






介绍
人工智能大模型是指使用大规模数据和强大的计算能力训练出来的 “大参数” 模型,通常具有数十亿甚至上千亿级别的参数。这些模型基于 Transformer 架构,在大规模数据集上完成预训练后,无需微调或仅需少量数据微调,就能直接支撑各类自然语言处理、图像识别、语音识别等领域的应用。
大模型的发展现状呈现出以下特点:在全球范围内,中美两国占据了大模型发布数量的 80% 以上。中国发布了众多大模型,主要集中在北京、广东、浙江和上海等地。市场上推出了 “文心一言”“通义千问”“混元助手”“盘古”“Deepsekk” 等大模型。这些大模型在多个领域取得了显著进展,如在教育领域赋能智慧课堂,在医疗领域提升诊疗水平,在金融、工业等领域也有广泛应用。
发展阶段
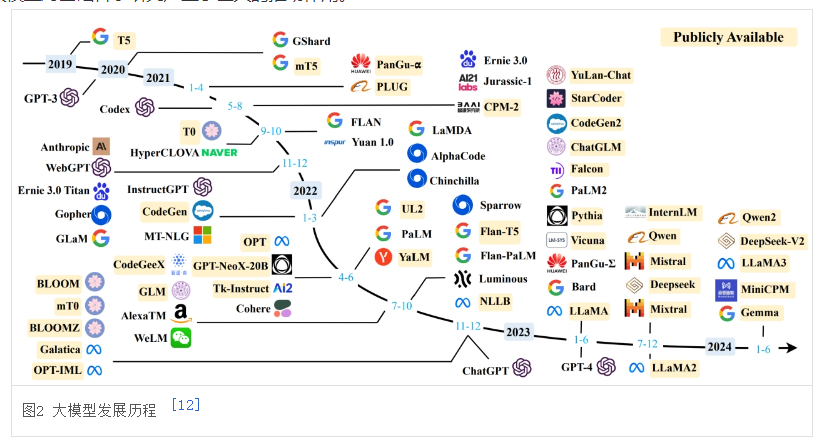
大模型的发展历史可以分为以下几个阶段:
早期探索阶段(1950 年 - 2005 年):1956 年,“人工智能” 概念在达特茅斯会议上被提出,AI 发展从基于小规模专家知识逐渐转向基于机器学习。1980 年,卷积神经网络的雏形 CNN 诞生,1998 年,现代卷积神经网络的基本结构 LeNet - 5 诞生,机器学习方法从早期基于浅层机器学习的模型,变为基于深度学习的模型,为自然语言生成、计算机视觉等领域的深入研究奠定了基础。
沉淀发展阶段(2006 年 - 2019 年):2013 年,自然语言处理模型 Word2Vec 诞生,首次提出 “词向量模型”。2014 年,GAN 诞生,标志着深度学习进入生成模型研究新阶段。2017 年,Google 提出 Transformer 架构,奠定了大模型预训练算法架构的基础。2018 年,OpenAI 和 Google 分别发布了 GPT - 1 与 BERT 大模型,预训练大模型成为自然语言处理领域的主流。
爆发成熟阶段(2020 年 - 至今):2020 年,OpenAI 公司推出 GPT - 3,模型参数规模达到 1750 亿,在零样本学习任务上实现巨大性能提升。2022 年 11 月,搭载 GPT3.5 的 ChatGPT 问世,凭借自然语言交互与多场景内容生成能力引爆互联网,各种大模型如 Gemini、文心一言、LLaMA 等纷纷涌现,2022 年也被誉为大模型元年。2023 年 3 月,GPT - 4 发布,具备多模态理解与多类型内容生成能力。2024 年,模型在多模态融合、推理能力等方面继续发展,如 Claude 3 系列、Gemini 2.0、ChatGPT - 4o 等;同时,高性价比推理模型出现,如 DeepSeek - V3、DeepSeek - R1 等。大模型应用也在加速落地,在社会生产、生活的多个方面产生广泛影响。
应用领域
国产大模型在以下领域应用较为广泛:
智能办公领域:如钉钉推出通义千问大模型版 AI 智能体 —AI 客服助理,能 7x24 小时在线,秒级响应用户问题,通过多轮对话理解用户真实需求,并有效回复 “产品参数对比” 等深度问题,还可关联钉钉工作流,实现用户反馈信息收集,自动同步至多维表、宜搭等应用,实现后续的多人协同和持续服务。
智能终端领域:国内厂商陆续推出搭载大模型的消费电子和智能终端产品,如联想集团发布了配备人工智能助理的个人电脑产品,通过本地部署的个人大模型,人工智能助理能与用户交互,还能总结经验并自我完善,根据用户信息进行推理、预测任务并提出建议;荣耀手机发布的新一代全场景操作系统,其大模型智能问答月使用量高达 1500 万次,日最高使用量达 85 万次,大模型的引入为手机带来功能跃升,如提炼通话内容要点、与手机 “对话” 自动挑选素材生成视频内容等。
内容创作领域:可以辅助编辑、作家进行创意写作和内容生成,例如在影视制作领域,视频大模型可以协助编剧生成剧本构思、对话及情节发展,提高创作效率,同时通过自动化剪辑、特效制作等技术,大幅降低制作成本,缩短制作周期。
教育领域:如浪潮信息的源大模型在教育领域处于试点示范期,可以结合教师的课程资料,构建智能教学辅导系统,能够理解学生的疑问,并提供即时反馈和解释,提供一对一的辅导体验,减轻教师教学负担,提升教学质量。
金融领域:为银行提供智能客服与风险评估工具,提高客户服务效率与风险控制能力。比如智能客服可以快速准确地回答客户关于账户信息、理财产品、贷款申请等方面的问题,提供个性化的服务和建议;在风险评估方面,通过分析大量的金融数据,对贷款申请人的信用风险、市场风险等进行评估和预测,帮助金融机构做出更明智的决策。
医疗领域:例如蚂蚁集团的百灵大模型推出了 “AI 就医助理” 解决方案,上海市第一人民医院应用这一解决方案打造了 “数字陪诊师”,联合浙江省卫健委打造了全流程就医陪诊服务首个数字健康人 “安诊儿”,还推出 “AI 健康管家” 涵盖多种服务;此外,大模型还能快速处理 X 光、CT、MRI 等医学影像,精准识别并判断其良恶性,整合多源数据预测疾病风险,辅助医生制定科学治疗方案。
智能制造领域:如中国联通的元景大模型在智能制造领域处于落地探索期,可辅助工程技术人员,提供面向自然语言的智能交互与问答功能,辅助员工进行精准式知识检索、快速故障定位、提升客户请求答复质量,优化服务解决方案。
自动驾驶领域:大模型加快在智能网联汽车上部署应用,除了在智能座舱里与人交互更自然、识别车内外的人与物更准确,还能提升自动驾驶系统的效率和安全。云端大模型可完成大量数据标注、数据融合等任务,车端大模型能节省车端计算的推理时间,助力自动驾驶技术开发应用。
城市治理领域:中国联通的元景大模型在城市治理领域处于试点示范期,为一线人员提供技术支撑,使其及时掌握跨领域的司法知识和技能,迅速提高工作效率和服务质量。例如在城市规划、交通管理、公共安全等方面,大模型可以通过分析大量的数据,提供决策支持和预测分析,帮助城市管理者更好地规划和管理城市。
国产大模型发展趋势

国产大模型的发展呈现出以下趋势:
技术迭代加速:
性能不断提升:随着技术的不断进步,国产大模型在语言理解、生成、推理等方面的能力将不断提高,能够更好地满足各种应用场景的需求。例如,一些大模型在文本生成方面的质量和准确性已经有了显著提升,生成的内容更加自然、流畅、有逻辑。
多模态融合发展:越来越多的国产大模型开始注重多模态技术的融合,将文本、图像、语音等多种模态的数据进行综合处理,实现更强大的感知和理解能力,为用户提供更加丰富和全面的服务。如字节跳动的云雀模型等在多模态方面也有积极的探索和发展。
应用场景拓展:
千行百业深度赋能:大模型将广泛应用于工业、农业、金融、医疗、教育等各个领域,推动各行业的数字化转型和升级。在工业领域,帮助优化生产工艺、提高产品质量和生产效率;在农业领域,实现精准农业、病虫害预测等;在金融领域,用于风险评估、智能客服、投资决策等;在医疗领域,辅助诊断、提供治疗方案建议、药物研发等;在教育领域,实现个性化学习、智能辅导等。
消费级应用创新:在消费领域,国产大模型将为智能音箱、智能家电、智能驾驶等产品带来更智能的交互体验和功能升级。例如,智能音箱可以更准确地理解用户的指令,提供更贴心的服务;智能驾驶系统可以更好地感知路况和交通信息,提高驾驶的安全性和舒适性。
开源生态发展:开源成为国产大模型的重要发展方向。一方面,开源可以吸引更多的开发者参与到模型的改进和应用开发中,形成良好的社区生态,推动大模型技术的快速发展;另一方面,也有助于降低算力成本,让更多的企业和开发者能够使用和创新大模型。像字节豆包、昆仑万维、百度文心、阿里通义千问等都推出了开源模型,商汤科技发布了 LazyLLM 开源框架等产品。
政策支持力度加大:国家和地方政府陆续出台一系列政策支持人工智能产业包括大模型的发展,如提供研发补贴、算力补贴、税收优惠等,鼓励企业和科研机构加大研发投入。同时,政府也在推动相关法律法规的制定,规范大模型的发展,保障数据安全和隐私等。例如,2025 年两会期间,《人工智能发展与安全法》正式启动立法程序,国务院宣布设立千亿级 AI 产业引导基金,并推出 “人工智能 +” 国家行动计划。
产业生态完善:
产业链上下游协同发展:大模型产业的上下游企业,包括算力提供商、数据供应商、算法研发企业、应用开发商等,将加强合作,形成完整的产业链生态,共同推动大模型产业的发展。例如,算力企业为大模型训练提供强大的计算能力,数据企业为模型训练提供高质量的数据,应用开发商将大模型应用于各种具体场景中,实现商业化落地。
区域产业集群形成:一些地区将通过政策引导和资源集聚,形成人工智能产业集群,促进大模型相关企业和人才的集中,实现产业的协同发展和创新。如上海的模速空间,作为全国首个大模型创新生态社区,几乎浓缩了大模型产业链的每一环。
不过,国产大模型在发展过程中也面临一些挑战,如算力瓶颈有待突破、数据质量和标注成本需要优化、高端人才短缺等。但总体而言,在技术进步、市场需求和政策支持等多方面因素的推动下,国产大模型的发展前景广阔,有望在未来取得更大的突破和成就。

发展风险
大模型发展存在诸多风险。在数据层面,训练数据的偏差、隐私泄露及数据滥用问题突出,可能导致模型输出有偏见的结果并侵犯用户隐私 。从技术角度看,模型的可解释性差,难以理解其决策逻辑,不利于发现潜在错误;算力需求庞大,带来能源消耗与成本压力,且可能造成技术垄断。社会影响方面,大模型生成内容的真实性难辨,易引发虚假信息传播,扰乱舆论环境,甚至可能被恶意利用,威胁网络安全与社会稳定,在就业领域也可能冲击部分岗位,带来结构性失业风险。

















 169
169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









