






入门代码demo:本地搭建AI智能应用
Autogen简介
- 官网:Redirecting...
- git:http://github.com/microsoft/autogen
- discord:https://discord.com/invite/pAbnFJrkgZ
- 入门介绍
AutoGen 是一个框架,它支持使用多个智能体开发 LLM 应用程序,这些智能体可以相互交谈以解决任务。AutoGen 智能体是可定制的、可对话的,并且无缝地允许人工参与。它们可以在各种模式下运行,这些模式采用 LLM、人工输入和工具的组合。
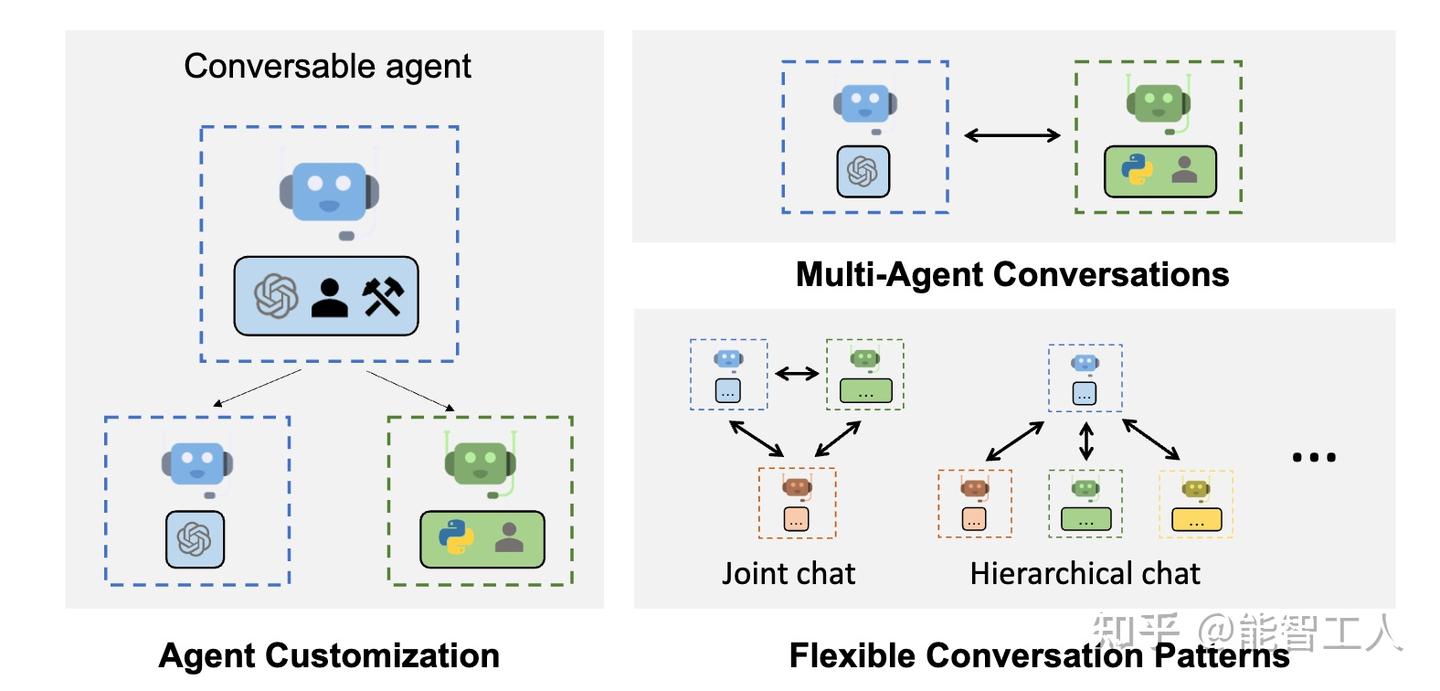
1.1.1 主要特点
- AutoGen 能够以最小的工作量构建基于多智能体对话的下一代 LLM 应用程序。它简化了复杂 LLM 工作流的编排、自动化和优化。它最大限度地提高了LLM模型的性能并克服了它们的弱点。
- 它支持复杂工作流程的多种对话模式。借助可自定义和可对话的智能体,开发人员可以使用 AutoGen 构建有关对话自治的各种对话模式, 代理数和智能体会话拓扑。
- 它提供了具有不同复杂性的工作系统的集合。这些系统涵盖了来自各个领域和复杂性的广泛应用。这演示了 AutoGen 如何轻松支持各种对话模式。
- AutoGen 提供增强的 LLM 推理。它提供了 API 统一和缓存等实用程序,以及错误处理、多配置推理、上下文编程等高级使用模式。
AutoGen由Microsoft,宾夕法尼亚州立大学和华盛顿大学的合作研究提供支持。
1.1.2 快速入门
从 pip: 安装。在安装中查找更多选项。 对于代码执行,我们强烈建议安装 python docker 包,并使用 docker。pip install pyautogen
1.1.2.1 多智能体对话框架
Autogen 通过通用的多智能体对话框架支持下一代 LLM 应用程序。它提供了可定制和可对话的代理,集成了 LLM、工具和人类。 通过在多个有能力的代理之间自动聊天,可以轻松地让他们自主地集体执行任务或通过人工反馈执行任务,包括需要通过代码使用工具的任务。例如,
| Pythonfrom autogen import AssistantAgent, UserProxyAgent, config_list_from_json# Load LLM inference endpoints from an env variable or a file# See https://microsoft.github.io/autogen/docs/FAQ#set-your-api-endpoints# and OAI_CONFIG_LIST_sample.jsonconfig_list = config_list_from_json(env_or_file="OAI_CONFIG_LIST")assistant = AssistantAgent("assistant", llm_config={"config_list": config_list})user_proxy = UserProxyAgent("user_proxy", code_execution_config={"work_dir": "coding", "use_docker": False}) # IMPORTANT: set to True to run code in docker, recommendeduser_proxy.initiate_chat(assistant, message="Plot a chart of NVDA and TESLA stock price change YTD.")# This initiates an automated chat between the two agents to solve the task |
|---|
下图显示了使用 AutoGen 的示例对话流。
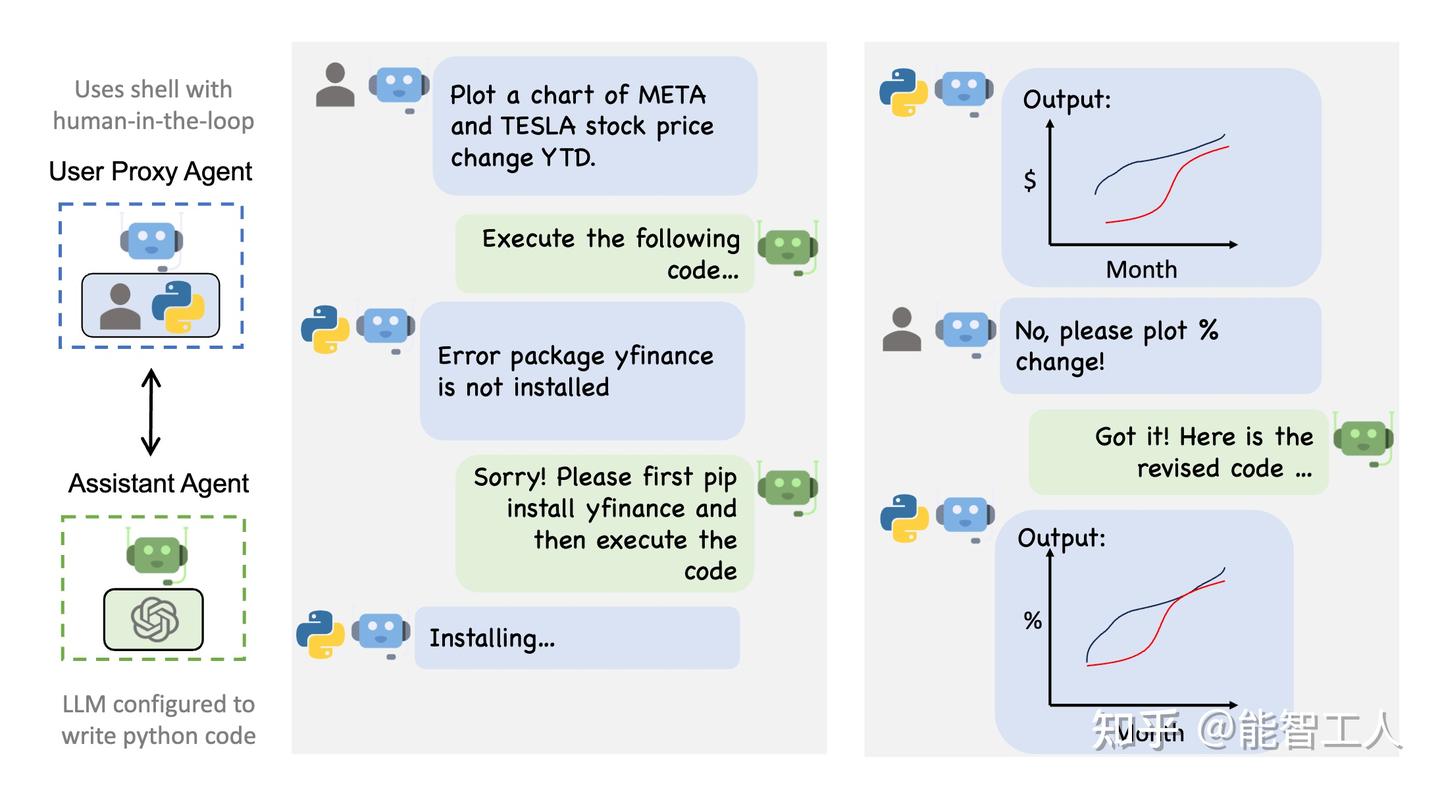
1.1.2.2 增强的 LLM 推理
Autogen还可以帮助充分发挥高成本的LLM(如ChatGPT和GPT-4)的效用。它提供了增强的LLM推理功能,包括调整、缓存、错误处理和模板化。例如,您可以通过使用自己的调整数据、成功指标和预算来优化通过LLM生成的内容。
| Python# perform tuning for openai<1config, analysis = autogen.Completion.tune( data=tune_data, metric="success", mode="max", eval_func=eval_func, inference_budget=0.05, optimization_budget=3, num_samples=-1,)# perform inference for a test instanceresponse = autogen.Completion.create(context=test_instance, **config) |
|---|
- 代码示例。
2. 使用案例
2.1 多智能体对话框架
AutoGen提供了一个统一的多智能体对话框架,作为使用基础模型的高级抽象。它提供了功能强大、可定制和可对话的智能体,通过自动代理聊天,将LLMs、工具和人类整合在一起。通过自动化多个功能强大的智能体之间的聊天,可以使它们集体自主地执行任务或接受人类反馈,包括需要通过代码使用工具的任务。
该框架简化了复杂LLM工作流的编排、自动化和优化。它最大限度地提高了LLM模型的性能,并克服了它们的弱点。它使得基于多代理对话构建下一代LLM应用变得轻松简单。
2.1.1 智能体
AutoGen 抽象并实现可转换智能体,旨在通过座席间对话解决任务。具体而言,AutoGen 中的智能体具有以下显著特征:
- 可对话:AutoGen 中的智能体是可对话的,这意味着任何智能体都可以发送并接收来自其他座席的消息以发起或继续对话
- 可定制:AutoGen 中的智能体可以自定义以集成 LLM、人员、工具或它们的组合。
下图显示了 AutoGen 中的内置智能体。
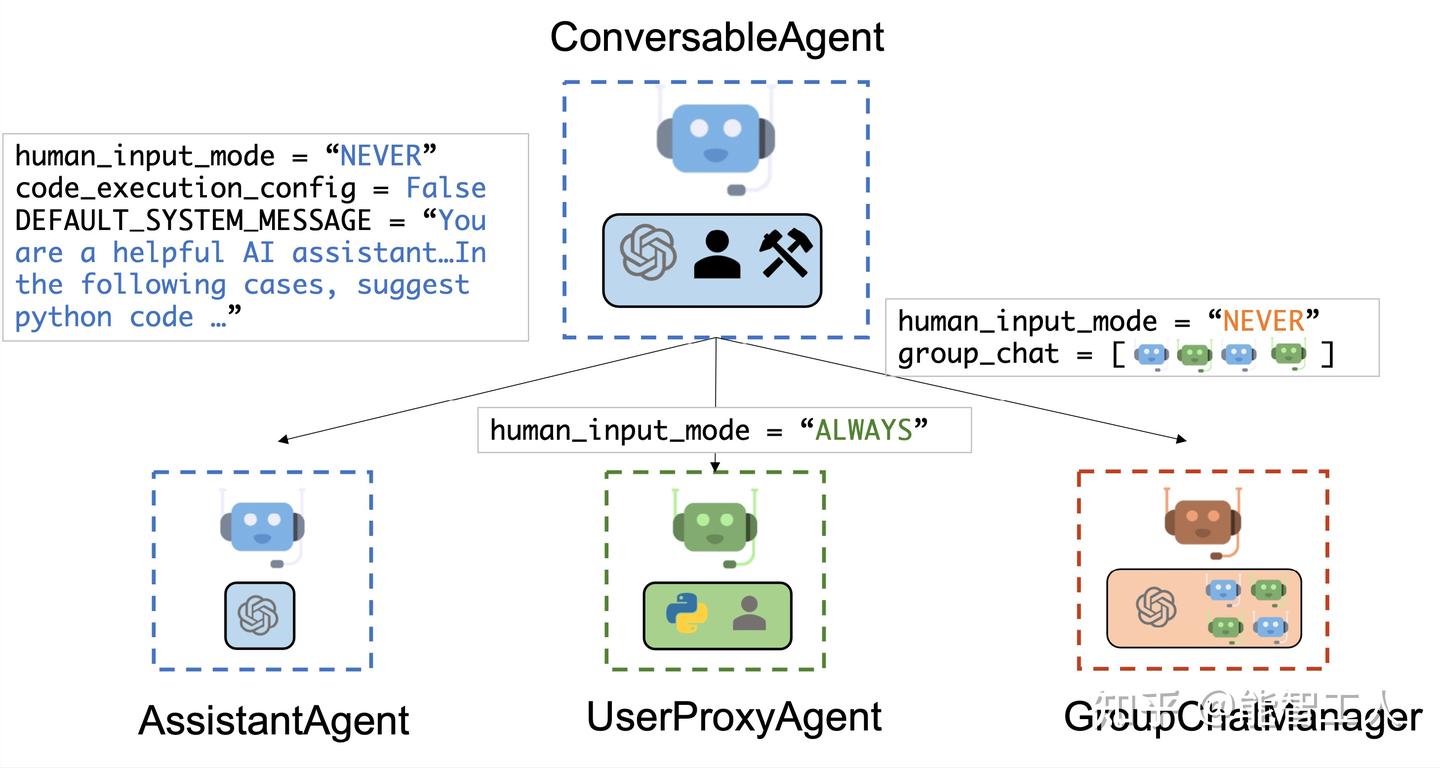
我们为智能体设计了一个通用的 ConversableAgent 类,这些类能够通过交换消息相互交谈以共同完成任务。智能体可以与其他智能体通信并执行操作。不同的智能体在收到消息后执行的操作可能有所不同。两个具有代表性的子类是 AssistantAgent 和 UserProxyAgent
- AssistantAgent 被设计为充当 AI 助手,默认使用 LLM,但不需要人工输入或代码执行。它可以编写 Python 代码(在 Python 编码块中),供用户在收到消息(通常是需要解决的任务的描述)时执行。在后台,Python 代码由 LLM(例如 GPT-4)编写。它还可以接收执行结果并提出更正或错误修复建议。可以通过传递新的系统消息来更改其行为。LLM 推理配置可以通过 [llm_config] 进行配置。
- UserProxyAgent 在概念上是人类的代理智能体,默认情况下,在每次交互时征求人工输入作为智能体的回复,并且还具有执行代码和调用函数或工具的能力。当 UserProxyAgent 在收到的消息中检测到可执行代码块并且未提供人工用户输入时,它会自动触发代码执行。可以通过将参数设置为 False 来禁用代码执行。默认情况下,基于 LLM 的响应处于禁用状态。可以通过llm_config设置为与推理配置相对应的字典来启用它。当llm_config设置为字典时,UserProxyAgent 可以在未执行代码执行时使用 LLM 生成回复。
ConversableAgent 的自动回复功能允许更自主的多智能体通信,同时保留人工干预的可能性。 还可以通过使用 register_reply() 方法注册回复函数来轻松扩展它。
在下面的代码中,我们创建一个名为“assistant”的 AssistantAgent 作为助手,并创建一个名为“user_proxy”的 UserProxyAgent 作为人类用户的代理。我们稍后将使用这两个代理来解决一项任务。
| Pythonfrom autogen import AssistantAgent, UserProxyAgent# create an AssistantAgent instance named "assistant"assistant = AssistantAgent(name="assistant")# create a UserProxyAgent instance named "user_proxy"user_proxy = UserProxyAgent(name="user_proxy") |
|---|
2.1.1.1 工具调用
工具调用使智能体能够更高效地与外部工具和API进行交互。这个功能允许AI模型智能选择输出一个包含调用基于用户的输入特定工具参数的JSON对象。被调用的工具由描述其参数及其类型的JSON模式指定。编写这样的JSON模式是复杂且容易出错的,这就是为什么AutoGen框架提供了两个高级函数装饰器,用于使用标准Python数据类型或Pydantic模型的类型提示自动生成这样的模式:
- ConversableAgent.register_for_llm用于将函数注册为 ConversableAgent 中的 Tool。ConversableAgent 智能体可以建议执行已注册的工具,但实际执行将由 UserProxy 智能体执行。
- ConversableAgent.register_for_execution用于在 UserProxy 智能体中注册函数。function_map
以下示例演示了使用类型提示和标准 Python 数据类型的货币兑换计算注册自定义函数的过程:
- 首先,我们导入必要的库并使用autogen.config_list_from_json函数配置模型:
| Pythonfrom typing import Literalfrom pydantic import BaseModel, Fieldfrom typing_extensions import Annotatedimport autogenconfig_list = autogen.config_list_from_json( "OAI_CONFIG_LIST", filter_dict={ "model": ["gpt-4", "gpt-3.5-turbo", "gpt-3.5-turbo-16k"], },) |
|---|
- 我们创建一个助理智能体和用户代理。助手将负责建议调用哪些函数,而用户代理以实际执行的功能:
| Pythonllm_config = { "config_list": config_list, "timeout": 120,}chatbot = autogen.AssistantAgent( name="chatbot", system_message="For currency exchange tasks, only use the functions you have been provided with. Reply TERMINATE when the task is done.", llm_config=llm_config,)# create a UserProxyAgent instance named "user_proxy"user_proxy = autogen.UserProxyAgent( name="user_proxy", is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("TERMINATE"), human_input_mode="NEVER", max_consecutive_auto_reply=10,) |
|---|
- 我们定义下面的currency_calculator函数如下,并用两个装饰器来装饰它:
- @user_proxy.register_for_execution() 将currency_calculator函数添加到currency_calculatoruser_proxy.function_map中,然后
- @chatbot.register_for_llm 将函数生成的 JSON 架构添加到 chatbot的 llm_config中。
| PythonCurrencySymbol = Literal["USD", "EUR"]def exchange_rate(base_currency: CurrencySymbol, quote_currency: CurrencySymbol) -> float: if base_currency == quote_currency: return 1.0 elif base_currency == "USD" and quote_currency == "EUR": return 1 / 1.1 elif base_currency == "EUR" and quote_currency == "USD": return 1.1 else: raise ValueError(f"Unknown currencies {base_currency}, {quote_currency}")# NOTE: for Azure OpenAI, please use API version 2023-12-01-preview or later as# support for earlier versions will be deprecated.# For API versions 2023-10-01-preview or earlier you may# need to set `api_style="function"` in the decorator if the default value does not work:# `register_for_llm(description=..., api_style="function")`.@user_proxy.register_for_execution()@chatbot.register_for_llm(description="Currency exchange calculator.")def currency_calculator( base_amount: Annotated[float, "Amount of currency in base_currency"], base_currency: Annotated[CurrencySymbol, "Base currency"] = "USD", quote_currency: Annotated[CurrencySymbol, "Quote currency"] = "EUR",) -> str: quote_amount = exchange_rate(base_currency, quote_currency) * base_amount return f"{quote_amount} {quote_currency}" |
|---|
请注意,使用 Annotated 来指定每个参数的类型和说明。函数的返回值必须是字符串,或者可以使用 json.dumps() 或 Pydantic 模型转储到 JSON(支持版本 1.x 和 2.x)序列化为字符串。
您可以检查chatbot.llm_config["tools"]装饰器生成的 JSON 架构:
| Python[{'type': 'function', 'function': {'description': 'Currency exchange calculator.', 'name': 'currency_calculator', 'parameters': {'type': 'object', 'properties': {'base_amount': {'type': 'number', 'description': 'Amount of currency in base_currency'}, 'base_currency': {'enum': ['USD', 'EUR'], 'type': 'string', 'default': 'USD', 'description': 'Base currency'}, 'quote_currency': {'enum': ['USD', 'EUR'], 'type': 'string', 'default': 'EUR', 'description': 'Quote currency'}}, 'required': ['base_amount']}}}]4. |
|---|
- 代理现在可以按如下方式使用该功能:
| Pythonuser_proxy.initiate_chat( chatbot, message="How much is 123.45 USD in EUR?",) |
|---|
输出:
| Pythonuser_proxy (to chatbot):How much is 123.45 USD in EUR?--------------------------------------------------------------------------------chatbot (to user_proxy):***** Suggested tool Call: currency_calculator *****Arguments:{"base_amount":123.45,"base_currency":"USD","quote_currency":"EUR"}********************************************************-------------------------------------------------------------------------------->>>>>>>> EXECUTING FUNCTION currency_calculator...user_proxy (to chatbot):***** Response from calling function "currency_calculator" *****112.22727272727272 EUR****************************************************************--------------------------------------------------------------------------------chatbot (to user_proxy):123.45 USD is equivalent to approximately 112.23 EUR....TERMINATE |
|---|
使用 Pydantic 模型进一步简化了此类函数的编写。可以使用 Pydantic 模型用于函数的参数及其返回类型。此类函数的参数将 由 AI 模型提供的 JSON 构造,而输出将序列化为 JSON 自动编码字符串。
下面的例子展示了我们如何重写我们的货币兑换计算器示例:
| Python# defines a Pydantic modelclass Currency(BaseModel): # parameter of type CurrencySymbol currency: Annotated[CurrencySymbol, Field(..., description="Currency symbol")] # parameter of type float, must be greater or equal to 0 with default value 0 amount: Annotated[float, Field(0, description="Amount of currency", ge=0)]@user_proxy.register_for_execution()@chatbot.register_for_llm(description="Currency exchange calculator.")def currency_calculator( base: Annotated[Currency, "Base currency: amount and currency symbol"], quote_currency: Annotated[CurrencySymbol, "Quote currency symbol"] = "USD",) -> Currency: quote_amount = exchange_rate(base.currency, quote_currency) * base.amount return Currency(amount=quote_amount, currency=quote_currency) |
|---|
生成的 JSON 架构具有其他属性,例如编码的最小值:
| Python[{'type': 'function', 'function': {'description': 'Currency exchange calculator.', 'name': 'currency_calculator', 'parameters': {'type': 'object', 'properties': {'base': {'properties': {'currency': {'description': 'Currency symbol', 'enum': ['USD', 'EUR'], 'title': 'Currency', 'type': 'string'}, 'amount': {'default': 0, 'description': 'Amount of currency', 'minimum': 0.0, 'title': 'Amount', 'type': 'number'}}, 'required': ['currency'], 'title': 'Currency', 'type': 'object', 'description': 'Base currency: amount and currency symbol'}, 'quote_currency': {'enum': ['USD', 'EUR'], 'type': 'string', 'default': 'USD', 'description': 'Quote currency symbol'}}, 'required': ['base']}}}] |
|---|
有关更深入的示例,请查看以下内容:
- 货币计算器示例 - View Notebook
- 将提供的工具用作功能 - View Notebook
- 通过同步和异步函数调用使用工具 - 查看笔记本
2.1.2 多智能体对话
2.1.2.1 一个基本的双智能体对话示例
正确构造智能体后,可以通过初始化步骤启动多智能体对话会话,如以下代码所示:
| Python# the assistant receives a message from the user, which contains the task descriptionuser_proxy.initiate_chat( assistant, message="""What date is today? Which big tech stock has the largest year-to-date gain this year? How much is the gain?""",) |
|---|
初始化步骤后,对话可以自动进行。在下面找到user_proxy和助手如何自主协作解决上述任务的视觉说明:

- 助手接收到来自 user_proxy 的消息,其中包含任务描述。
- 然后助手尝试编写 Python 代码来解决任务,并将响应发送给 user_proxy。
- 一旦 user_proxy 从助手那里收到响应,它会尝试通过征求人类输入或准备自动生成的回复来回复。如果没有提供人类输入,user_proxy 将执行代码并使用结果作为自动回复。
- 然后助手为 user_proxy 生成进一步的响应。然后 user_proxy 可以决定是否终止对话。如果不是,就重复步骤 3 和 4。
2.1.2.2 支持多样化的对话模式
2.1.2.2.1 具有不同自主程度和人类参与模式的对话
和人类参与模式的对话
一方面,可以在初始化步骤后实现完全自主的对话。另一方面,AutoGen 可用于通过配置人类参与水平和模式(例如,将 human_input_mode 设置为 ALWAYS)来实现人在循环中的问题解决,因为在许多应用中都期望和/或需要人类参与。
2.1.2.2.2 静态和动态对话
通过采用以对话为驱动的控制,结合编程语言和自然语言,AutoGen 本质上允许动态对话。动态对话允许代理拓扑根据不同输入问题实例下的实际对话流程而变化,而静态对话的流程总是遵循预定义的拓扑。在复杂应用中,交互模式无法预先确定,动态对话模式非常有用。AutoGen 提供了两种实现动态对话的通用方法:
- 注册自动回复。通过可插拔的自动回复功能,可以选择根据当前消息和上下文的内容与其他智能体进行对话。在这个代码示例中,我们在群聊管理器中注册了一个自动回复功能,让 LLM 决定谁将是群聊设置中的下一个发言者。
- 基于 LLM 的函数调用。在这种方法中,LLM 根据每次推理调用中的对话状态决定是否调用特定函数。 通过在被调用的函数中向其他代理发送消息,LLM 可以驱动动态多智能体对话。在 多用户数学问题解决场景 中,可以找到展示这种类型动态对话的工作系统,其中学生助手会自动求助于专家使用函数调用。
2.1.2.3 LLM 缓存
从版本0.2.8开始,可配置的上下文管理器允许您轻松配置LLM缓存,可以使用DiskCache或Redis。上下文管理器中的所有智能体将使用相同的缓存
| Pythonfrom autogen import Cache# Use Redis as cachewith Cache.redis(redis_url="redis://localhost:6379/0") as cache: user.initiate_chat(assistant, message=coding_task, cache=cache)# Use DiskCache as cachewith Cache.disk() as cache: user.initiate_chat(assistant, message=coding_task, cache=cache) |
|---|
您可以通过更改cache_seed参数来得到不同的LLM输出,同时仍然使用缓存.
| Python# Setting the cache_seed to 1 will use a different cache from the default one# and you will see different output.with Cache.disk(cache_seed=1) as cache: user.initiate_chat(assistant, message=coding_task, cache=cache) |
|---|
默认情况下,DiskCache 使用.cache来存储。要更改缓存目录, 设置cache_path_root:
| Pythonwith Cache.disk(cache_path_root="/tmp/autogen_cache") as cache: user.initiate_chat(assistant, message=coding_task, cache=cache) |
|---|
为了向后兼容,智能体默认启用了缓存,并将缓存种子设置为41。如果想要完全禁用缓存,请在智能体的llm_config中将缓存种子设置为None。
| Pythonassistant = AssistantAgent( "coding_agent", llm_config={ "cache_seed": None, "config_list": OAI_CONFIG_LIST, "max_tokens": 1024, },) |
|---|
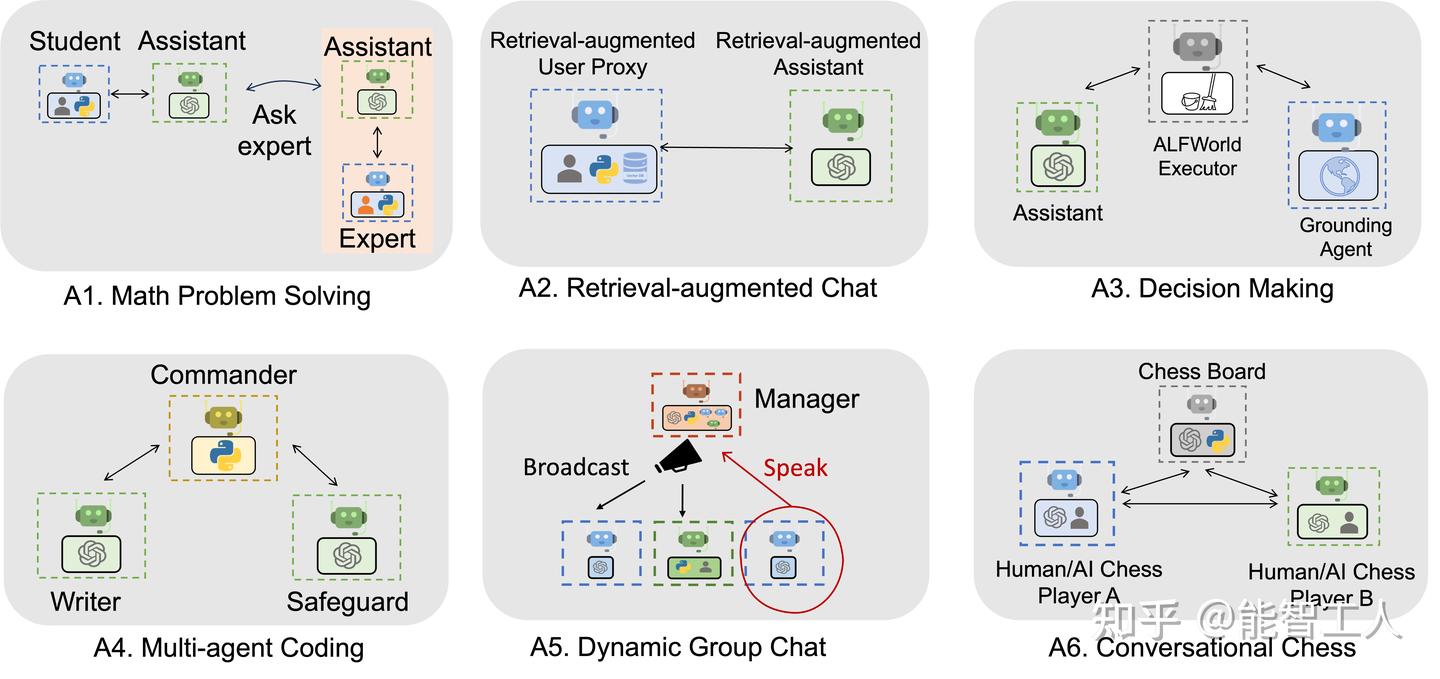
2.1.3 使用 AutoGen 实现的各种应用
下图显示了使用 AutoGen 构建的 6 个应用程序示例。
2.2 AutoGen 增强推理
autogen.OpenAIWrapper 为 openai>=1 提供了增强的大型语言模型(LLM)推理功能。 autogen.Completion 是 openai.Completion 和 openai.ChatCompletion 的替代品,用于使用 openai<1 进行增强的 LLM 推理。 使用 autogen 进行推理有许多好处:性能调优、API 统一、缓存、错误处理、多配置推理、结果过滤、模板化等。
2.2.1 调优推理参数(针对 openai < 1)
笔记本示例链接:
2.2.2 优化选择
使用基础模型进行文本生成的成本通常以输入和输出中的令牌数量来衡量。从使用基础模型的应用程序构建者的角度来看,用例是在推理预算约束下(例如,通过解决编码问题所需的平均美元成本来衡量)最大化生成文本的效用。这可以通过优化推理的超参数来实现,这些超参数可以显著影响生成文本的效用和成本。
可调节的超参数包括:
- model - 这是一个必需的输入,指定要使用的模型 ID。
- prompt/messages - 模型的输入提示/消息,为文本生成任务提供上下文。
- max_tokens - 在输出中生成的最大令牌(单词或单词片段)数量。
- temperature - 一个介于 0 和 1 之间的值,控制生成文本的随机性。较高的温度将产生更随机和多样的文本,而较低的温度将产生更可预测的文本。
- top_p - 一个介于 0 和 1 之间的值,控制每次令牌生成的采样概率质量。较低的 top_p 值将使基于最可能的令牌生成文本的可能性更大,而较高的值将允许模型探索更广泛的可能令牌范围。
- n - 为给定提示生成的响应数量。生成多个响应可以提供更多样化和潜在更有用的输出,但也会增加请求的成本。
- stop - 一个字符串列表,当在生成的文本中遇到时,将导致生成停止。这可以用来控制输出的长度或有效性。
- presence_penalty, frequency_penalty - 控制生成文本中某些词或短语的出现和频率相对重要性的值。
- best_of - 为给定提示生成的响应数量,服务器端在选择“最佳”(每个令牌的对数概率最高的)响应时。
文本生成的成本和效用与这些超参数的联合效应交织在一起。 这些超参数之间也存在复杂的相互作用。例如,不建议同时更改温度和 top_p,因为它们都控制生成文本的随机性,同时更改可能会产生冲突的效果;n 和 best_of 很少一起调整,因为如果应用程序可以处理多个输出,服务器端的过滤会导致不必要的信息损失;n 和 max_tokens 都会影响生成的总令牌数量,进而影响请求的成本。 这些相互作用和权衡使得手动确定给定文本生成任务的最佳超参数设置变得困难。
选择是否重要?查看这篇 博客文章 找到关于 gpt-3.5-turbo 和 gpt-4 的示例调优结果。
使用 AutoGen,可以根据以下信息进行调优:
- 验证数据。
- 评估函数。
- 要优化的指标。
- 搜索空间。
- 预算:推理和优化分别。
2.2.3 验证数据
收集多样化的实例集合。它们可以存储在一个字典的可迭代集合中。例如,每个实例字典可以包含“问题”作为键和数学问题描述字符串作为值;以及“解决方案”作为键和解决方案字符串作为值。
2.2.4 评估函数
评估函数应该接受一个响应列表,并且对应于每个验证数据实例中的键的其他关键字参数作为输入,并输出一个度量字典。例如,
| Pythondef eval_math_responses(responses: List[str], solution: str, **args) -> Dict: # 从响应列表中选择一个响应 answer = voted_answer(responses) # 检查答案是否正确 return {"success": is_equivalent(answer, solution)} |
|---|
autogen.code_utils 和 autogen.math_utils 提供了一些代码生成和数学问题解决的示例评估函数。
2.2.5 要优化的指标
通常要优化的指标是对所有调优数据实例的聚合度量。例如,用户可以指定“成功”作为度量和“最大”作为优化模式。默认情况下,聚合函数是取平均值。如果需要,用户可以提供自定义的聚合函数。
2.2.6 搜索空间
用户可以指定每个超参数的(可选)搜索范围。
- model。要么是一个常量字符串,要么是由 flaml.tune.choice 指定的多个
选择。
- prompt/messages。提示是一个字符串或字符串列表,消息是字典列表或列表列表,模板化的提示/消息。 每个提示/消息模板将与每个数据实例格式化。例如,提示模板可以是: "{problem} Solve the problem carefully. Simplify your answer as much as possible. Put the final answer in \boxed{ {}}." 并且 {problem} 将被每个数据实例的“问题”字段替换。
- max_tokens, n, best_of。它们可以是常量,或者由 flaml.tune.randint, flaml.tune.qrandint, flaml.tune.lograndint 或 flaml.qlograndint 指定。默认情况下,max_tokens 在 [50, 1000) 中搜索;n 在 [1, 100) 中搜索;best_of 固定为 1。
- stop。它可以是一个字符串或字符串列表,或者是字符串列表的列表或 None。默认为 None。
- temperature 或 top_p。其中一个可以被指定为常量或通过 flaml.tune.uniform 或 flaml.tune.loguniform 等指定。 请不要同时提供两者。默认情况下,每个配置将在 [0, 1] 中均匀选择温度或 top_p。
- presence_penalty, frequency_penalty。它们可以是常量或由 flaml.tune.uniform 等指定。默认情况下不进行调整。
2.2.7 预算
可以指定推理预算和优化预算。 推理预算指的是每个数据实例的平均推理成本。 优化预算指的是调优过程中允许的总预算。两者都以美元计量,并遵循每 1000 个令牌的价格。
2.2.8 执行调优
现在,你可以使用 autogen.Completion.tune 进行调优。例如,
| Pythonimport autogenconfig, analysis = autogen.Completion.tune( data=tune_data, metric="success", mode="max", eval_func=eval_func, inference_budget=0.05, optimization_budget=3, num_samples=-1,) |
|---|
num_samples 是要采样的配置数量。-1 表示无限制(直到优化预算耗尽)。 返回的 config 包含优化后的配置,analysis 包含一个 ExperimentAnalysis 对象,用于所有尝试过的配置和结果。
调优后的配置可以用来执行推理。
2.2.9 执行推理
使用调优后的配置,可以执行推理以生成文本。例如,
| Pythonimport autogen# 使用优化后的配置生成文本response = autogen.Completion.create( model=config["model"], prompt=config["prompt"], max_tokens=config["max_tokens"], temperature=config["temperature"], top_p=config["top_p"], n=config["n"], stop=config["stop"], presence_penalty=config["presence_penalty"], frequency_penalty=config["frequency_penalty"], best_of=config["best_of"],) |
|---|
在这个例子中,config 字典包含了调优过程中确定的最佳超参数值。这些值被用来设置 autogen.Completion.create 方法的参数,从而生成文本。
2.2.10 分析结果
analysis 对象提供了对调优过程的深入了解。可以使用它来检查不同配置的性能,找出最佳和最差的表现配置,以及它们的特定超参数值。例如,
| Python# 获取所有尝试过的配置和它们的性能df = analysis.dataframe()# 找出表现最好的配置best_config = df[df["success"] == df["success"].max()]# 找出表现最差的配置worst_config = df[df["success"] == df["success"].min()]# 分析不同超参数对成功率的影响import matplotlib.pyplot as pltplt.plot(df["temperature"], df["success"], 'o', label='Temperature vs Success')plt.plot(df["top_p"], df["success"], 'x', label='Top P vs Success')plt.legend()plt.show() |
|---|
这些代码片段提供了如何使用 autogen 库进行调优和推理的基本框架。它们可以根据具体的应用场景和需求进行调整和扩展。
2.2.11 总结
AutoGen 提供了一个强大的工具集,用于优化大型语言模型的推理过程。通过精细调整超参数,可以在保持成本效率的同时最大化模型的性能。调优和推理的集成方法使得从数据收集到模型部署的整个流程更加流畅和高效。

















 2120
2120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









