






Rethinking BiSeNet For Real-time Semantic Segmentation
仅仅是自己做的笔记 别搞我 谢谢
主要创新点: 1 设计的STDC模块 具有可扩展的感受野核多尺度信息
2 细节聚合模块 在低层中就能保存空间细节 推理时候不需要额外成本
摘要
作者说双分支网络很受欢迎但是多加了一条分支太耗时,并且借用的是分类任务的backbone,没有专门为语义分割设计的.作者提出了STDC网络,逐渐减少特征图的维度.
介绍
这里没啥好说的,写论文的时候可以仿写,改改可以用. 主要是说分类任务的backbone不能很好适应分割任务.最后两段说了连接多个连续的特征图,为了加快速度,将层的卷积核个数逐渐减少
相较于添加另外一条分支,作者使用细节指导来指导低层学习空间特征(这个后面有介绍)
相关工作
三个方面介绍的:感兴趣可以自己去看
1: Efficient Network Designs 2 Generic Semantic Segmentation 3 Real-time Semantic Segmentation 感觉这里每篇论文写的都差不多 第一点可以看看
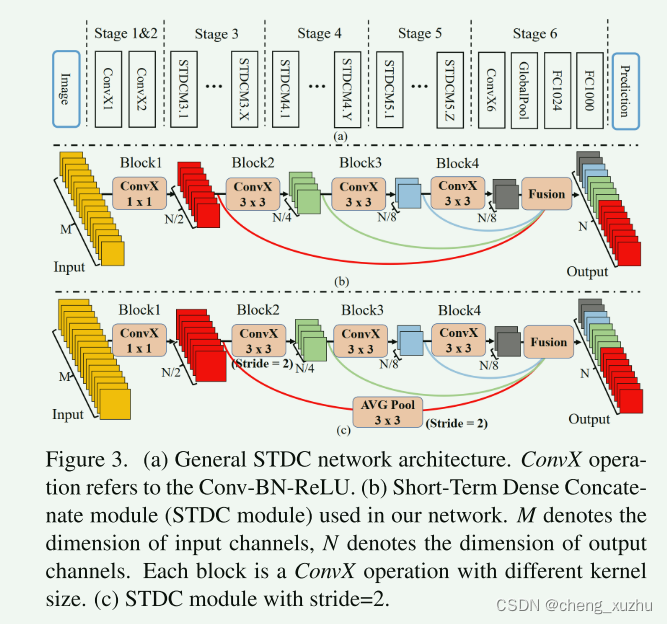
模型方法
STDC模块
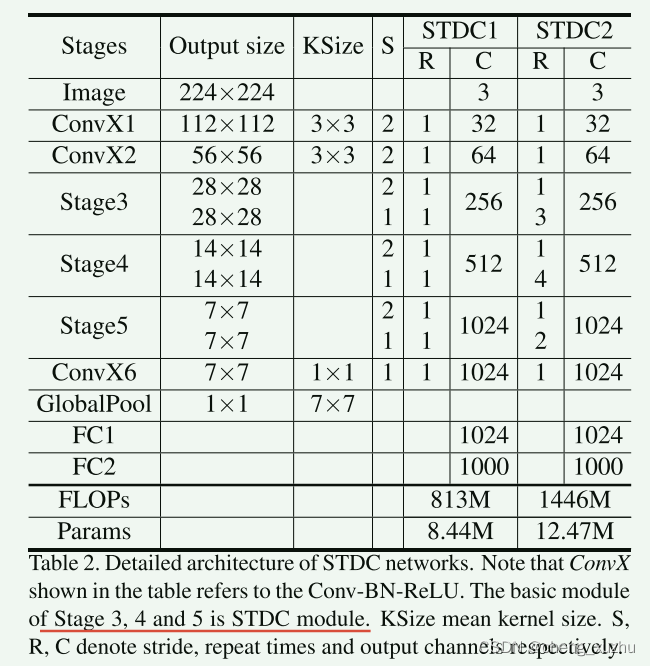
每个模块被划分为几个block 使用ConvXi表示它是模块中第几个block ConvX就是常见的conv+BN+Relu
在STDC模块中 只有第一个block的kernel size 是1 其余都是3 输入通道是3的话 第i块卷积层的卷积核数量是N/2的i次方 除了最后一个卷积层的卷积核个数和最后一个相同
图像分类任务中 越高的层使用更多的通道(卷积核) 但是语义分割任务中 更加关注感受野和多尺度信息 低层需要足够的通道来编码信息(其感受野较小) 高层有着更大的感受野 如果和低层设置一样的通道计算量较大 信息冗余 下采样发生在BLOCK2中 通过skip-path连接几个block的特征图来获得更丰富的特征信息 在连接之前block的特征图通过3*3池化大小的平均池化操作下采样到相同的空间大小
作者认为STDC模块有两个优势 1 递减的卷积核大小减少计算量 2 其最终输出由所有快连接而成 保留所有快 保留了可扩展的字段和多尺度信息
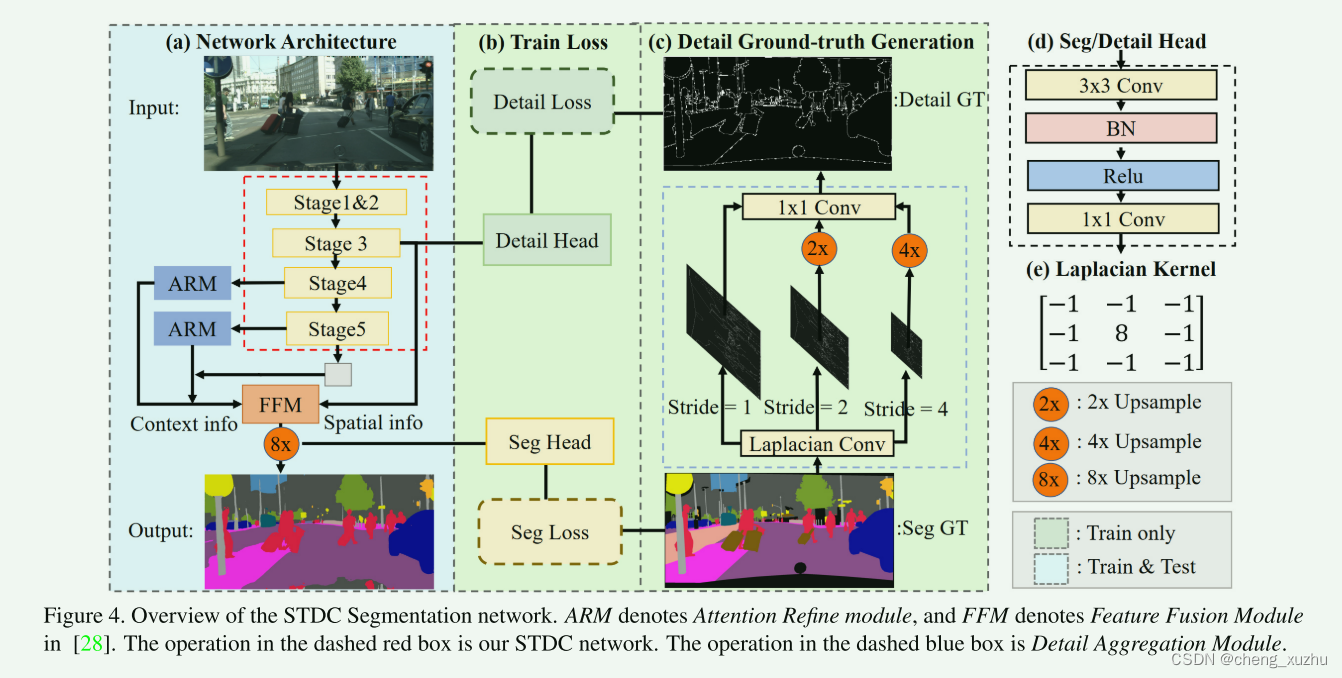
分割架构
enconder:用预训练的STDC网络作为backnone 用BIseNet的context path来提取上下文信息 看图4(a)使用stage345分别生成下采样比率为1/8,1/16,1/32的特征图 然后用全局平均池化提供有较大感受野的全局上下文信息
上采样用U形结构 但是只用了stage4 5 的特征 然后使用BIsenet中的ARM来细化每两个阶段的组合特征 仍然使用Bisenet中的FFM模块融合特征 (添加了stage3的特征) SegHead包含了一个3*3CONVBNRELU层然后跟了一个1*1卷积获得最后的维度(类别数)
Detail Guidance of Low-level Features
作者做了实验发现BiseNet中的spatial path 比stage3(也就是作者设计的stdc模块中的stage3(属于low-level layers)) 要有更多的细节 然后作者提出了用细节指导模块去指导low-level layers 来学习空间信息
作者将细节预测当成一个二元分割任务; 首先通过拉普拉斯算子从分割真实图中生成细节图真实值(感觉是拿ground-truth做的) 在stage3 插入了一个Detail Head 来生成细节特征图 然后使用细节真实值(detail ground-truth)作为细节特征图来指导低层学习空间细节特征 具有详细指导的特征图能有更多的空间细节
Detail Ground-truth Generation
接上面的 怎么生成的 Detail Guidance 通过细节聚合模块(图4里面的蓝色框) 生成二进制细节基础ground-truth (用拉普拉斯核算子来生成具有不同步长的soft thin detail feature 说真的这个不知道是啥) 然后将生成的细节特征图上采样到原始大小并且通过1*1卷积融合 最后,作者采用阈值 0.1 将预测细节转换为具有边界和角点信息的最终二进制细节ground-truth。
Detail Loss
因为细节像素的数量少于非细节像素的数量 所以他是一个类不平衡问题 作者采用二元交叉熵和骰子损失函数来联合优化细节许欸
骰子损失 对前景和背景不是很敏感 可以减轻类别不平衡问题 平衡预测图和真实图的重叠
实验细节设置
作者使用批量大小为 64、动量为 0.9、权重衰减为 1e−4 的小批量随机梯度下降 (SGD) 来训练模型。 采用三种训练方法,包括学习率预热余弦学习率策略和标签平滑。 总 epoch 为 300,前 5 个 epoch 采取预热策略,其中学习率从 0.001 开始到 0.1。 分类块之前的 dropout 设置为 0.2。
作者使用动量为 0.9、权重衰减为 5e−4 的小批量随机梯度下降 (SGD)。 Cityscapes、CamVid 数据集的批量大小分别设置为 48、24。 作为常见配置,作者利用“poly”学习率策略,其中初始率乘以 (1 − iter max iter )power。 功率设置为0.9,初始学习率设置为0.01。 此外,分别针对 Cityscapes、CamVid 数据集对模型进行 60、000、10、000 次迭代训练,其中在前 1000、200 次迭代时采用预热策略。
最后的实验结果自己看看原文就行了















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









