










 本文深入解析LSTM(长短期记忆网络)的工作原理及其在解决RNN(循环神经网络)梯度消失问题上的应用。介绍了LSTM的四个核心组件——遗忘门、输入门、细胞状态更新及输出门,并详细阐述了其前向传播与反向传播算法。
本文深入解析LSTM(长短期记忆网络)的工作原理及其在解决RNN(循环神经网络)梯度消失问题上的应用。介绍了LSTM的四个核心组件——遗忘门、输入门、细胞状态更新及输出门,并详细阐述了其前向传播与反向传播算法。
文章目录
概述
在循环神经网络RNN详细推导中,已经说明了RNN并不能很好的处理较长的序列。一个主要的原因是,RNN在训练中很容易发生梯度消失,这导致训练时梯度不能在较长序列中一直传递下去,从而使RNN无法捕捉到长距离的影响。所以,有学者就提出了LSTM来解决梯度消失的问题。
一、从RNN到LSTM
原始RNN的隐藏层只有一个状态,即
h
h
h,它对于短期的输入非常敏感。所以,就假设再增加一个状态
c
c
c,让它来保存长期的状态,如下图所示:
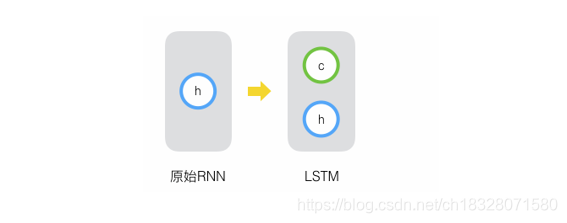
新增加的状态c,称为单元状态(cell state)。把上图按照时间维度展开:
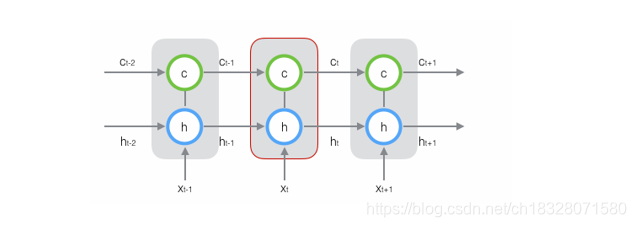
上图仅仅是一个示意图,可以看出,在
t
t
t时刻,LSTM的输入有三个:当前时刻网络的输入值
x
t
x_t
xt、上一时刻LSTM的输出值、以及上一时刻的单元状态;LSTM的输出有两个:当前时刻LSTM输出值、和当前时刻的单元状态。需要注意的是,他们都是向量。
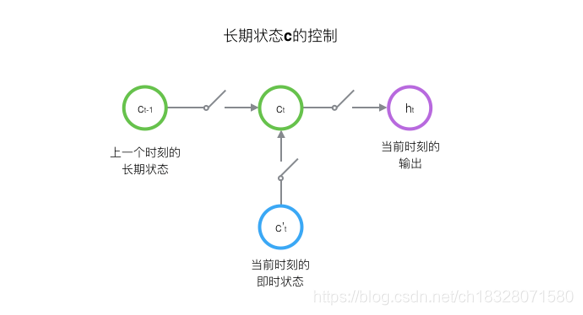
LSTM的关键,就是怎样控制长期状态
c
c
c。在这里,LSTM的思路是使用三个控制开关。第一个开关,负责控制继续保存长期状态c;第二个开关,负责控制把即时状态输入到长期状态c;第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。三个开关的作用如下图所示:
二、LSTM模型结构剖析
LSTM的结构如下:
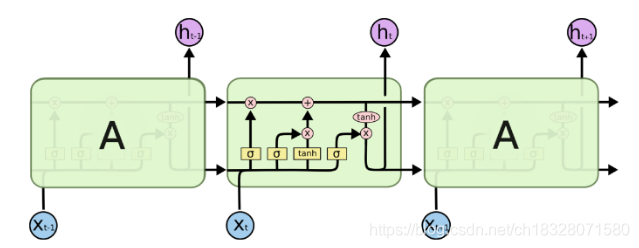
下边,就来看一下具体的每个门吧:
2.1 LSTM之遗忘门
遗忘门(forget gate),在LSTM中是以一定的概率控制是否遗忘上一层的隐藏细胞状态。遗忘门子结构如下图所示:
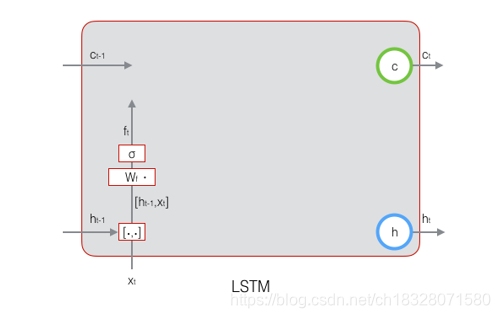
图中输入的有上时刻的隐藏状态
h
(
t
−
1
)
h^{(t−1)}
h(t−1)和本序列数据
x
(
t
)
x^{(t)}
x(t),通过一个激活函数,一般是sigmoid,得到遗忘门的输出
f
(
t
)
f^{(t)}
f(t)。由于sigmoid的输出
f
(
t
)
f^{(t)}
f(t)在[0,1]之间,因此这里的输出
f
(
t
)
f^{(t)}
f(t)代表了遗忘上一层隐藏细胞状态的概率。用数学表达式即为:
f
(
t
)
=
σ
(
W
f
h
(
t
−
1
)
+
U
f
x
(
t
)
+
b
f
)
f(t)=σ(W_fh^{(t−1)}+U_fx^{(t)}+b_f)
f(t)=σ(Wfh(t−1)+Ufx(t)+bf)
其中
W
f
,
U
f
,
b
f
W_f,U_f,b_f
Wf,Uf,bf为线性关系的系数和偏倚,和RNN中的类似。
σ
σ
σ为sigmoid激活函数。
2.2 LSTM之输入门
输入门(input gate)负责处理当前序列位置的输入,它的子结构如下图:
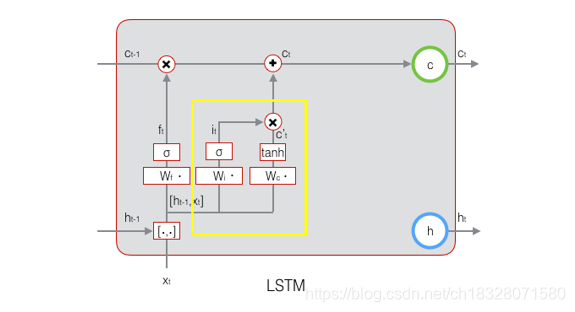
从图中可以看到输入门由两部分组成,第一部分使用了sigmoid激活函数,输出为
i
(
t
)
i(t)
i(t),第二部分使用了
t
a
n
h
tanh
tanh激活函数,输出为
c
′
(
t
)
c'(t)
c′(t), 两者的结果后面会相乘再去更新细胞状态。用数学表达式即为:
i ( t ) = σ ( W i h ( t − 1 ) + U i x ( t ) + b i ) i^{(t)}=σ(W_ih^{(t−1)}+U_ix^{(t)}+b_i) i(t)=σ(Wih(t−1)+Uix(t)+bi)
c ′ ( t ) = t a n h ( W c h ( t − 1 ) + U c x ( t ) + b c ) c'^{(t)}=tanh(W_ch^{(t−1)}+U_cx^{(t)}+b_c) c′(t)=tanh(Wch(t−1)+Ucx(t)+bc)
其中 W i , U i , b i , W c , U c , b c W_i,U_i,b_i,W_c,U_c,b_c Wi,Ui,bi,Wc,Uc,bc,为线性关系的系数和偏置,和RNN中的类似。 σ σ σ为sigmoid激活函数。
2.3 LSTM之细胞状态更新
在研究LSTM输出门之前,我们要先看看LSTM之细胞状态。前面的遗忘门和输入门的结果都会作用于细胞状态
C
(
t
)
C^{(t)}
C(t)。我们来看看从细胞状态
C
(
t
−
1
)
C^{(t−1)}
C(t−1)如何得到
C
(
t
)
C^{(t)}
C(t)。如下图所示:
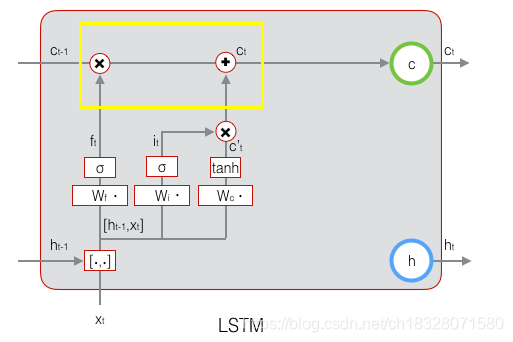
细胞状态
C
(
t
)
C^{(t)}
C(t)由两部分组成,第一部分是
C
(
t
−
1
)
C^{(t−1)}
C(t−1)和遗忘门输出
f
(
t
)
f^{(t)}
f(t)的乘积,第二部分是输入门的
i
(
t
)
i^{(t)}
i(t)和
a
(
t
)
a^{(t)}
a(t)的乘积,即:
C ( t ) = C ( t − 1 ) ⊙ f ( t ) + i ( t ) ⊙ a ( t ) C^{(t)}=C^{(t−1)}⊙f^{(t)}+i^{(t)}⊙a^{(t)} C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)
其中,⊙为Hadamard积,即:向量元素对应相乘。
2.4 LSTM之输出门
有了新的隐藏细胞状态
C
(
t
)
C^{(t)}
C(t),我们就可以来看输出门了,子结构如下:
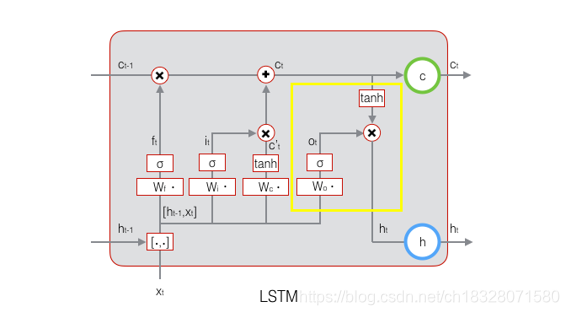
从图中可以看出,隐藏状态
h
(
t
)
h^{(t)}
h(t)的更新由两部分组成,第一部分是
o
(
t
)
o^{(t)}
o(t), 它由上一序列的隐藏状态
h
(
t
−
1
)
h^{(t−1)}
h(t−1)和本序列数据
x
(
t
)
x^{(t)}
x(t),以及激活函数sigmoid得到,第二部分由隐藏状态
C
(
t
)
C^{(t)}
C(t)和
t
a
n
h
tanh
tanh激活函数组成, 即:
o ( t ) = σ ( W o h ( t − 1 ) + U o x ( t ) + b o ) o^{(t)}=σ(W_oh^{(t−1)}+U_ox^{(t)}+b_o) o(t)=σ(Woh(t−1)+Uox(t)+bo)
h ( t ) = o ( t ) ⊙ t a n h ( C ( t ) ) h^{(t)}=o^{(t)}⊙tanh(C^{(t)}) h(t)=o(t)⊙tanh(C(t))
到这里,已经弄个清楚了LSTM的输入们、遗忘门、细胞更新和输出门了。接下来,就来推导一下LSTM的前向传播。
三、 LSTM前向传播算法
现在我们来总结下LSTM前向传播算法。LSTM模型有两个隐藏状态 h ( t ) h^{(t)} h(t), C ( t ) C^{(t)} C(t),模型参数几乎是RNN的4倍,因为现在多了 W f W_f Wf, U f U_f Uf, b f b_f bf, W c W_c Wc, U c U_c Uc, b c b_c bc, W i W_i Wi, U i U_i Ui, b i b_i bi, W o W_o Wo, U o U_o Uo, b o b_o bo这些参数。
前向传播过程在每个时刻的过程为:
1)更新遗忘门输出:
f
(
t
)
=
σ
(
W
f
h
(
t
−
1
)
+
U
f
x
(
t
)
+
b
f
)
f^{(t)}=σ(W_fh^{(t−1)}+U_fx^{(t)}+b_f)
f(t)=σ(Wfh(t−1)+Ufx(t)+bf)
2)更新输入门两部分输出:
i
(
t
)
=
σ
(
W
i
h
(
t
−
1
)
+
U
i
x
(
t
)
+
b
i
)
i^{(t)}=σ(W_ih^{(t−1)}+U_ix^{(t)}+b_i)
i(t)=σ(Wih(t−1)+Uix(t)+bi)
c ′ ( t ) = t a n h ( W c h ( t − 1 ) + U c x ( t ) + b c ) c'^{(t)}=tanh(W_ch^{(t−1)}+U_cx^{(t)}+b_c) c′(t)=tanh(Wch(t−1)+Ucx(t)+bc)
3)更新细胞状态:
C
(
t
)
=
C
(
t
−
1
)
⊙
f
(
t
)
+
i
(
t
)
⊙
a
(
t
)
C^{(t)}=C^{(t−1)}⊙f^{(t)}+i^{(t)}⊙a^{(t)}
C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)
4)更新输出门输出:
o
(
t
)
=
σ
(
W
o
h
(
t
−
1
)
+
U
o
x
(
t
)
+
b
o
)
o^{(t)}=σ(W_oh^{(t−1)}+U_ox^{(t)}+b_o)
o(t)=σ(Woh(t−1)+Uox(t)+bo)
h ( t ) = o ( t ) ⊙ t a n h ( C ( t ) ) h^{(t)}=o^{(t)}⊙tanh(C^{(t)}) h(t)=o(t)⊙tanh(C(t))
5)更新当前时刻预测输出:
y
^
(
t
)
=
σ
(
V
h
(
t
)
+
c
)
\hat{y}^{(t)}=σ(Vh^{(t)}+c)
y^(t)=σ(Vh(t)+c)
四、 LSTM反向传播算法
有了LSTM前向传播算法,接下来推导反向传播算法, 思路和RNN的反向传播算法思路一致,也是通过梯度下降法迭代更新所有的参数,关键点在于计算所有参数基于损失函数的偏导数。
在RNN中,为了反向传播误差,我们通过隐藏状态 h ( t ) h(t) h(t)的梯度 δ ( t ) δ^{(t)} δ(t)一步步向前传播。在LSTM这里也类似。只不过我们这里有两个隐藏状态 h ( t ) h^{(t)} h(t)和 C ( t ) C^{(t)} C(t)。这里我们定义两个 δ δ δ,即:
δ ( t ) h = ∂ L ∂ h ( t ) δ(t)h=\frac{∂L}{∂h^{(t)}} δ(t)h=∂h(t)∂L
δ ( t ) C = ∂ L ∂ C ( t ) δ(t)C=\frac{∂L}{∂C^{(t)}} δ(t)C=∂C(t)∂L
为了便于推导,我们将损失函数
L
(
t
)
L(t)
L(t)分成两块,一块是时刻t的损失
l
(
t
)
l(t)
l(t),另一块是时刻t之后损失
L
(
t
+
1
)
L(t+1)
L(t+1),即:
y
=
{
l
(
t
)
+
L
(
t
+
1
)
(
t
<
τ
)
l
(
t
)
(
t
=
τ
)
y= \begin{cases} l(t)+L(t+1)& (t<τ)\\ l(t)& (t=τ) \end{cases}
y={l(t)+L(t+1)l(t)(t<τ)(t=τ)
而在最后的时刻
τ
τ
τ的
δ
h
(
τ
)
δ^{(τ)}_h
δh(τ)和
δ
C
(
τ
)
δ^{(τ)}_C
δC(τ)为:
δ
h
(
τ
)
=
(
∂
O
(
τ
)
∂
h
(
τ
)
)
T
∂
L
(
τ
)
∂
O
(
τ
)
=
V
T
(
y
^
(
τ
)
−
y
(
τ
)
)
δ^{(τ)}_h=(\frac{∂O(τ)}{∂h(τ)})^T\frac{∂L(τ)}{∂O(τ)}=V^T(\hat{y}^{(τ)}−y^{(τ)})
δh(τ)=(∂h(τ)∂O(τ))T∂O(τ)∂L(τ)=VT(y^(τ)−y(τ))
δ C ( τ ) = ( ∂ h ( τ ) ∂ C ( τ ) ) T ∂ L ( τ ) ∂ h ( τ ) = δ h ( τ ) ⊙ o ( τ ) ⊙ ( 1 − t a n h 2 ( C ( τ ) ) ) δ^{(τ)}_C=(\frac{∂h(τ)}{∂C(τ)})^T\frac{∂L(τ)}{∂h(τ)}=δ^{(τ)}_h⊙o^{(τ)}⊙(1−tanh^2(C^{(τ)})) δC(τ)=(∂C(τ)∂h(τ))T∂h(τ)∂L(τ)=δh(τ)⊙o(τ)⊙(1−tanh2(C(τ)))
接着我们由 δ C ( t + 1 ) δ^{(t+1)}_C δC(t+1), δ h ( t + 1 ) δ^{(t+1)}_h δh(t+1)反向推导 δ h ( t ) δ^{(t)}_h δh(t), δ C ( t ) δ^{(t)}_C δC(t)。
δ
h
(
t
)
δ^{(t)}_h
δh(t)的梯度由本层t时刻的输出梯度误差和大于t时刻的误差两部分决定,即:
δ
h
(
t
)
=
∂
L
∂
h
(
t
)
=
∂
l
(
t
)
∂
h
(
t
)
+
(
∂
h
(
t
+
1
)
∂
h
(
t
)
)
T
∂
L
(
t
+
1
)
∂
h
(
t
+
1
)
=
V
T
(
(
^
y
)
(
t
)
−
y
(
t
)
)
+
(
∂
h
(
t
+
1
)
∂
h
(
t
)
)
T
δ
h
(
t
+
1
)
δ^{(t)}_h=\frac{∂L}{∂h^{(t)}}=\frac{∂l^{(t)}}{∂h(t)}+(\frac{∂h^{(t+1)}}{∂h^{(t)}})^T\frac{∂L^{(t+1)}}{∂h^{(t+1)}}=V^T(\hat(y)^{(t)}−y^{(t)})+(\frac{∂h^{(t+1)}}{∂h(t)})^Tδ^{(t+1)}_h
δh(t)=∂h(t)∂L=∂h(t)∂l(t)+(∂h(t)∂h(t+1))T∂h(t+1)∂L(t+1)=VT((^y)(t)−y(t))+(∂h(t)∂h(t+1))Tδh(t+1)
整个LSTM反向传播的难点就在于
∂
h
(
t
+
1
)
∂
h
(
t
)
\frac{∂h^{(t+1)}}{∂h^{(t)}}
∂h(t)∂h(t+1)这部分的计算。仔细观察,由于
h
(
t
)
=
o
(
t
)
⊙
t
a
n
h
(
C
(
t
)
)
h^{(t)}=o^{(t)}⊙tanh(C^{(t)})
h(t)=o(t)⊙tanh(C(t)), 在第一项
o
(
t
)
o^{(t)}
o(t)中,包含一个
h
h
h的递推关系,第二项
t
a
n
h
(
C
(
t
)
)
tanh(C^{(t)})
tanh(C(t))就复杂了,
t
a
n
h
tanh
tanh函数里面又可以表示成:
C
(
t
)
=
C
(
t
−
1
)
⊙
f
(
t
)
+
i
(
t
)
⊙
a
(
t
)
C^{(t)}=C^{(t−1)}⊙f^{(t)}+i^{(t)}⊙a^{(t)}
C(t)=C(t−1)⊙f(t)+i(t)⊙a(t)
t a n h tanh tanh 函数的第一项中, f ( t ) f^{(t)} f(t)包含一个 h h h的递推关系,在 t a n h tanh tanh函数的第二项中, i ( t ) i^(t) i(t)和 a ( t ) a^(t) a(t)都包含 h h h的递推关系,因此,最终 ∂ h ( t + 1 ) ∂ h ( t ) \frac{∂h(t+1)}{∂h(t)} ∂h(t)∂h(t+1)这部分的计算结果由四部分组成。即:
Δ C = o ( t + 1 ) ⊙ [ 1 − t a n h 2 ( C ( t + 1 ) ) ] ΔC=o^{(t+1)}⊙[1−tanh^2(C^{(t+1)})] ΔC=o(t+1)⊙[1−tanh2(C(t+1))]
∂ h ( t + 1 ) ∂ h ( t ) = W o T [ o ( t + 1 ) ⊙ ( 1 − o ( t + 1 ) ) ⊙ t a n h ( C ( t + 1 ) ) ] + W f T [ Δ C ⊙ f ( t + 1 ) ⊙ ( 1 − f ( t + 1 ) ) ⊙ C ( t ) ] + W c T Δ C ⊙ i ( t + 1 ) ⊙ [ 1 − ( c ( t + 1 ) ) 2 ] + W i T [ Δ C ⊙ c ( t + 1 ) ⊙ i ( t + 1 ) ⊙ ( 1 − i ( t + 1 ) ) ] \frac{∂h^{(t+1)}}{∂h(t)}=W^T_o[o^{(t+1)}⊙(1−o^{(t+1)})⊙tanh(C^{(t+1)})]+W^T_f[ΔC⊙f^{(t+1)}⊙(1−f^{(t+1)})⊙C^{(t)}]+W^T_c{ΔC⊙i^{(t+1)}⊙[1−(c^{(t+1)})^2]}+W^T_i[ΔC⊙c^{(t+1)}⊙i^{(t+1)}⊙(1−i^{(t+1)})] ∂h(t)∂h(t+1)=WoT[o(t+1)⊙(1−o(t+1))⊙tanh(C(t+1))]+WfT[ΔC⊙f(t+1)⊙(1−f(t+1))⊙C(t)]+WcTΔC⊙i(t+1)⊙[1−(c(t+1))2]+WiT[ΔC⊙c(t+1)⊙i(t+1)⊙(1−i(t+1))]
而 δ C ( t ) δ^{(t)}_C δC(t)的反向梯度误差由前一层 δ C ( t + 1 ) δ^{(t+1)}_C δC(t+1)的梯度误差和本层的从 h ( t ) h^{(t)} h(t)传回来的梯度误差两部分组成,即:
δ C ( t ) = ( ∂ C ( t + 1 ) ∂ C ( t ) ) T ∂ L ∂ C ( t + 1 ) + ( ∂ h ( t ) ∂ C ( t ) ) T ∂ L ∂ h ( t ) = ( ∂ C ( t + 1 ) ∂ C ( t ) ) T δ C ( t + 1 ) + δ h ( t ) ⊙ o ( t ) ⊙ ( 1 − t a n h 2 ( C ( t ) ) ) = δ C ( t + 1 ) ⊙ f ( t + 1 ) + δ h ( t ) ⊙ o ( t ) ⊙ ( 1 − t a n h 2 ( C ( t ) ) ) δ^{(t)}_C=(\frac{∂C^{(t+1)}}{∂C^{(t)}})^T\frac{∂L}{∂C^{(t+1)}}+(\frac{∂h^{(t)}}{∂C^{(t)}})^T\frac{∂L}{∂h^{(t)}}=(\frac{∂C^{(t+1)}}{∂C^{(t)}})^Tδ^{(t+1)}_C+δ^{(t)}_h⊙o^{(t)}⊙(1−tanh^2(C^{(t)}))=δ^{(t+1)}_C⊙f^{(t+1)}+δ^{(t)}_h⊙o^{(t)}⊙(1−tanh^2(C^{(t)})) δC(t)=(∂C(t)∂C(t+1))T∂C(t+1)∂L+(∂C(t)∂h(t))T∂h(t)∂L=(∂C(t)∂C(t+1))TδC(t+1)+δh(t)⊙o(t)⊙(1−tanh2(C(t)))=δC(t+1)⊙f(t+1)+δh(t)⊙o(t)⊙(1−tanh2(C(t)))
有了
δ
h
(
t
)
δ^{(t)}_h
δh(t)和
δ
C
(
t
)
δ^{(t)}_C
δC(t), 计算这一大堆参数的梯度就很容易了,这里只给出
W
f
W_f
Wf的梯度计算过程,其他的
U
f
U_f
Uf,
b
f
b_f
bf,
W
c
W_c
Wc,
U
c
U_c
Uc,
b
c
b_c
bc,
W
i
W_i
Wi,
U
i
U_i
Ui,
b
i
b_i
bi,
W
o
W_o
Wo,
U
o
U_o
Uo,
b
o
b_o
bo,
V
V
V,
c
c
c的梯度大家只要照搬就可以了。
∂
L
∂
W
f
=
∑
t
=
1
τ
[
δ
C
(
t
)
⊙
C
(
t
−
1
)
⊙
f
(
t
)
⊙
(
1
−
f
(
t
)
)
]
(
h
(
t
−
1
)
)
T
\frac{∂L}{∂W_f}=\sum_{t=1}^{τ}[δ^{(t)}_C⊙C^{(t−1)}⊙f^{(t)}⊙(1−f^{(t)})](h^{(t−1)})^T
∂Wf∂L=t=1∑τ[δC(t)⊙C(t−1)⊙f(t)⊙(1−f(t))](h(t−1))T
五、LSTM总结
LSTM虽然结构复杂,但是只要理顺了里面的各个部分和之间的关系,进而理解前向反向传播算法是不难的。当然实际应用中LSTM的难点不在前向反向传播算法,这些有算法库帮你搞定,模型结构和一大堆参数的调参才是让人头痛的问题。后边,会继续更新有关于用tensorflow实现LSTM的文章!
六、项目实战
项目实战请转至:tensorflow学习笔记(八):LSTM手写体(MNIST)识别。

















 1158
1158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









