







发表于:AAAI24
推荐指数: #paper/⭐⭐
领域:图增强工业实现
背景/贡献
曾经的图增强方法:
很多都需要负样本,并且以前的对比学习,需要对比头
做出的解决思路:
只用正样本+MLP去预测另外一个分支的嵌入,不需要负样本和对比头
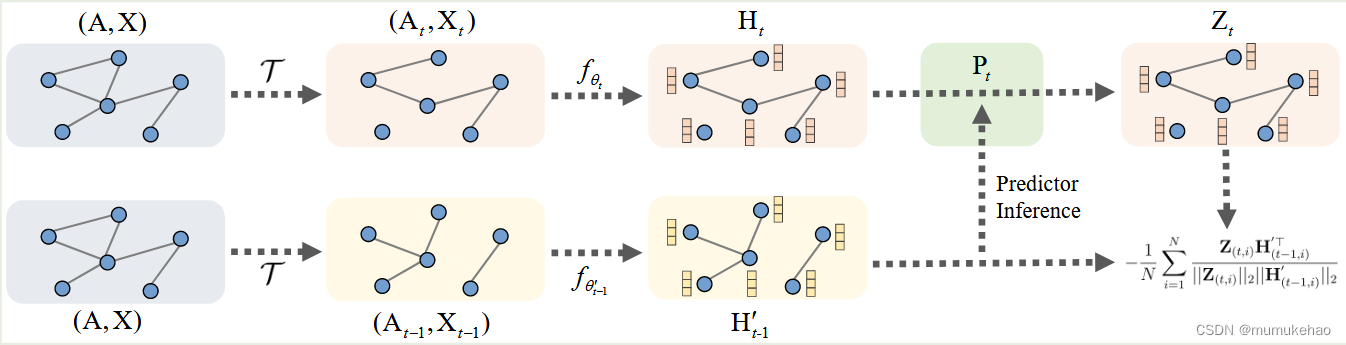
实验过程
实验流程
首先,两个原始图通过两个增强,得到两个增强图.然后,通过两个不同样式的编码器得到两组特征嵌入H1,H2.之后,上面的嵌入H1通过1层MLP(线性层)得到嵌入Z,将Z与嵌入H2计算对比损失
(为了方便,(博主)我描述上面的编码器为GNN encoder1,特征为H1,下面的编码器为GNN encoder2,特征为H2)
消融实验
根据如上框架,做消融实验
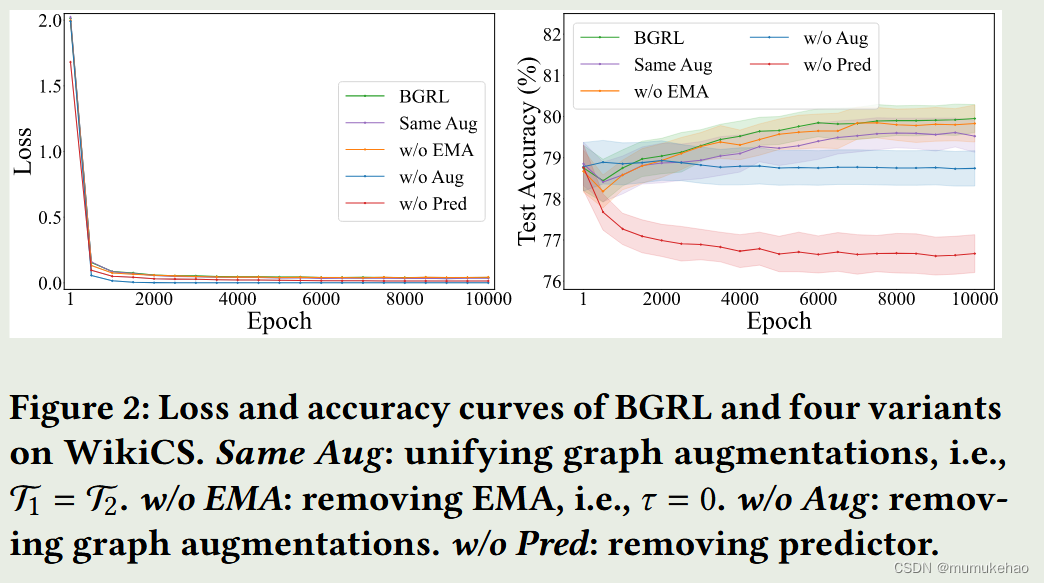
如上消融实验证明,在BGRL框架中,EMA更新下面的GNN encoder2不是必须要的,所以作者采用了将上回合的GNN encoder1的参数复制到了这一轮GNN encoder2中
必要的有两点:BGRL成功的关键在于图增强和线性预测器(如上图P)
为线性预测器设置初始化权重的策略:
W p = 1 N − 1 H T H . \mathbf{W}_p=\frac{1}{N-1}\mathbf{H}^{\mathsf{T}}\mathbf{H}. Wp=N−11HTH.
完整流程
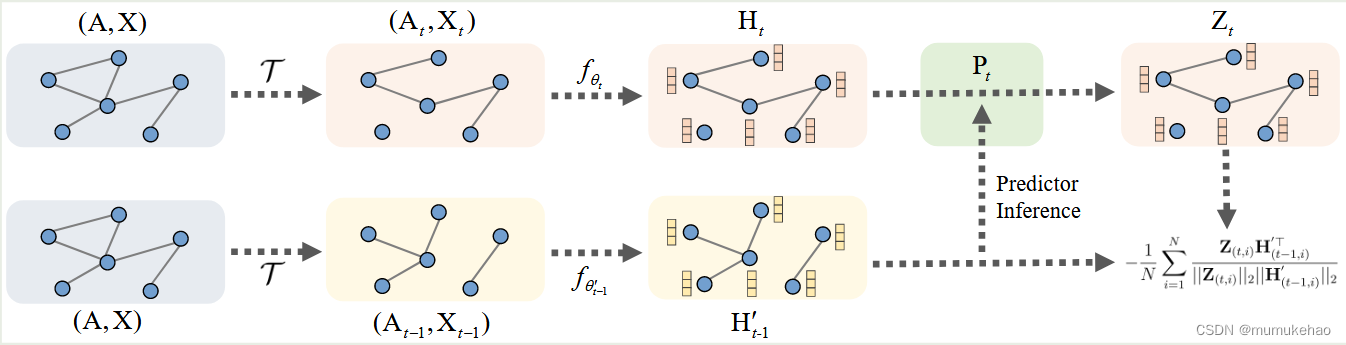
首先,生成正样本对:
E
t
=
B
e
r
n
o
u
l
l
i
(
E
,
1
−
p
e
)
,
0
<
p
e
<
1
,
X
t
=
B
e
r
n
o
u
l
l
i
(
X
,
1
−
p
f
)
,
0
<
p
f
<
1
,
\mathcal{E}_{t}=\mathrm{Bernoulli}(\mathcal{E},1-p_e),0<p_e<1,\\\mathbf{X}_{t}=\mathrm{Bernoulli}(\mathbf{X},1-p_f),0<p_f<1,
Et=Bernoulli(E,1−pe),0<pe<1,Xt=Bernoulli(X,1−pf),0<pf<1,
即:通过贝努力分布生成边增强,节点增强.
数据增强复用
其将上一轮生成的H1,作为本轮生成的H2,并将H1的编码器复制到H2中,减少了编码器生成数据的开销
编码器参数更新
我们不采用用GNN encoder1参数动量更新GNN encoder2的方式,而是采用将GNN encoder2复制上一轮GNN encoder1的方式
预测器参数的生成:
P
t
=
H
ˉ
t
−
1
′
⊤
H
ˉ
t
−
1
′
N
−
1
,
\mathbf{P}_{t}=\frac{\mathbf{\bar{H}}_{t-1}^{'\top}\mathbf{\bar{H}}_{t-1}^{'}}{N-1},
Pt=N−1Hˉt−1′⊤Hˉt−1′,
对于H,我们对其进行标准化,得到:
H
‾
(
t
−
1
,
i
)
′
=
H
(
t
−
1
,
i
)
′
−
m
∣
∣
H
(
t
−
1
,
i
)
′
−
m
∣
∣
2
,
\overline{\mathbf{H}}_{(t-1,i)}^{\prime}=\frac{\mathbf{H}_{(t-1,i)}^{\prime}-\mathbf{m}}{||\mathbf{H}_{(t-1,i)}^{\prime}-\mathbf{m}||_{2}},
H(t−1,i)′=∣∣H(t−1,i)′−m∣∣2H(t−1,i)′−m,
这样,
Z
t
=
H
t
P
t
.
\mathbf{Z}_t=\mathbf{H}_t\mathbf{P}_t.
Zt=HtPt.
L
θ
=
1
−
1
N
∑
i
=
1
N
Z
(
t
,
i
)
H
(
t
−
1
,
i
)
′
⊤
∣
∣
Z
(
t
,
i
)
∣
∣
2
∣
∣
H
(
t
−
1
,
i
)
′
∣
∣
2
.
\mathcal{L}_\theta=1-\frac1N\sum_{i=1}^N\frac{\mathcal{Z}_{(t,i)}\mathcal{H}_{(t-1,i)}^{^{\prime}\top}}{||\mathcal{Z}_{(t,i)}||_2||\mathcal{H}_{(t-1,i)}^{^{\prime}}||_2}.
Lθ=1−N1i=1∑N∣∣Z(t,i)∣∣2∣∣H(t−1,i)′∣∣2Z(t,i)H(t−1,i)′⊤.
总结:
在这个将对比学习越做越复杂,参数越多,攀比正确率的时代,作者做了减法,去掉了负样本,以及映射头,并对图增强数据等进行了复用,极大减少了图对比的开销,把图对比在工业界的应用往前推了一步















 5273
5273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









