






 本文深入探讨了混淆矩阵的基本概念及其在R语言中的应用,详细解析了混淆矩阵中的各项参数,包括准确度、kappa值及P值的含义与计算方法。通过实例演示如何使用R语言的confusionMatrix函数来生成并解读混淆矩阵,为机器学习模型的性能评估提供了实用指南。
本文深入探讨了混淆矩阵的基本概念及其在R语言中的应用,详细解析了混淆矩阵中的各项参数,包括准确度、kappa值及P值的含义与计算方法。通过实例演示如何使用R语言的confusionMatrix函数来生成并解读混淆矩阵,为机器学习模型的性能评估提供了实用指南。
混淆矩阵的基本理解
以R语言输出结果为例
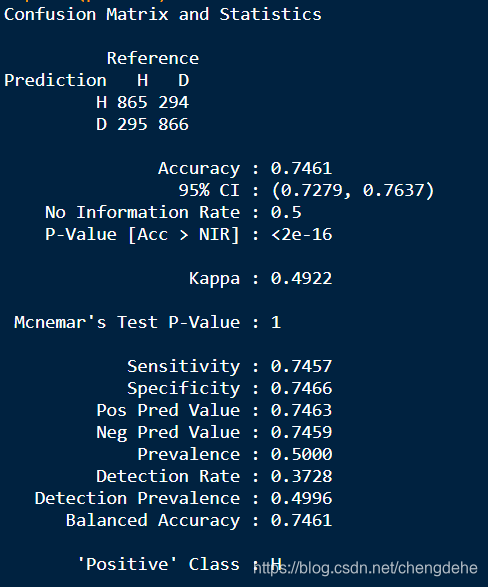
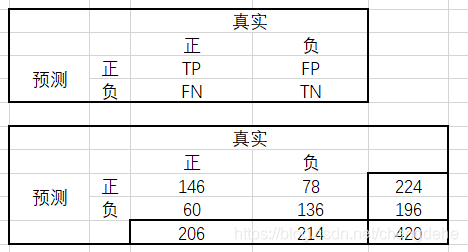
从下图理解混淆矩阵中个字母含义
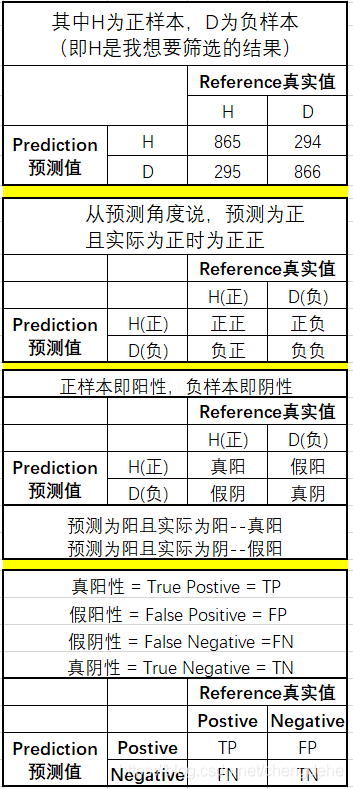
准确度的理解
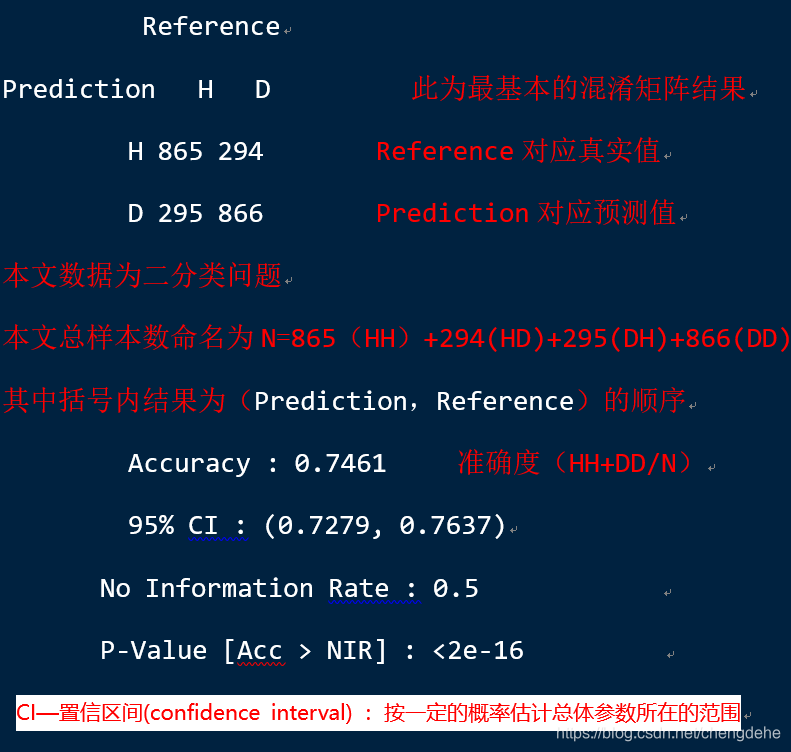
kappa值的理解及P值的理解,,,希望大神指教

各参数的解释
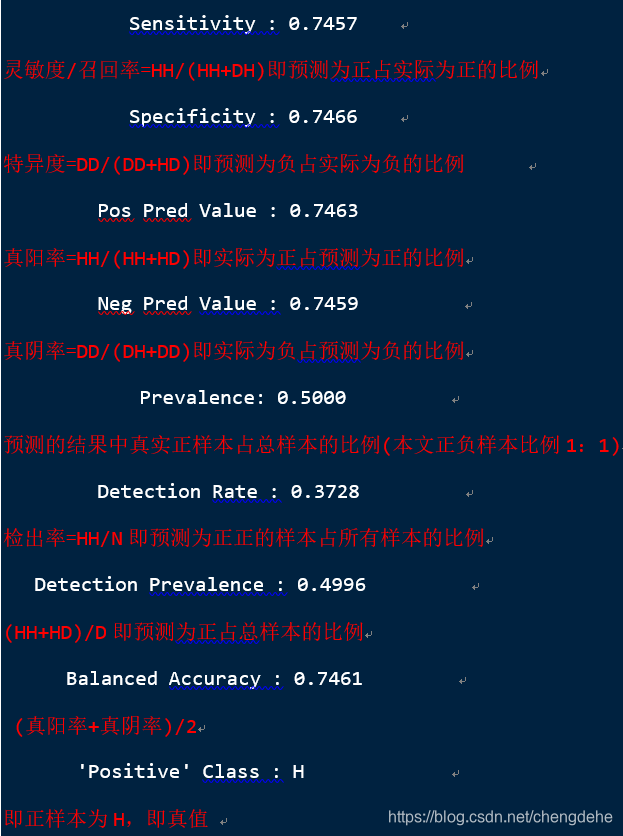
当进行结果提取时
##计算的混淆矩阵
pls.cmx <- confusionMatrix(data = pls_predicting, test$type)
结果提取
pls.cmx$byClass
提取各参数含义
计算公式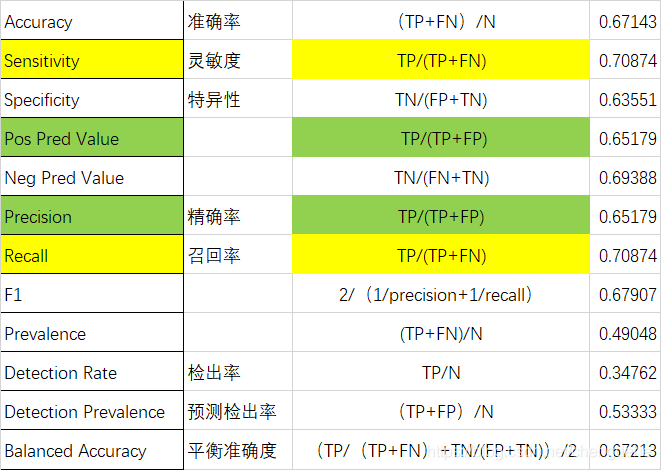 | |
|---|---|
混淆矩阵的基本理解
以R语言输出结果为例
从下图理解混淆矩阵中个字母含义
准确度的理解
kappa值的理解及P值的理解,,,希望大神指教
各参数的解释
当进行结果提取时
##计算的混淆矩阵
pls.cmx <- confusionMatrix(data = pls_predicting, test$type)
结果提取
pls.cmx$byClass
提取各参数含义
| 计算公式 | |
|---|---|
 590
590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























