






A Generalization of Transformer Networks to Graphs
基于稀疏性和位置编码这两个重要概念设计Graph Transformer架构
图的稀疏性
在NLP中,Transformer在词语特征表示时作为全注意力,也就是说,Transformer把一个句子中的词语当作全连接图看待。在NLP中这么设计有两个理由:
- 很难找到一个句子中单词之间有意义的稀疏联系。因此,使用完全集中注意力,让模型来决定单词对其他单词的依赖程度是有意义的。
- 在NLP中,这样的全连接图通常少于数十个数百个节点(即句子通常少于数十个或数百个单词)。在这个大小的图上,关注每个节点在内存和时间上都是可行的。因为这两个原因,全注意力在NLP中卓有成效。
然而,在实际的图数据集中,图具有基于应用领域的任意连接性结构,节点大小的范围可达数百万甚至数十亿。当在神经网络中学习时,可用的结构提供了丰富的信息来源,而节点太多使实际使用中不可能为这样的数据集构建全连接的图。所以一个节点关注相邻节点的稀疏性连接的Graph Transformer是实用有效的。
位置编码
位置编码
Transformer中的注意机制不受节点顺序的影响。它没有任何关于单词在序列(或句子)中的位置的概念。
为了避免这种情况并使Transformer能够感知顺序信息,Transformer中需要进行某种位置编码。Vaswani等人使用正弦位置编码[1],该编码在输入时加到每个单词的特征向量中,将词汇之间必要的顺序关系编码到模型中。
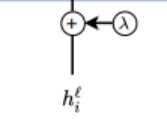
将位置信息编码设计块扩展到Graph Transformer中,(事实上最近对GNNs的一系列研究表明位置信息改善了GNNs)在Graph Transformer中使用了拉普拉斯位置编码,使用预先计算的拉普拉斯特征向量在第一层之前添加到节点特征中,类似于位置编码添加到原始的Transformer的方法。
Graph Transformer
Transformer
位置嵌入
大多数在图数据集上训练的GNNs学习的是不随node位置变化的结构化的node信息,这就是为什么GAT是局部attention,而不是全局。我们要学习结构和位置的特征,Dwivedi et al. (2020)利用图结构信息去预先计算拉普拉斯特征向量并作为node的位置信息,并把它作为PE用在Graph Transformer中,图的拉普拉斯矩阵:
Δ
=
I
−
D
−
1
/
2
A
D
−
1
/
2
=
U
T
Λ
U
\Delta = I- D^{-1/2}AD^{-1/2} = U^T\Lambda U
Δ=I−D−1/2AD−1/2=UTΛU
其中A为n×n邻接矩阵,D为度矩阵,Λ,U分别对应特征值和特征向量。我们利用一个节点的k个最小非平凡特征向量作为其位置编码,并对节点i用λi表示。最后,结论对拉普拉斯PE与现有的Graph-BERTPE进行比较。
Graph Transformer架构
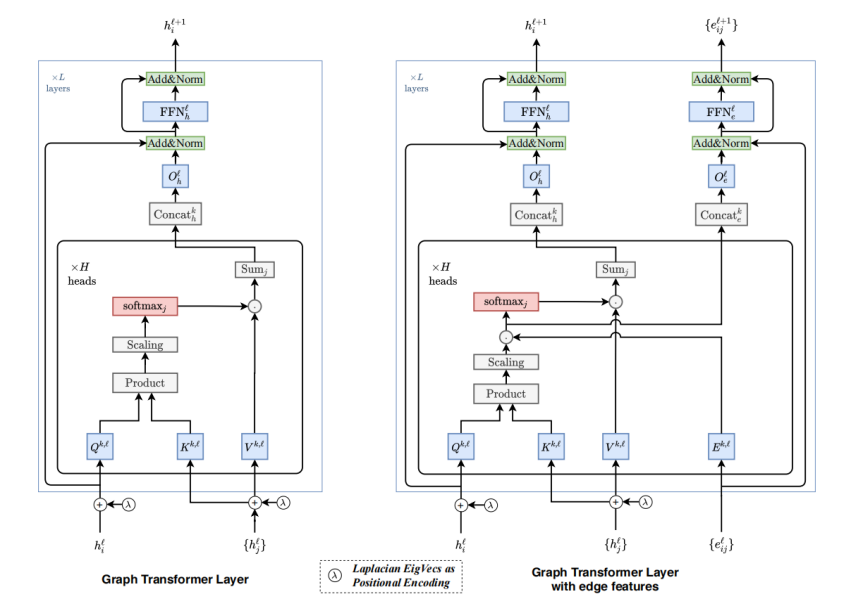
Graph Transformer Layer 和 Graph Transformer Layer with edge features的结构如图。第一个模型是为没有显式表示edge属性的图形设计的,而第二个模型设计了一个的edge特征的pipeline·,以合并可用的边信息,并在每一层保留它们的抽象表示。
Input
h
i
0
^
=
A
0
α
i
+
a
0
;
e
i
j
0
=
B
0
β
i
j
+
b
0
\hat{h_i^0} = A^0\alpha_i + a^0; e_{ij}^0 = B^0 \beta_{ij} + b^0
hi0^=A0αi+a0;eij0=B0βij+b0
其中,
α
i
∈
R
d
n
×
1
\alpha_i \in R^{d_n \times 1}
αi∈Rdn×1为每个节点i和边特征,
β
i
j
∈
R
d
e
×
1
\beta_{ij} \in R^{d_e \times 1}
βij∈Rde×1为每条边节点i和j的特征,
h
i
^
0
\hat{h_i}^0
hi^0表示节点特征。线性变换将node和edge映射为d维,同样对位置编码(PE)也做线性映射到相同维度,并将其与node的特征相加。
λ
i
0
=
C
0
λ
i
+
c
0
;
h
i
0
=
h
i
^
0
+
λ
i
0
\lambda_i^0 = C^0 \lambda_i + c^0 ; h_i^0 = \hat{h_i}^0 + \lambda_i^0
λi0=C0λi+c0;hi0=hi^0+λi0
拉普拉斯位置编码只和输入层的节点特征相加,没有加在中间层。
Graph Transformer Layer
Graph Transformer 和原始的Transformer结构非常相似。定义某一层的节点更新方程:
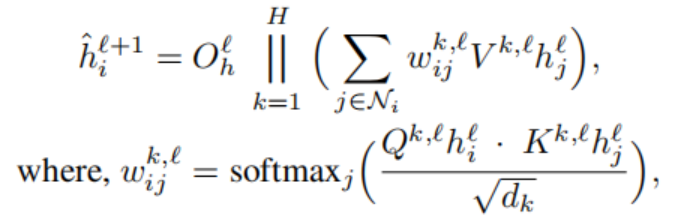
其中,||表示连接,
ω
i
j
\omega_{ij}
ωij表示K、Q的依赖关系即注意力机制,对应于Transformer中的Attention,为了训练稳定性,取softmax中各项的指数化后的输出限制到5~+5之间。上式
h
i
^
l
+
1
\hat{h_i}^{l+1}
hi^l+1是node的更新公式,注意力输出进一步输入一个前馈网络(FFN),残差连接和normalization层都和Transformer类似。

Granph Transformer Layer with edge features
具有edge特征的Graph Transformer更好地利用图数据集以edge attribute的形式提供的丰富特征信息。由于目标是更好地使用边特征,即对应于节点对之间的分数,我们将这些可用的边特征与通过成对注意计算的隐式edge分数联系起来。
上文中的softmax层之前的中间注意力wij可以认为是edge<i, j>的隐式信息。我们现在尝试将可用的edge信息注入,来提高已经计算好的隐注意力分数wij。方法是简单地将wij和eij相乘(见式12)。对于edge,我们还有一个节点对称边特征表示管pipeline,用于将边属性从一层传播到下一层
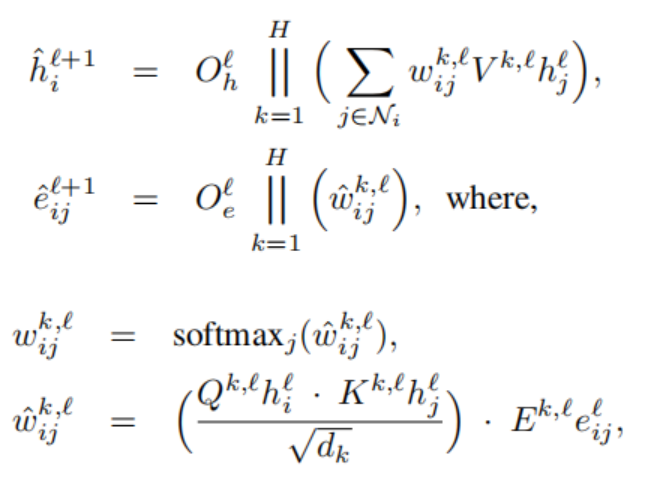
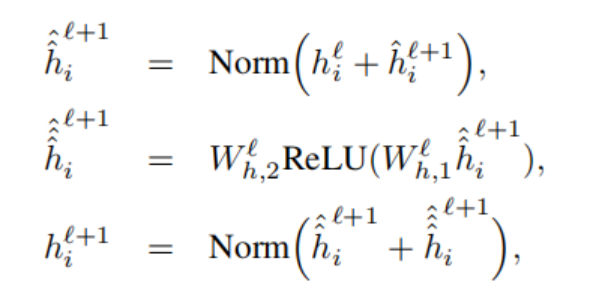
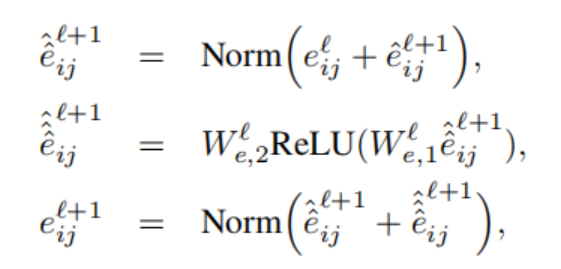
区别
- 注意机制是图中每个节点的邻域连通性的函数。
- 位置编码由拉普拉斯特征向量表示,与自然语言处理中常用的正弦位置编码类型。
- 将layer norm改为batch norm,提供了更快的训练和更好的泛化性能。
- 将该体系结构扩展到边缘特征表示,这对于化学(键类型)或链接预测(知识图中的实体关系)至关重要。
PS
1.拉普拉斯特征矩阵:L=D-W,其中D为度矩阵,W为领接矩阵

图
D
=
[
2
0
0
0
0
0
0
3
0
0
0
0
0
0
2
0
0
0
0
0
0
3
0
0
0
0
0
0
3
0
0
0
0
0
0
1
]
D = \begin{bmatrix} 2 & 0 & 0 & 0 & 0 & 0 \\ 0 & 3 & 0 & 0 & 0 & 0 \\ 0 & 0 & 2 & 0 & 0 & 0 \\ 0 & 0 & 0 & 3 & 0 & 0 \\ 0 & 0 & 0 & 0 & 3 & 0 \\ 0 & 0 & 0 & 0 & 0 & 1 \end{bmatrix}
D=
200000030000002000000300000030000001
W
=
[
0
1
0
0
1
0
1
0
1
0
0
0
0
1
0
1
0
0
0
0
1
0
1
1
1
1
0
1
0
0
0
0
0
1
0
0
]
W = \begin{bmatrix} 0 & 1 & 0 & 0 & 1 & 0 \\ 1 & 0 & 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 1 & 0 & 0 \\ 0 & 0 & 1 & 0 & 1 & 1 \\ 1 & 1 & 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 & 0 & 0 \end{bmatrix}
W=
010010101010010100001011100100000100
L
=
D
−
W
=
[
2
−
1
0
0
−
1
0
−
1
3
−
1
0
−
1
0
0
−
1
2
−
1
0
0
0
0
−
1
3
−
1
−
1
−
1
−
1
0
−
1
3
0
0
0
0
−
1
0
1
]
L=D -W = \begin{bmatrix} 2 & -1 & 0 & 0 & -1 & 0 \\ -1 & 3 & -1 & 0 & -1 & 0 \\ 0 & -1 & 2 & -1 & 0 & 0 \\ 0 & 0 & -1 & 3 & -1 & -1 \\ -1 & -1 & 0 & -1 & 3 & 0 \\ 0 & 0 & 0 & -1 & 0 & 1 \end{bmatrix}
L=D−W=
2−100−10−13−10−100−12−10000−13−1−1−1−10−130000−101
【参考论文】
Dwivedi, Vijay Prakash and Xavier Bresson. “A Generalization of Transformer Networks to Graphs.” ArXiv abs/2012.09699 (2020): n. pag.
Vaswani, Ashish et al. “Attention is All you Need.” ArXiv abs/1706.03762 (2017): n. pag.
Abbe, E. 2017. Community detection and stochastic block models: recent developments. The Journal of Machine Learning Research 18(1): 6446–6531.















 1049
1049











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









