







MAE 论文逐段精读【论文精读】
这一次李沐博士给大家精读的论文是 MAE,这是一篇比较新的文章,2021年11月11日才上传到 arXiv。这篇文章在知乎上的讨论贴已经超过了一百万个 view,但是在英文社区,大家反应比较平淡一点,Reddit 或者 Twitter 上大家讨论的并不多。
MAE 这篇论文大家可以看作是 CV 版的 BERT,作者提出了非对称的掩码自编码器用于计算机视觉自监督学习,通过随机掩盖一部分图像 patch,再重构图像缺失的 pixel。
MAE 论文链接:https://arxiv.org/abs/2111.06377。
MAE 代码链接:https://github.com/facebookresearch/mae。
0. Transformer、BERT、ViT、MAE关系介绍
李沐博士首先介绍了 MAE 和之前精读的论文(Transformer,BERT,ViT)之间的关系。

Transformer是一个纯基于注意力机制的编码器和解码器,在机器翻译的任务上其比基于RNN的架构要好一点。BERT使用一个Transformer编码器拓展到更一般的NLP任务,使用了像完型填空一样的自监督训练机制。不需要使用标号去预测一个句子里面不见(masked)的词, 从而获取对文本特征抽取的能力。BERT极大地拓展了Transformer的应用,使其可以在一个大规模的、没有标号的数据上训练出非常好的模型。ViT将Transformer用到CV上面,具体来说它把整个图片分割成很多16 * 16的小方块,每一个方块做成一个词(token),然后使用Transformer进行训练。当训练数据足够大的时候(1000万或者一个亿的训练样本),Transformer的架构精度优于CNN架构。MAE可以看作是BERT的一个CV版本,基于ViT把整个训练拓展到没有标号的数据上面,跟BERT一样通过完型填空来获取图片的一个理解。MAE并不是第一个将BERT拓展到CV上的工作,但是很有可能是这一类工作中未来影响最大的,由于BERT加速了Transformer架构在NLP上的应用,MA也很有可能加速Transformer在CV上的应用 。
1. 标题、作者、摘要、示意图、结论
首先是论文标题,论文标题意思是:带掩码的自编码器是可扩展的视觉学习器。MAE 这个词就来自于论文标题前两个单词。

- 先看后面的词,写论文的时候当你的算法比较快,可以用
efficient,如果模型比较大的话,就用scalable;vision learners可以看作是一个backbone模型,作者这里没有指出是分类器还是检测器、分割器,因为在论文中作者做的实验很多,分类、检测、分割都做了。 masked来源于BERT,BERT是masked language model(带掩码的语言模型),类似于完形填空,每次挖掉一些东西,然后去预测挖掉的东西。autoencoder中auto不是自动的意思,而是自的意思,表示样本和标号都来自于图像本身,MAE这篇论文是自监督训练,重构的图像像素就来自于图像本身,并没有引入额外的标号。
值得学习的是,这一类标题模板 (xx是xx) 是很强有力的句式,把文章的结论总结成一句话了,结论放在 title 里,句式也相对客观。
论文作者就不过多介绍了,之前也精读了一作的论文(ResNet,MoCo),最后两位作者是物体检测领域的大佬。
下面是论文摘要部分,摘要总共有8句话。

- 第1句话可以看作是论文标题的扩展,本文证明了
掩码自编码器(MAE)是一种可扩展的计算机视觉自监督学习器。 - 第2-5句介绍了
MAE算法,MAE方法很简单:随机掩盖一部分图像patch,再重构图像缺失的pixel。它有两个核心设计:一是本文开发了一个非对称的编码器-解码器体系结构,其中编码器只在可见的patch上操作学习特征,轻量级的解码器从潜在表征和掩码 token重建原始图像。二是作者发现掩盖高比例的输入图像块(例如75%),会生成一个非凡而有意义的自监督任务 (可以理解为如果只遮住几个patch的话,插值法就可以得到图像缺失的像素,遮住一大半图像的话,会迫使模型学习更有用的表征 )。 - 第6-8句介绍了
MAE的实验效果,将上面两个核心设计结合起来,能够高效率地训练大模型,训练速度提高了3倍多,且模型准确度也提高了;本文提出的可扩展的方法允许学习高容量的模型,这些模型具有很好的通用性,例在使用ImageNet-1K数据上,一个原始的ViT-Huge模型获得了最好的准确率 (87.8%);在迁移学习模型性能也优于有监督预训练,同时也表现出很好的可扩展行为。
下面是论文中重要的示意图,一般放在论文第一页的右上角,这是 MAE 的结构。
 整个训练流程为:输入一张图片,分割成一个个
整个训练流程为:输入一张图片,分割成一个个 patch,然后随机掩盖一部分 patch (图中处理成灰色块);可见的 patch 输入到编码器进行训练得到图像特征;然后训练得到的特征和掩盖的图像块(含有位置信息)输入到解码器,解码器输出为预测的掩盖图像块像素。可以看到这里的编码器和解码器大小不一样,主要的计算量都在编码器,且由于编码器只处理1/4的图像,其计算量也得到了降低,训练速度也提高了。
如果想在其它视觉任务上使用 MAE,只需要使用掩码器就行了。输入一张图片,不需要做掩码处理,直接分割成 patch,然后得到所有 patch 的特征表示,可以看作是这张图片的特征,后面使用分类头、检测头、分割头去预测。
下图是作者在 ImageNet、COCO 数据集上的测试结果、以及不同掩码比例后得到的结果(图4),可以看到其重构效果是很拔群的。

最后是论文结论部分,总共有3段。

- 可扩展的简单的算法是深度学习的核心。这里的简单前提是指作者对
ViT很熟悉,本文训练的方法很简单。在NLP中,简单的自监督学习方法可以从指数级扩展模型中获益。在计算机视觉中,尽管在自监督学习方面取得了进展,但实际中占统治地位的预训练范式任然是有监督学习。在本文中,我们在ImageNet和迁移学习中观察到自编码器提供了可扩展的好处。计算机视觉中的自监督学习现在可能正走上与NLP相似的轨迹。 - 另一方面,我们注意到
图像和语言是有不同属性的信号。虽然每一个patch含有一定语义信息,但它不是语义分割,而且MAE 是重构像素,像素不是语义实体。但是MAE能够推断出复杂的、整体的重构,表明它已经学会了许多视觉概念。我们假设这种行为是通过MAE内部丰富的隐藏表示发生的。我们希望这一观点将激励未来的工作。 - 更广泛的影响,
MAE只用了图片本身进行学习,如果图片本身有bias的话,那么模型可能倾向于某一些图片或 有一些不好的图片,可能会有负面的社会影响;MAE和GAN类似, 可能生成不存在的内容,有误导大家的可能,如果要使用这个工作,请一定要考虑潜在的影响,
2. 导论
导论前两段介绍了故事背景,现在模型可以很容易过拟合百万张图片并且已经开始需要上亿张图片,但是往往很难访问到这些有标签的数据。这个问题在 NLP 可以通过自监督预训练的方式来解决,例如使用自回归语言模型的 GPT 和使用掩码自编码的 BERT,它们的理论都很简单:移除一部分比例的数据然后学习预测移除的数据,通过这种方式可以训练得到包含千亿参数的模型。
第三段作者说在 BERT 之前已经有研究将掩码自编码器(一种通用的去噪声自编码器)用于计算机视觉中。尽管 BERT 取得了很大的成功,但自编码器在计算机视觉的应用落后 NLP。 于是作者提出疑问:what makes masked autoencoding differentbetween vision and language? 作者尝试从三个方面进行回答:
- 二者架构不同,
CNN是在规则的网格上运算,并不好加掩码和位置编码,不过这个问题已经被ViT解决了。 - 视觉和语言的信息密度不同。语言是人类生成的信号,有很高的语义和信息密度。当训练一个模型仅仅对每句话预测少量丢失单词时,任务可以转化成复杂的语言理解问题。相反,图片是有着很多空间冗余的自然信号(一个缺失的块可以由周围的块进行恢复,周围的块包含目标、场景等高级信息)。为了克服这种区别,作者提出了一个简单的策略:
随机mask很大比例的块。为自监督任务提升了难度,超越了低级别图像统计的理解范畴。 - 自编码器的
decoder,在视觉中,decoder重建像素,因此decoder的得到是一个相比于目标识别任务更低语义级别的输出。这与语言不同,语言中预测的缺失单词包含了丰富的语义特征。
导论最后两段作者介绍了 MAE 算法和效果,可以看作是摘要的扩充,作者这里的写法值得一学,通过提出问题,回答问题的方式来引出算法,而且还使用了很多图片,非常加分。

3. 相关工作
下面是论文相关工作部分。作者分别从带掩码的语言模型(BERT、GPT)、自编码(DAE)、掩码图片编码(iGPT、BEiT)、自监督学习(MoCo)四个方面进行了介绍。
4. MAE算法、实验
下面是 MAE 算法部分,算法部分篇幅不长,示意图之前我们已经介绍过了,作者从5个方面进行了介绍。
- Masking:和
ViT一样,我们将图像分割为规则的非重叠patch。然后,采样对patch进行采样,并掩码(即移除)剩余的patch。我们的采样策略很简单:按照均匀分布随机对patch进行采样。具有高掩蔽率的随机采样在很大程度上消除了冗余,因此创建了一个无法通过从可见相邻patch外推来轻松解决的任务,增加了任务的难度,这样高度稀疏的输入可以让我们设计出高效的编码器。 - MAE encoder:编码器使用的是
ViT,但仅对可见的、unmasked的patches进行编码。就像在标准ViT中一样,patches添加位置嵌入后经线性投影得到embedded patches,编码器由一系列transformer block组成;编码器只在一小部分子集上操作(例如25%图像块),使得能够训练非常大的编码器。 - MAE decoder:解码器的输入是编码的可见块和
mask tokens。每个mask token都是一个共享可学习的向量,表示要预测的缺失patch。对集合中的所有tokens添加positional embedding。解码器具有另一系列Transformer块。这个完整集合中的所有tokens添加positional embedding。解码器具有另一系列Transformer模块。解码器仅在预训练期间用于执行图像重构任务。因此,解码器可以独立于编码器设计灵活地设计。作者使用了非常小的解码器进行实验。通过这种非对称设计,所有tokens仅由轻量级解码器处理,这大大减少了预训练时间。 - Reconstruction target:
MAE通过预测每个masked patch的像素值来重构原始图像。解码器输出为表示patch的像素值向量。解码器的最后一层是一个linear projection层,其输出通道的数量等于每个patch中包含的像素数量。和BERT类似,作者只计算了masked patch损失。初次之外,作者还研究了每一个patch的归一化像素值,在实验中能够进一步提高性能。 - Simple implementation:
MAE预训练可以被高效率地实现,并不需要任何专门的稀疏化操作。首先,为每个输入patch生成一个对应token。接下来,我们随机打乱这些token列表,并根据掩码率删除列表的最后一部分。然后对剩下的patch进行编码。编码后,将mask tokens列表附加到已编码的patch列表中,并还原此列表顺序,将所有token目标对齐。解码器对所有tokens进行解码。

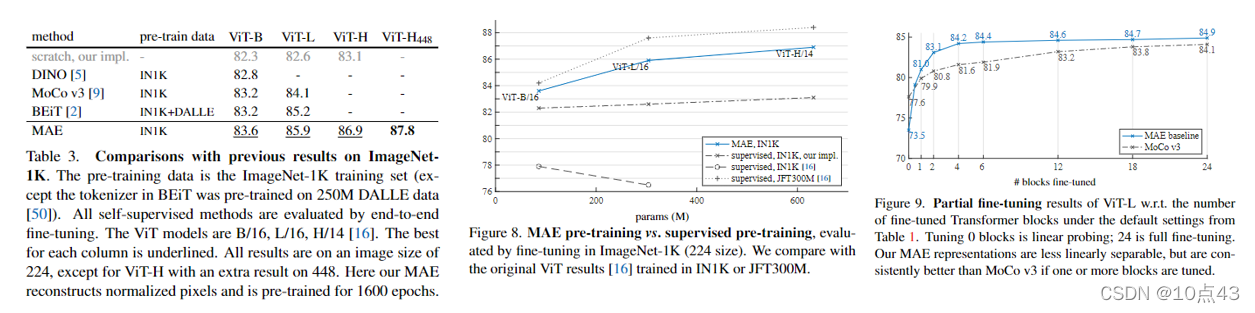
下面是论文实验部分,作者先在 ImageNet-1K 数据上进行了自监督预训练,然后有监督训练时作者分别进行了端到端微调(允许修改整个模型所有的可学习参数)和线性探测(只修改最后一层线性输出层)两种方式训练。作者与 ViT-L-16 进行了对比,实验发现,从头训练 ViT-L 时很强的正则化能够提高 ViT-16 分类性能(比原始 ViT-L 提高了6个百分点)。即使如此,微调的 MAE 只训练了 50个 epochs 就能得到84.9的准确率,这说明微调版的准确率依赖于预训练。

下面是论文消融实验的介绍,默认设置如下表灰色阴影部分所示,作者分析了解码器的深度、解码器宽度、编码器是否使用mask token、重构目标、是否使用数据增强、mask 采样策略 对最终结果的影响。(这一部分就不详细展开了,大家可以去看论文原文)。这里值得注意的是有监督训练时微调模型比线性探测准确率要高,这是一个很重要的结果。

下面是其它消融实验结果,从下图中可以看到,75%的掩码率对线性评估和微调模型都有好处。这与 BERT 相反,BERT中的掩码率为15%。当解码器深度为1时,模型准确率反而还提高了,但是训练速度能够加速4倍左右。

下面是与自监督预训练、有监督预训练的对比以及部分微调的实验。可以看到,MAE 都取得了很好的结果,且有监督预训练发现 MAE 可以帮助扩大模型尺寸。
最后是 迁移学习实验,无论是在目标检测、语义分割、分类,MAE 预训练后的模型都取得了很好的结果。 
整篇文章作者提出的算法很简单,论文结果非常好,而且写作非常流畅,实验很详细,是一篇研究范文。最后,简单总结下为什么 MAE 为什么能取得这么好的效果。主要有三点:
MAE需要盖住更多的块(即掩码率更高),进一步降低了剩余块之间的冗余度,任务变得更复杂;- 使用一个由
Tranformer组成的解码器,直接还原原始图像像素信息,使得整个流程更加简单一点; - 同时作者加上了在
ViT之后各项研究的技术,使得整个模型训练更鲁棒,更容易;
5. MAE 可视化 demo
下面使用作者提供的交互式模型体验下 MAE 的威力。云端Colab 地址为:https://colab.research.google.com/github/facebookresearch/mae/blob/main/demo/mae_visualize.ipynb
首先是导入需要的库和模型:
import sys
import os
import requests
import torch
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
# check whether run in Colab
if 'google.colab' in sys.modules:
print('Running in Colab.')
!pip3 install timm==0.4.5 # 0.3.2 does not work in Colab
!git clone https://github.com/facebookresearch/mae.git
sys.path.append('./mae')
else:
sys.path.append('..')
import models_mae
然后是一些使用到的函数:
# define the utils
imagenet_mean = np.array([0.485, 0.456, 0.406])
imagenet_std = np.array([0.229, 0.224, 0.225])
def show_image(image, title=''):
# image is [H, W, 3]
assert image.shape[2] == 3
plt.imshow(torch.clip((image * imagenet_std + imagenet_mean) * 255, 0, 255).int())
plt.title(title, fontsize=16)
plt.axis('off')
return
def prepare_model(chkpt_dir, arch='mae_vit_large_patch16'):
# build model
model = getattr(models_mae, arch)()
# load model
checkpoint = torch.load(chkpt_dir, map_location='cpu')
msg = model.load_state_dict(checkpoint['model'], strict=False)
print(msg)
return model
def run_one_image(img, model):
x = torch.tensor(img)
# make it a batch-like
x = x.unsqueeze(dim=0)
x = torch.einsum('nhwc->nchw', x)
# run MAE
loss, y, mask = model(x.float(), mask_ratio=0.75)
y = model.unpatchify(y)
y = torch.einsum('nchw->nhwc', y).detach().cpu()
# visualize the mask
mask = mask.detach()
mask = mask.unsqueeze(-1).repeat(1, 1, model.patch_embed.patch_size[0]**2 *3) # (N, H*W, p*p*3)
mask = model.unpatchify(mask) # 1 is removing, 0 is keeping
mask = torch.einsum('nchw->nhwc', mask).detach().cpu()
x = torch.einsum('nchw->nhwc', x)
# masked image
im_masked = x * (1 - mask)
# MAE reconstruction pasted with visible patches
im_paste = x * (1 - mask) + y * mask
# make the plt figure larger
plt.rcParams['figure.figsize'] = [24, 24]
plt.subplot(1, 4, 1)
show_image(x[0], "original")
plt.subplot(1, 4, 2)
show_image(im_masked[0], "masked")
plt.subplot(1, 4, 3)
show_image(y[0], "reconstruction")
plt.subplot(1, 4, 4)
show_image(im_paste[0], "reconstruction + visible")
plt.show()
下面是加载图片(是一只小狐狸):
# load an image
img_url = 'https://user-images.githubusercontent.com/11435359/147738734-196fd92f-9260-48d5-ba7e-bf103d29364d.jpg' # fox, from ILSVRC2012_val_00046145
# img_url = 'https://user-images.githubusercontent.com/11435359/147743081-0428eecf-89e5-4e07-8da5-a30fd73cc0ba.jpg' # cucumber, from ILSVRC2012_val_00047851
img = Image.open(requests.get(img_url, stream=True).raw)
img = img.resize((224, 224))
img = np.array(img) / 255.
assert img.shape == (224, 224, 3)
# normalize by ImageNet mean and std
img = img - imagenet_mean
img = img / imagenet_std
plt.rcParams['figure.figsize'] = [5, 5]
show_image(torch.tensor(img))

加载 MAE 预训练模型,文件大小有点大(1.2G左右):
# This is an MAE model trained with pixels as targets for visualization (ViT-Large, training mask ratio=0.75)
# download checkpoint if not exist
!wget -nc https://dl.fbaipublicfiles.com/mae/visualize/mae_visualize_vit_large.pth
chkpt_dir = 'mae_visualize_vit_large.pth'
model_mae = prepare_model(chkpt_dir, 'mae_vit_large_patch16')
print('Model loaded.')
下面运行模型,观察效果:
# make random mask reproducible (comment out to make it change)
torch.manual_seed(2)
print('MAE with pixel reconstruction:')
run_one_image(img, model_mae)

下面是另一个 MAE预训练模型,使用了 GAN loss,效果会更好一些:
# This is an MAE model trained with an extra GAN loss for more realistic generation (ViT-Large, training mask ratio=0.75)
# download checkpoint if not exist
!wget -nc https://dl.fbaipublicfiles.com/mae/visualize/mae_visualize_vit_large_ganloss.pth
chkpt_dir = 'mae_visualize_vit_large_ganloss.pth'
model_mae_gan = prepare_model('mae_visualize_vit_large_ganloss.pth', 'mae_vit_large_patch16')
print('Model loaded.')
# make random mask reproducible (comment out to make it change)
torch.manual_seed(2)
print('MAE with extra GAN loss:')
run_one_image(img, model_mae_gan)
















 3079
3079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









