







✅博主简介:本人擅长数据处理、建模仿真、程序设计、论文写作与指导,项目与课题经验交流。项目合作可私信或扫描文章底部二维码。
基于机器视觉的番茄采摘机器人设计
番茄采摘机器人是农业自动化中的重要研究方向之一,其核心是利用机器视觉系统进行番茄果实的检测、定位和精确采摘。由于番茄果实的复杂生长环境,如复杂的背景、果实重叠、光照变化等因素,设计一个能精准识别、定位和采摘的机器人面临巨大挑战。本文将基于机器视觉技术,对番茄采摘机器人系统设计中的关键问题进行探讨,并给出相应的解决方案。
1. 番茄果实检测识别与定位技术
1.1 光照变化下的检测技术
光照条件是影响机器视觉系统检测效果的重要因素之一。在实际应用中,番茄果实的颜色与背景(如叶片、枝干)较为相似,强烈的光照和阴影会进一步增加识别难度。因此,基于深度学习技术的视觉系统是解决这一问题的有效手段。通过构建一个基于卷积神经网络(CNN)的番茄检测模型,并结合大规模番茄数据集的训练,机器人可以在复杂的光照条件下实现高精度的果实检测。
为此,设计了一种适应不同光照强度的番茄检测方法,具体步骤如下:
- 数据集构建:通过采集不同光照条件下的番茄图像,构建一个包含丰富场景和多种番茄果实的数据库。
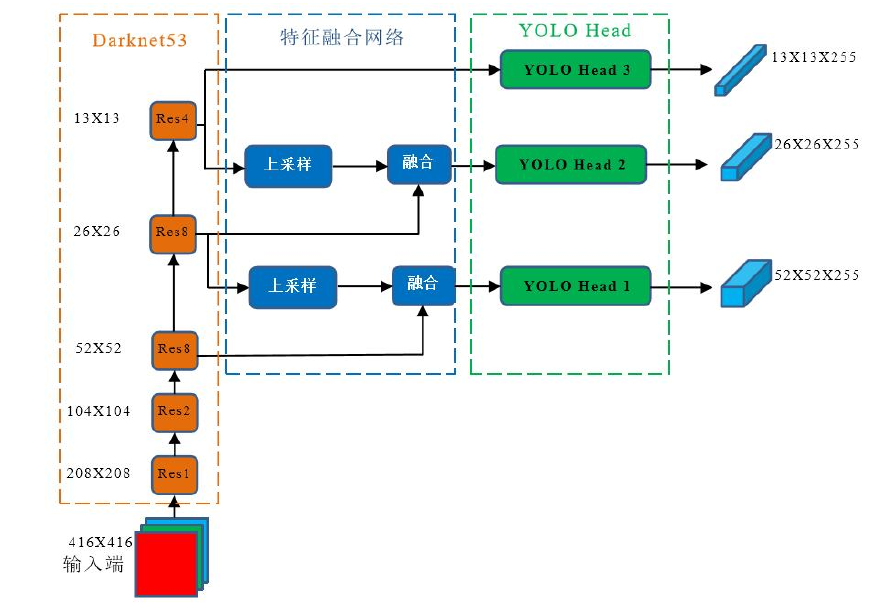
- 网络结构设计:采用YOLOv5深度学习框架进行番茄果实检测,能够在复杂的背景下快速且精准地检测出成熟的番茄果实。
- 后处理步骤:为了提高检测的准确性,利用颜色信息与几何特征对检测结果进行二次过滤,确保减少误识别和漏识别现象。
1.2 基于双目相机的空间定位技术
在准确检测到番茄果实后,需要进行空间定位以确定果实的具体位置。基于双目相机的视觉定位系统可以获取果实的三维空间坐标,具体流程如下:
- 双目相机标定:通过标定获取相机的内外参数,确定双目相机的几何关系,进而实现空间深度信息的计算。
- 视差图生成:利用左右相机拍摄的图像,生成视差图,视差越大,表示物体越近。
- 三维坐标计算:根据视差图和相机标定参数,利用三角测量法计算出番茄果实的三维空间坐标,获取其在机械臂工作空间中的精确位置。
2. 无接触式末端执行器设计
2.1 无接触采摘原理
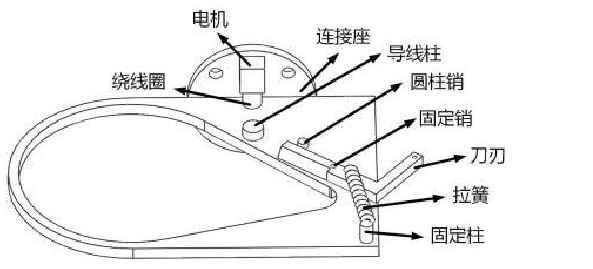
传统的农业采摘机器人往往使用机械抓手直接接触果实,但这种方式容易对番茄等娇嫩果实造成损伤。为了解决这一问题,设计了一种基于剪切果梗的无接触式末端执行器,通过剪断果梗而不是直接抓取果实,从而避免果实表皮的损伤。主要步骤如下:
- 剪切结构设计:执行器通过摄像头定位果梗,并通过电动剪刀进行精准剪切,保留果蒂,避免果实损伤。
- 冗余度设计:为了防止误操作,在剪切动作中,留有一定的容错余量,确保采摘过程安全可靠。
- 自动校准:通过摄像头和传感器实时调整执行器的位置,确保果实被正确剪下。
2.2 执行器与机械臂控制系统的集成
番茄采摘机器人采用模块化设计,将末端执行器的控制模块与主控平台集成。通过上位机处理果实的空间位置信息,规划机械臂的运动路径,并驱动执行器完成采摘任务。具体步骤如下:
- 路径规划:上位机通过规划机械臂的运动路径,确保执行器能够平稳移动至目标果实。
- 执行器控制:执行器通过电机控制剪切动作,同时配备传感器以确保采摘动作完成后无损伤。
- 通信集成:使用通信模块实现机械臂、末端执行器与主控系统的高效通信,确保采摘任务的顺利执行。
3. 系统集成与优化
3.1 系统小型化与轻量化设计
为了适应设施农业的工作场景,番茄采摘机器人在设计过程中进行了小型化与轻量化优化。通过合理选择材料和简化机械结构,使机器人在番茄种植环境中灵活作业。该系统的集成步骤包括:
- 轻量化结构设计:优化机械臂和执行器的材料选择,减少系统总重量。
- 模块化集成:将视觉检测、机械臂控制、执行器控制等模块化,便于后续维护与升级。
3.2 系统智能化与自动化
在系统集成过程中,重点加强了机器视觉系统与采摘控制系统的集成与智能化应用。通过深度学习模型的引入以及基于传感器的智能反馈机制,确保机器人能够自动检测、识别和采摘目标番茄。主要实现步骤如下:
- 智能控制算法:集成基于深度学习的检测算法与路径规划算法,确保机器人在复杂环境下实现自动导航与采摘。
- 实时反馈系统:通过传感器实时获取果实与障碍物的位置信息,并实时调整机械臂的路径。
4. 实验验证
4.1 模拟实验
在实验室环境下搭建了一个模拟番茄种植场景,使用机器视觉系统对不同光照条件下的番茄果实进行检测,并测试无接触式末端执行器的剪切效果。实验结果表明,该系统能够在复杂背景下有效检测和采摘番茄,且剪切动作精准无误。
4.2 实地验证
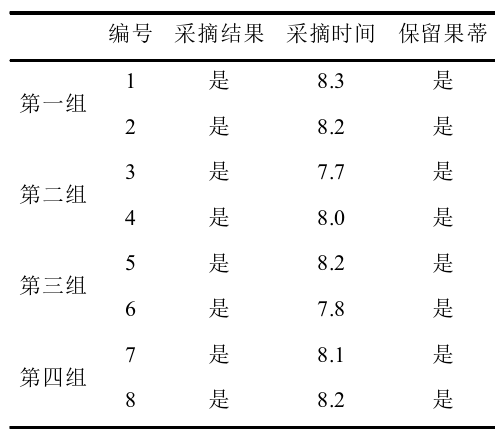
通过在实际番茄种植园中进行的实地验证,进一步测试了番茄采摘机器人的稳定性和可靠性。在多次采摘实验中,机器人采摘下的番茄果实完整、果蒂保存完好,且果实外皮无损伤,验证了该系统的实用性。
import torch
import cv2
import numpy as np
# 加载YOLOv3模型
model = torch.hub.load('ultralytics/yolov3', 'custom', path='best.pt') # 替换为你的训练模型路径
# 双目相机的参数
focal_length = 0.8 # 焦距
baseline = 10 # 两个相机的基线距离
# 图像预处理函数
def preprocess_image(image):
img = cv2.resize(image, (640, 640))
return img
# 通过双目相机计算深度信息
def calculate_depth(left_image, right_image):
stereo = cv2.StereoBM_create(numDisparities=16, blockSize=15)
disparity = stereo.compute(left_image, right_image)
depth = (focal_length * baseline) / (disparity + 1e-6) # 防止除以0
return depth
# 进行番茄检测
def detect_tomato(image):
results = model(image)
detected_objects = results.pandas().xyxy[0] # 获取检测结果的DataFrame
tomatoes = detected_objects[detected_objects['name'] == 'tomato'] # 筛选出番茄
return tomatoes
# 机械臂运动路径规划函数(简化)
def plan_arm_path(tomato_location):
# 使用机械臂控制API将机械臂移动到番茄位置
x, y, z = tomato_location
# 假设机械臂的运动控制代码在此实现
print(f"Moving to location: {x}, {y}, {z}")
# 主流程
left_image = cv2.imread('left_image.png', 0) # 左相机图像
right_image = cv2.imread('right_image.png', 0) # 右相机图像
# 计算深度信息
depth_map = calculate_depth(left_image, right_image)
# 检测番茄并提取位置信息
image = cv2.imread('image.png')
preprocessed_image = preprocess_image(image)
tomatoes = detect_tomato(preprocessed_image)
# 根据检测结果和深度图定位番茄的三维坐标
for idx, tomato in tomatoes.iterrows():
x_center = (tomato['xmin'] + tomato['xmax']) / 2
y_center = (tomato['ymin'] + tomato['ymax']) / 2
z_depth = depth_map[int(y_center), int(x_center)]
plan_arm_path((x_center, y_center, z_depth))
# 显示检测结果
results.show()
不同光线的视觉数据:

算法网络:
检测结果:


结构设计:
结果统计:


















 3739
3739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











