







✅博主简介:本人擅长数据处理、建模仿真、论文写作与指导,科研项目与课题交流。项目合作可私信或扫描文章底部二维码。
(1)联邦学习(Federated Learning,FL)作为一种解决数据孤岛问题的新兴方法,因其在保护数据隐私的同时能够联合多个节点进行模型训练而广受关注。在传统的集中式机器学习中,数据通常集中在一个中央服务器上进行模型训练,这虽然能有效提升模型性能,但却忽视了数据隐私和安全的顾虑。相比之下,联邦学习通过在各个参与方的本地设备上进行模型训练,并将本地更新传递给中心服务器以更新全局模型,实现了模型的共享而不交换数据的目标。然而,联邦学习的实现并非毫无挑战,其中最大的问题之一便是数据异构性。
数据异构性指的是参与联邦学习的节点之间,因地理位置、用户群体、硬件条件等不同,导致数据特征和分布差异显著。例如,在一个跨医疗机构的联邦学习系统中,不同医院的患者数据可能在年龄、病情、医疗设备的使用等方面存在显著差异。这种数据异构性会导致本地模型的表现差异较大,从而影响全局模型的准确性。数据异构性问题主要体现在两个方面:一是本地数据与全局数据分布不一致,导致全局模型难以有效收敛;二是本地训练的模型偏移现象,即本地模型对自身数据拟合较好,但难以泛化到其他数据节点。
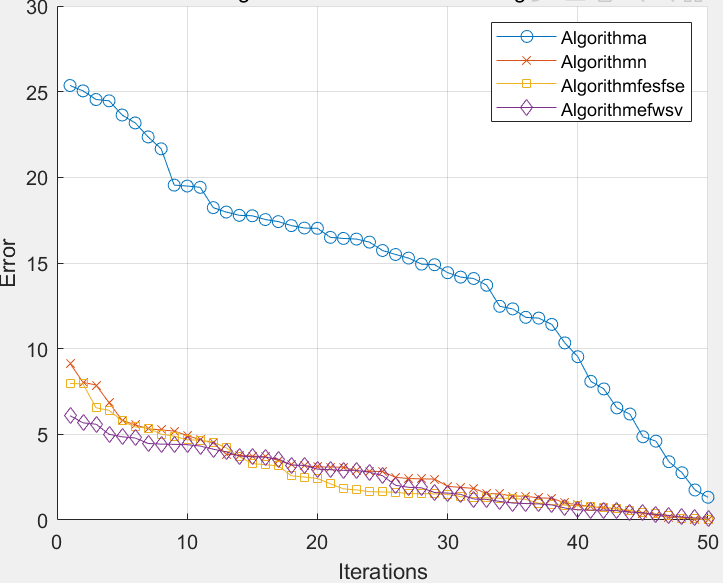
为了应对这些问题,本研究在传统联邦学习的基础上提出了多种改进方案,旨在提升联邦学习在数据异构场景下的表现。首先,本文通过引入惩罚正则项,对经典的FedAvg算法进行了优化,提出了一种改进算法——FedAvg-Z,以减小全局模型与本地模型之间的权重差异,从而提升模型的泛化能力。在FedAvg算法中,参与的每个节点在本地数据集上独立训练模型,并将更新后的模型参数上传到中央服务器,由服务器进行加权平均以更新全局模型。然而,数据异构性会导致不同节点的本地模型权重差异较大,直接加权平均容易使全局模型偏向于某些特定节点,从而降低模型精度。为此,FedAvg-Z通过增加惩罚正则项,限制本地模型与全局模型之间的差异,从而保证全局模型的准确性。实验结果表明,该算法在MNIST和CIFAR-10等数据集上表现良好,显著提高了联邦学习在异构数据下的性能。
(2)除了模型聚合过程中的改进,本文还对联邦学习中的节点选择策略进行了优化。传统联邦学习通常采用随机选择节点的方式参与每一轮的训练,这种方法在节点数据质量差异较大的情况下,容易导致全局模型的泛化能力下降。尤其是在数据异构性较强的场景下,一些节点可能持有质量较差的数据,这会对全局模型的训练过程产生负面影响。为了解决这一问题,本研究提出了一种基于节点数据质量的选择策略。具体而言,系统根据每个节点在上一轮训练中的表现以及其持有数据集的规模,动态调整参与本轮训练的节点集合。这种双向选择机制不仅能确保高质量数据节点的优先参与,还能在数据量较少的节点之间实现合理的平衡。
此外,本文还引入了去中心化的联邦学习框架。在传统联邦学习中,中央服务器负责汇聚各个节点上传的模型参数并更新全局模型,这一过程带来了巨大的通信压力,尤其是在大规模分布式系统中,网络带宽的限制进一步加剧了这一问题。为了减轻中央服务器的通信负担,本研究采用去中心化的模型更新方式,即每个节点可以与其他节点直接通信并交换模型参数,最终形成去中心化的全局模型。实验表明,去中心化的联邦学习框架不仅有效减少了通信开销,还提高了系统的鲁棒性,尤其在网络不稳定的环境中,去中心化架构表现得更加稳定。
为了进一步提升联邦学习的效率,本文还结合了知识蒸馏技术。知识蒸馏是一种常用于模型压缩的方法,它通过将复杂模型的知识提取出来并转移到较小的模型中,从而减小模型的计算量。在联邦学习中,知识蒸馏技术可以用于减少模型参数的传输量,同时保证模型的性能不受显著影响。实验结果表明,结合知识蒸馏技术的联邦学习系统在保证模型精度的同时,显著加快了训练过程,并减少了通信成本。
(3)最后,本文针对计算资源受限的节点,提出了一种基于分割学习的联邦学习优化方案。在实际应用中,许多参与联邦学习的设备计算资源有限,难以在本地训练复杂的深度学习模型。为了减轻这些节点的计算负担,本文引入了分割学习的思想,即将完整的深度学习模型分割为多个部分,节点仅需在本地训练模型的一部分,其余部分则由中央服务器或其他高性能节点负责。这种分布式的训练方式不仅降低了节点的计算压力,还通过并行计算加快了模型的训练速度。
在具体实现中,本文将ResNet-18和AlexNet等复杂神经网络应用于MNIST、CIFAR-10和FEMNIST数据集上,并针对不同的分割位置进行了实验对比。实验结果表明,基于分割学习的联邦学习系统能够有效提高复杂模型的训练效率,特别是在计算资源有限的节点上,分割学习显著减少了本地设备的负载,并保证了模型的准确性。与此同时,本文还结合了前述的节点选择机制,在确保高质量节点优先参与的基础上,进一步加强了系统的收敛速度。
% MATLAB 联邦学习优化算法示例
% 定义节点数和训练轮次
num_nodes = 10; % 假设有10个参与节点
num_rounds = 20; % 联邦学习训练20轮
% 初始化全局模型参数
global_model = rand(1, 100); % 假设模型有100个参数
% 定义本地模型更新函数
function local_model = local_training(global_model, local_data)
% 模拟本地训练过程
local_model = global_model + randn(size(global_model)) * 0.1;
end
% 定义模型聚合函数
function aggregated_model = aggregate_models(models)
% 对本地模型进行加权平均
aggregated_model = mean(models, 1);
end
% 模拟联邦学习过程
for round = 1:num_rounds
local_models = zeros(num_nodes, 100);
% 各个节点进行本地训练
for node = 1:num_nodes
local_data = rand(1, 100); % 假设每个节点有自己的本地数据
local_models(node, :) = local_training(global_model, local_data);
end
% 聚合本地模型
global_model = aggregate_models(local_models);
fprintf('第%d轮训练结束,全局模型更新\n', round);
end
% 输出最终全局模型参数
disp('最终全局模型参数:');
disp(global_model);


















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











