,以前我们觉得这是在给搜索引擎打工,现在回头一想更加了不起的是,这一切好像就是为了ChatGPT出现这一时刻,它把所有的东西整合在一起,通过强大的算力,把这样一个人工智能模型学了出来。
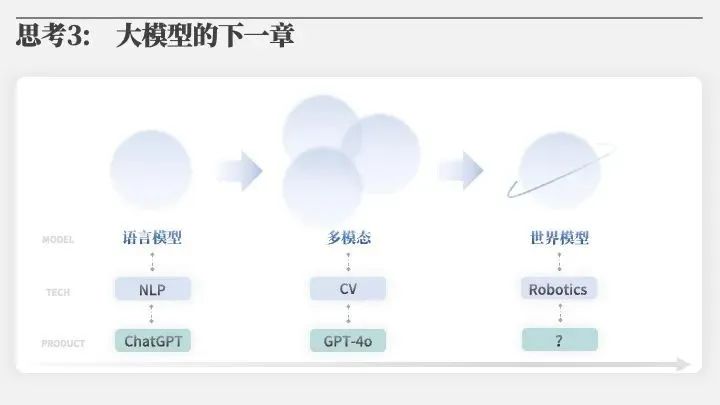
第三个思考,大模型的下一章。过去人们首先干的是语言模型。以ChatGPT为代表,它的底层技术是自然语言处理。今天大家正在干的是多模态模型,以GPT-4o为代表,里面很多技术是计算机视觉。再向前走,就是要做具身智能。它的目的实际上是要建一个世界模型。现在就算是做多模态的,底层的物理模型也是没有的,所以要做这样一个世界模型。世界模型就是你不仅要读万卷书,还要行万里路,把世界上更多的知识再反馈回你的大脑里。所以应该做机器人。我就觉得深圳应该下定决心做机器人,做具身智能。机器人里面有一个特别的赛道叫自动驾驶,自动驾驶是一个特别的机器人,只是它是在给定的路线上行驶。
要怎么做?有很多多模态的科研工作要做,我相信一个非常重要的方向是多模态的理解和生成的统一。就算Sora、Dall-E做出来,它也是分开的,多模的生成和多模的理解没有统一起来。这方面有很多科研的工作我们可以做。
举一个例子,我的几个学生他们多模态的理解做得非常优秀。如果拿一张图给人工智能看一看,为什么图中的行为被称为“无效技能”,AI给你解释是,这个图看起来好像是一个小朋友在地上打滚,但是他妈妈无动于衷,自己在看手机和喝饮料,所以小朋友这个技能就被称为“无效技能”。AI现在对图的理解做得越来越好。

第四个思考,人工智能的范式转移。两个礼拜前,OpenAI发布了最新一个模型就是GPT-o1。前面我也提到GPT一直发展,到了GPT4以后,GPT5一直出不来,大家就在想,如果只是大模型参数的增长,是不是走到顶了?没有人知道。我们国内也没有做出更加超大的模型。但是突然现在一个新的维度出现了,不是做前面的预训练(扩展),而是真正在做推理的时候再去做扩展。它是从原来的GPT思路,变成了今天的自主学习的道路,就是在推理这一步强化学习,不断地自我学习的过程。以前我们做预训练,基本上就是预测下一个字是什么,下一个token是什么。现在新的思路是要打草稿,试试看这条路对不对,那条路对不对。就像我们做数学题一样,先打个草稿,看看哪个路走得通,有一个思维链,再看优化思维链过程中的机会。到现在为止只有OpenAI把这样一个系统放出来,我也鼓励大家看看这里面的一些例子。最重要的是,它整个过程非常像人类思考问题、分析问题,打草稿、验证、纠错、重新来,这个思路空间就会非常大。做这件事也需要非常多的算力才行。

第五个思考,大模型横扫千行百业。所有的公司都要面对大模型带来的机会,但是不需要每个公司都做通用的大模型,如果你连1万张卡没有,是没有做通用大模型的机会的,要做通用大模型,至少要有万卡。比如说GPT4出来的时候,它的训练的总量是2×10^25 FLOPs。这么大的训练量,1万张A100卡也要跑一年时间才能跑到这个量,如果这个量都跑不到,就不存在做出真正的通用大模型。有了通用大模型,我们在这个基础上可以建自己的行业大模型,比如金融、保险,可能千卡就可以做得非常好,在上面做一些微调。对一个企业来讲,你有自己的内部数据、客户数据,把这些数据拿出来,几十张、上百张卡就可以做一个面向自己企业的非常好的模型。所以它是一层一层不断地搭起来的。
当然还有一个非常重要的维度,也是我非常喜欢的,就是未来的个人大模型。今天我们已经慢慢在PC、手机里面(积累了一定的数据),对我们自己的理解越来越多,未来我相信有这样一个超级智能、帮助你的AI,收集了你的相关数据以后,它可以建一个自己的个人大模型。应用在(个人)终端、手机就是一个很自然的事情。PC方面,微软、联想这些PC公司也在推AI PC的概念。所以,也有这样一些机会。
在中国的大模型建设浪潮当中,越来越多的是行业大模型。到今年7月底之前,中国一共有197个模型被批准,当中70%是行业大模型,30%是通用大模型。未来通用大模型的数量、占比会越来越低。我们可以在通用大模型上做金融模型,比如上海的一家公司做的面向它的金融客户的大模型。英伟达的财报出来了,这个模型马上可以总结出它的亮点是什么、问题是什么。

第六个思考,大模型最大的超级应用是什么,最大的机会在哪里?很多人现在不断地尝试,想找到一个超级应用。实际上超级应用一开始就在那里,就是一个超级Agent。以前我跟盖茨在微软一起做了很多年的工作,我们都在思考这个问题。它难在哪里?难在真正你要做有用工作的时候,要理解一个工作流,你问了一个问题,它能一步一步拆解,把这个事情能够做出来,有意义。今天能做的、又有一定影响力的,是做客服、简单的个人助理。但是很多工作是没法弄的,它为什么没法弄呢?你要做一个数字大脑。
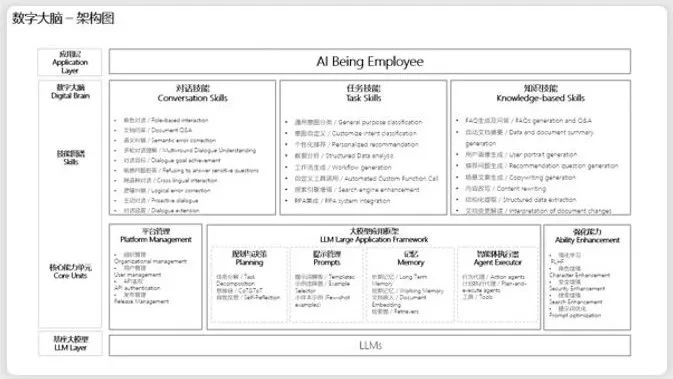
在这个架构图里你就能看到它的困难,底下的大模型只是第一步,它的能力还没有强大到把上面的这些工作都帮你一步一步做掉。因为你真正要做这样一个Agent,让它能做事情,它要了解下面这些问题是什么,每一部分都有对应的技能。接下来相信大家会看到很多这样的应用。

第七个思考,开源和闭源。过去几十年世界科技的发展,特别是中国科技的发展,有两件事情是非常重要的。第一是出现了互联网,有了互联网之后,你就可以在网上找到所有的论文、资料。第二是开源,开源就使得你做应用的时候,跟领先者的差距急剧缩短。但是在大模型开源这件事情上,和传统的操作系统、数据库的开源还不一样,虽然现在开源系统的能力是直逼闭源系统。国内也有很多公司在做开源的东西,今天开源做得非常好的是Meta的Llama 3.1,号称和OpenAI的差距不大了。我不这么认为,我认为它并不是传统的开源,它只是开源了一个模型,并没有给你源代码和数据,所以我们在用开源系统的时候,也要下定决心真正理解大模型的系统闭源的工作。

第八个思考,要重视AI治理。因为AI发展太迅猛了,全世界对AI安全都非常重视。因为这件事情的影响实在是太大了,人工智能对千行百业、对整个社会的冲击非常大,整个世界的发展实际上是要大家共同来面对AI治理的。

第九个思考,重新思考人机关系。我刚才介绍了文生文、文生图、文生视频——有多少是机器的智能,有多少是因为人机交互给我们带来的震撼?大概10年前,《纽约时报》专栏作家John Markoff写了一本我非常喜欢的书Machines of Loving Grace,当中总结了计算机科技过去发展的两条线:一条是人工智能;另外一条是IA(Intelligent Augmentation),它是智能的增强,就是人机交互。有了计算机之后,它帮助人做了很多事情,下棋是其中一个例子。事实上,真正把人机交互搞清楚,才能成为每一代高科技企业真正有商业价值的领导者。今天人工智能的界面已经非常清晰了,就是对话的过程,代表是ChatGPT。但是讲OpenAI加上微软就代表这个时代还太早,他们是领先了,但是未来还有很多想象的空间。

第十个思考,智能的本质。今天虽然大模型已经给大家带来很多的震惊,但是我们对大模型、深度学习的理解暂时是没有理论的。不像物理学,大到浩瀚的星空、小到微小的量子都有很美的一些物理的定律来描述。今天人工智能还没有这样的理论,没有可解释性、没有鲁棒性。今天深度学习的框架还到不了真正的通用人工智能。
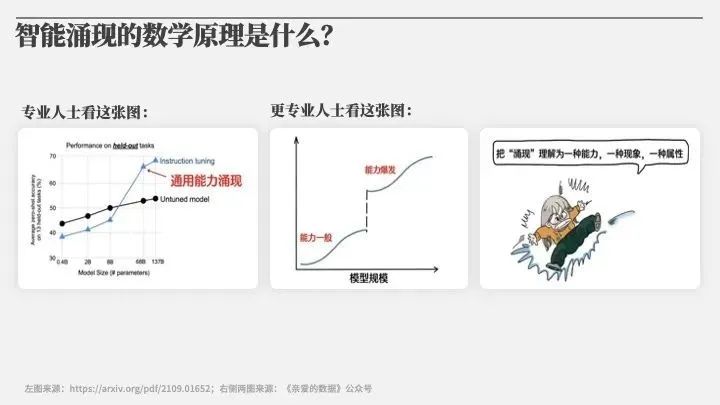
关于人工智能的涌现,大家只是讲讲,并没有讲清楚。为什么模型大到一定程度智能就涌现了?为什么70B的模型就能涌现智能?没有这样的道理。所以我们也在非常努力地研究这方面的问题。去年暑假我也在香港科技大学组织了一场主题为“Mathematical Theory for Emergent Intelligence”的研讨会,讨论涌现智能背后还是要把一些科学原理、数学原理讲清楚。要有更多愿意探索的人参与进来,特别是像“科学探索奖”、“新基石研究员项目”的出现,有更多的年轻科学家加入进来,有更多的信心、信念深入到为未来人工智能发展再有突破的难的问题当中。
再次祝贺各位获奖者、年轻的科学家。科技的发展需要靠年轻人一代一代来做,特别是人工智能。

未来知识库是“欧米伽未来研究所”建立的在线知识库平台,收藏的资料范围包括人工智能、脑科学、互联网、超级智能,数智大脑、能源、军事、经济、人类风险等等领域的前沿进展与未来趋势。目前拥有超过8000篇重要资料。每周更新不少于100篇世界范围最新研究资料。欢迎扫描二维码或点击本文左下角“阅读原文”进入。
















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









