







✅ 博主简介:擅长数据搜集与处理、建模仿真、程序设计、仿真代码、论文写作与指导,毕业论文、期刊论文经验交流。
✅ 具体问题可以私信或扫描文章底部二维码。
(1) 基于建模与优化算法的锂离子电池状态估计
锂离子电池的电池状态估计(包括荷电状态SOC、健康状态SOH、能量状态SOE等)是电池管理系统(BMS)中的核心任务之一,对于保证电池安全、高效地工作具有重要意义。针对电池的复杂非线性和内部化学反应难以准确描述的问题,本文首先引入了元启发式优化算法来改进电池模型的参数辨识。具体地,本文以灰鲸优化算法为基础,结合非线性函数和自适应权重系数,提出了一种改进的灰鲸优化算法,用于对分数阶微积分理论建立的锂离子电池模型进行参数优化。该优化算法能够有效地处理不同温度、不同工况下的复杂参数辨识问题,从而使得电池状态估计的精度显著提高。该方法还利用无迹卡尔曼滤波(UKF)来处理电流和电压的漂移问题,通过自适应调整滤波增益,可以更好地抑制噪声对估计结果的干扰,在各种动态工况中保证估计的准确性和鲁棒性。
在实验验证中,本文通过模拟电池在不同温度和工况下的行为,验证了所提出模型和算法的有效性和鲁棒性。实验结果表明,结合分数阶模型和改进的灰鲸优化算法后,电池SOC和电压的估计误差显著降低,证明了所提算法在复杂环境下依然可以保持较高的估计精度。这对于电池系统在实际使用过程中的安全与稳定运行具有重要意义。
(2) 基于神经网络的电池状态估计与多工况适应性
由于电池内部的非线性和工况多样性,传统的基于物理模型的SOC估计方法在不同温度和复杂工况下表现出较大的误差。为了应对这一问题,本文提出了一种基于带有激活层的门控循环单元(GRU)神经网络的方法来建立电池状态估计模型。GRU神经网络可以通过其门控机制有效地捕获电池系统中的动态特性,不依赖于具体的电池物理模型,因而在多种不同的工况中表现出良好的适应性。
在实验中,本文收集了不同电流和温度下的电池充放电数据,利用这些数据对GRU网络进行训练和验证。实验结果显示,所提出的GRU网络能够在噪声存在的情况下有效地估计电池SOC,其估计误差(MAE和RMSE)均保持在2%以内。特别是对于未知工况,GRU模型也能通过其自适应学习能力实现较高的估计精度,展示了良好的泛化能力。这为电池在复杂多变的使用环境下的状态估计提供了有效的解决方案。
(3) 迁移学习在电池SOC和SOE估计中的应用
数据驱动方法是近年来在电池状态估计领域中的研究热点之一,但通常需要大量的训练数据,特别是对于不同类型的电池,由于各自特性存在差异,难以直接应用统一的模型。为此,本文提出了一种基于迁移学习的电池SOC和SOE估计方案。首先,本文通过多尺度卷积神经网络(MSCNN)从不同数据通道中提取特征,并通过注意力机制增强这些特征,以提高模型的估计精度。
其次,本文利用无迹卡尔曼滤波对深度学习模型的输出进一步优化,消除噪声对估计结果的干扰。通过使用源域的数据(如特定型号的电池数据)训练深度学习模型,并将该模型迁移到其他电池上,本文在目标域数据量有限的情况下实现了高精度的SOC和SOE估计。实验结果表明,该迁移学习方案在处理数据缺乏的问题上具有显著优势,不仅节省了大量的标注数据,而且提升了模型的泛化能力。
(4) 基于改进的灰鲸优化算法的SOH估计与RUL预测
电池健康状态(SOH)和剩余使用寿命(RUL)的估计是保障电池安全、高效使用的重要内容。本文提出了一种结合改进灰鲸优化算法和可变遗忘因子的在线极限学习机(ELM)的方法,用于电池SOH估计和RUL预测。首先,本文从充电阶段的数据中提取电压和电流特征,利用极度随机树(ERT)对这些特征进行重要性排序,并选取最具代表性的特征作为模型输入。
为了进一步提高模型的估计精度,本文引入了灰鲸优化算法优化可变遗忘因子的在线极限学习机模型,通过调整遗忘因子使得模型能够更好地适应电池老化过程中特征变化的不确定性。在此基础上,利用粒子滤波器进行RUL预测,结合改进的灰鲸算法对粒子滤波过程进行优化,以降低长期预测中的累积误差。仿真实验结果显示,本文的方法在不同噪声水平和不同特征组合下均表现出较高的SOH估计精度和抗干扰能力,特别是在长期RUL预测中,其结果能够有效地提供电池故障预警和健康管理支持。
(5) 基于数据重构和时间卷积网络的SOH估计研究
电池在实际使用过程中,电压和电流信号中常常存在噪声干扰,影响状态估计的精度。为了解决这个问题,本文提出了一种基于CV-Variable模型的电压曲线重构方法,以及基于极限学习机算法的电流曲线重构方法。这些重构过程能够使得电压容量曲线更加平滑,从而更容易进行特征提取(如峰值位置、峰面积等),为后续的SOH估计提供更高质量的输入数据。
随后,本文利用时间卷积网络(TCN)与双向门控循环单元(Bi-GRU)神经网络构建了混合模型来估算电池SOH。在实验中,针对PF型号电池的数据进行了验证,结果表明在不同温度条件下,该模型依然能够保持较高的SOH估计精度。本文还进一步分析了不同电压窗口和不同特征组合对SOH估计的影响,提出了多步提前估计方法,并验证其有效性,在提前25步估计时,SOH的RMSE控制在2.6%以内。该方法的应用将有助于电池系统在实际操作中的效率提升和风险降低。
import numpy as np
import random
class GreyWolfOptimizer:
def __init__(self, obj_function, num_agents, max_iter, lb, ub):
self.obj_function = obj_function
self.num_agents = num_agents
self.max_iter = max_iter
self.lb = lb
self.ub = ub
self.positions = np.random.uniform(lb, ub, (num_agents, len(lb)))
self.alpha_score = float("inf")
self.beta_score = float("inf")
self.delta_score = float("inf")
def optimize(self):
for iteration in range(self.max_iter):
for i in range(self.num_agents):
fitness = self.obj_function(self.positions[i])
if fitness < self.alpha_score:
self.alpha_score = fitness
self.alpha_position = self.positions[i].copy()
elif fitness < self.beta_score:
self.beta_score = fitness
self.beta_position = self.positions[i].copy()
elif fitness < self.delta_score:
self.delta_score = fitness
self.delta_position = self.positions[i].copy()
a = 2 - iteration * (2 / self.max_iter)
for i in range(self.num_agents):
for j in range(len(self.lb)):
r1, r2 = random.random(), random.random()
A1 = 2 * a * r1 - a
C1 = 2 * r2
D_alpha = abs(C1 * self.alpha_position[j] - self.positions[i][j])
X1 = self.alpha_position[j] - A1 * D_alpha
r1, r2 = random.random(), random.random()
A2 = 2 * a * r1 - a
C2 = 2 * r2
D_beta = abs(C2 * self.beta_position[j] - self.positions[i][j])
X2 = self.beta_position[j] - A2 * D_beta
r1, r2 = random.random(), random.random()
A3 = 2 * a * r1 - a
C3 = 2 * r2
D_delta = abs(C3 * self.delta_position[j] - self.positions[i][j])
X3 = self.delta_position[j] - A3 * D_delta
self.positions[i][j] = (X1 + X2 + X3) / 3
self.positions[i][j] = np.clip(self.positions[i][j], self.lb[j], self.ub[j])
return self.alpha_position, self.alpha_score
# Objective function example
def objective_function(x):
return np.sum(x ** 2)
# Initialize and run optimizer
gwo = GreyWolfOptimizer(objective_function, num_agents=20, max_iter=50, lb=[-10, -10], ub=[10, 10])
position, score = gwo.optimize()
print(f"Optimized Position: {position}, Optimized Score: {score}")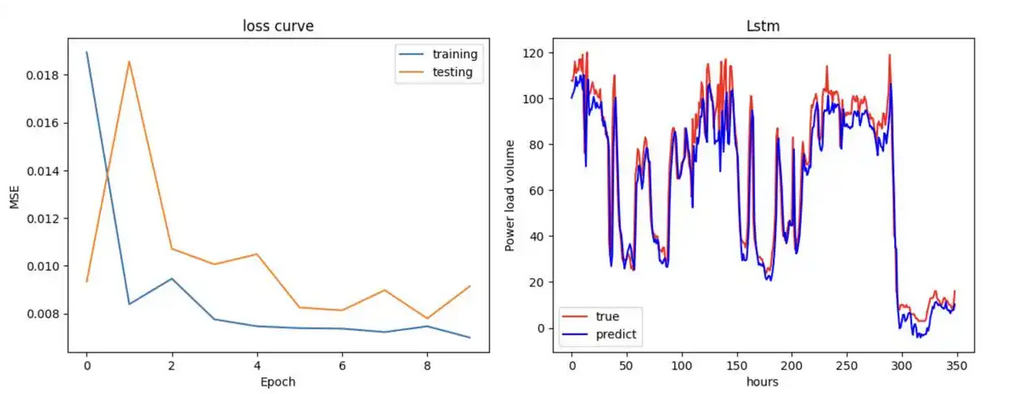



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











