







 这篇博客介绍了DexYCB数据集,它包含大量RGB-D帧,记录了手与10种物体交互的1000个序列,用于2D/3D检测和6D姿态估计,还探讨了机器人安全抓取的新任务。通过8相机系统收集,人工精细标注关键点和3D姿态,对比现有数据集,推动了交互场景下的研究进展。
这篇博客介绍了DexYCB数据集,它包含大量RGB-D帧,记录了手与10种物体交互的1000个序列,用于2D/3D检测和6D姿态估计,还探讨了机器人安全抓取的新任务。通过8相机系统收集,人工精细标注关键点和3D姿态,对比现有数据集,推动了交互场景下的研究进展。

以下内容均为个人理解,如有误敬请谅解。
论文链接:https://dex-ycb.github.io/assets/chao_cvpr2021.pdf
代码链接:https://github.com/NVlabs/dex-ycb-toolkit
数据集链接:https://dex-ycb.github.io/
Abstract
该文章介绍了一个新的数据集,该数据集获取了人手抓取物体的数据集,并将该数据集应用到了2D对象和关键点检测,6D对象姿态估计和3D手姿态估计等任务中。最后,我们评估了一个新的机器人相关任务:在人机对象切换中生成安全的机器人抓取。
Introduction
在交互作用存在的情况下,由于物体的运动和交互产生的相互遮挡,同时解决这两个任务的挑战不仅加倍,而且成倍增加。因此,在任何一个数据集上训练的网络都不能很好地推广到交互场景。
在该文章中,作者想要手机无标记的真实手与物体交互的数据,构建一个从多个视图同步记录交互的多摄像机的平台。其中数据集的标注使用人工标注,该数据集,DexYCB,包括从8个不同的视角记录了582K RGB-D帧超过1000个序列的10个对象抓取20个不同的物体。如下图。

该文章的贡献点主要有三点:
- 引入了一个新的抓取数据集。该数据集相较之前的数据集有很大的优势;
- 深入分析了当前的方法通过以下三个任务:2D目标和关键点检测,6D姿态估计,3D手势姿态估计;
- 证明了关节手和物体姿态估计在机器人相关的新任务:生成安全的机器人抓取,用于人-机对象切换中。
Constructing DexYCB
硬件设定
多相机设置如下图所示。我们使用8个RGB-D摄像头(RealSense D415),并将它们安装在一起,这样它们就可以在最小盲点的情况下捕捉桌面工作空间。
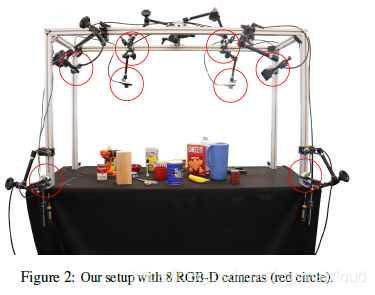
以30fps记录了八个视角的RGB图片和深度图,分辨率为640*480。
数据收集和标注
收集
使用YCB数据集中的20个物体,记录了10个物体的多个实验。对于每一个实验,选取了一个目标物体和其他的2-4个物体,将这些放在桌面上,然后要求实验者以一个放松的姿态开始去捡起目标物体,然后放在空中。同时也要求一些受试者假装将这个物体交给旁边的人。记录过程超过三秒,足以保证完整动作的完成,对于每个目标物体做无此实验,每次都有一个随机的物体位置和随机的物体组合(一个目标物体和多个无关物体)。实验要求受试者在前两次实验中用右手捡起物体,在乎两次实验中用左手捡起物体,最后一次随机。所有20个物体均作了实验,每个物体总共有100次实验,所有的物体会有1000次实验。
标注
为了得到准确的3D姿态,在每个视角的图像中人工标注2D姿态。对于手,我们采用预先定义的21个手关节作为我们的关键点(3个关节加上每个手指和手腕的1个指尖)。我们明确地要求注释器在给定的视频序列中标记和跟踪这些关节。当一个关键点被遮挡时,注释器也被要求在给定的帧中将其标记为不可见。具体来说,给定一个特定视图中的视频序列,首先要求注释者在指定对象上找到两个容易识别和跟踪的独特地标点,然后要求他们在整个序列中标记和跟踪这些点。要求注释器找到大多数时候可见的关键点,无论何时这些点被遮挡,那么这个关节点就是不可见的。
3D手和物体的pose
手的3Dpose
对于手的3Dpose使用Mano手的模型来表示,包含51维的姿态参数和10维的形状参数,这些参数可表示一个778个顶点的网格模型,最终可以从顶点中回归21个关键点也就是姿态。
物体的pose
对于每个3D物体,使用标准的6D姿态表示,具有纹理映射,每个物体表示为一个旋转矩阵和一个平移向量的组合矩阵。
手和物体的pose
为了解决手和物体的姿态,我们通过利用来自所有视图和多视图几何的深度和关键点注释,形成了一个优化问题。对于每一个给定序列,包含H个手和O个物体,定义在世界坐标系下的姿态,因为知道每一个相机的内参。所以Pose就是最小化下面的能量函数:
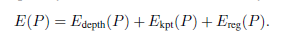
深度
深度的部分测量给定pose得到的深度数据的准确与否。
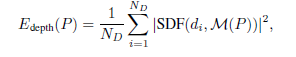
这里的d是指从所有视角的深度图采样的点转换到世界坐标系下的点。SDF代表从mesh到3D点的有符号距离值,这里的操作均是可微的。
关键点
关键点衡量模型标注的关键点的重投影误差。
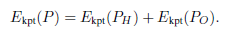
将标注的3D关键点投影到各个视角上去,八个视角,21个关键点,能量函数可定义为:
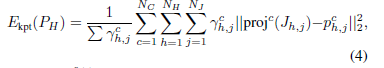
对于每一个物体,而是要求注释器选择要跟踪的独特点。这里,假设在物体的关键点被标记为可见的第一帧给出了一个准确的初始姿态。然后通过将关键点的位置反向投影到对象的可见表面,将选定的关键点映射到对象的3D模型上的一个顶点。
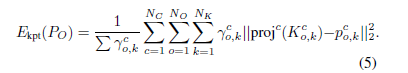
正则化
增加了L2损失去控制形状参数。
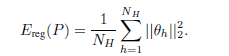
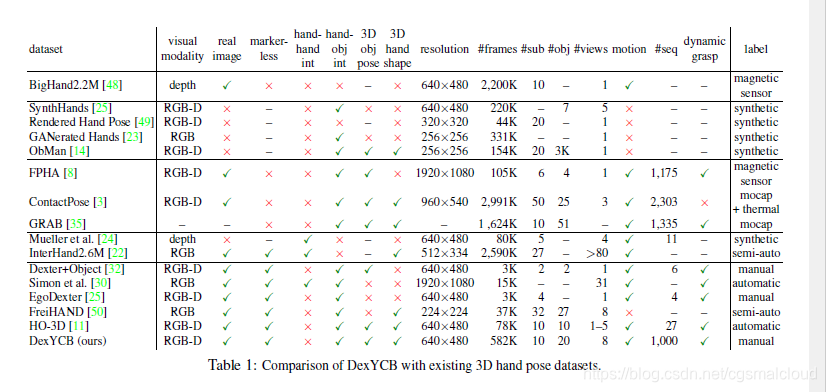
和其他数据集的比较


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









