







【本文章由高校教师徐博士撰写】
看过我们前面几篇机器学习系列文章后,相信大家现在对机器学习的理论都有了一定的了解。
今天我们继续介绍机器学习最经典也是使用最为广泛的模型——随机森林(Random Forest),该模型自2001年由Leo Breiman提出以来,就成为机器学习领域重要的分析工具。
在今天这篇文章中,我们将简单探讨随机森林的基本原理以及如何用R语言进行实践,大家也可以用文中的代码进行尝试。
什么是随机森林?
开门见山,随机森林这个名称真的非常符合这一模型的特点,我们结合下面的示意图来看随机森林模型的具体运算步骤:
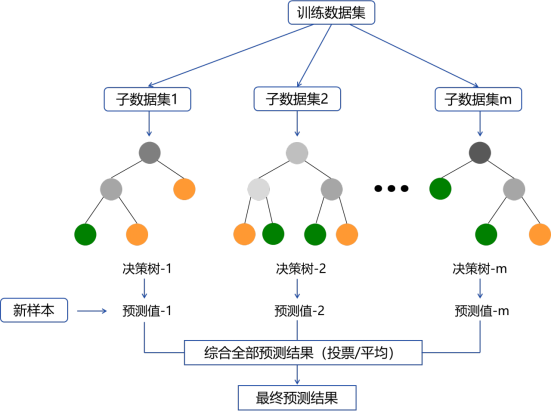
随机森林模型运算过程示意图
从上述示意图中,我们也能得出随机森林模型基本的分析思路:
1.从原始训练数据集中通过自助采样法(bootstrap sampling)有放回地随机抽取一定数量的数据,数量一般和原观测数相等,形成多个不同的子数据集;
2. 对每个子数据集训练一棵决策树,但决策树的每个决策节点不使用所有特征,而是随机选取部分特征,再从这些特征中根据数据“纯度”指标选择特征进行数据划分;
3.按照上述方式得到多棵不尽相同的决策树形成森林,对于测试数据集,综合所有决策树的预测结果得到最终预测结果。
例如对于分类任务,可以取所有决策树预测类别中数量最多的那一类作为个体的最终分类结果;
对于回归任务,可以取所有决策树预测结果的平均值作为个体的预测值。
可以发现随机森林能分成「随机」+「森林」两部分来理解,这个名称和模型特点相当贴切了。
上面3个步骤都不复杂,只要看懂了上一篇决策树的推文——《15分钟带你吃透决策树模型的三大经典算法》,相信很快就能够理解随机森林模型是怎么一回事了。
√除此之外,模型的开发动机、核心参数等问题也是有必要了解的,我们也借此机会解答大家最关心的三个问题:
提问 1
既然已经有了决策树算法,为什么还要开发随机森林算法呢?
回答
核心原因是决策树算法存在容易过拟合、模型结构不稳定的缺点,随机森林能够通过袋装法(Bagging)集成多棵决策树提高模型的泛化能力和稳健性。
通俗的说,就算决策树是诸葛亮,随机森林也至少是多个臭皮匠,多人决策的结果未必是最好的,但是是最
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5208
5208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









