






根据最优化理论,在损失函数上增加正则项其实等价于正则项有限制条件的情况下最小化损失函数。例如,带正则项的目标函数为:
 (1)
(1)
等价于在条件
 (2)
(2)
下,最小化least squares的损失函数。这两种等价形式可以根据拉格朗日乘子法关联起来。(1)中的Lambda越大,(2)中的Yita就越小。
那么很显然,选择更大的Lambda,就会使得w的值限制更严格,趋于更小的值。
在(2)中,不同的q值,对应了w的不同的可行解(?)空间。下图是2维参数空间里,不同q值产生的可行解空间的边界。坐标轴分别是我w1 和 w2
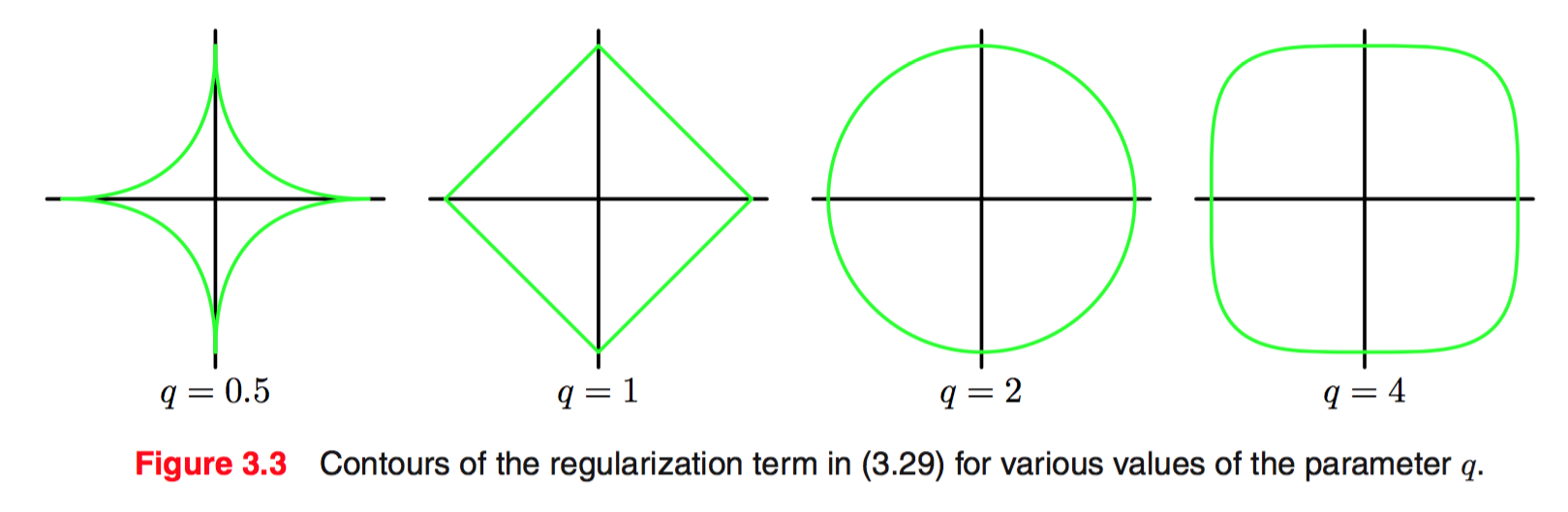
如果目标函数是凸的,且最优解不在可行解空间内(否则正则项不起作用),那么显然q <= 1 相比于 q > 1的情况,会有更大的可能性在坐标轴上取得极小值——该坐标轴对应的w值为0。

reference:
http://www.andrewng.org/portfolio/efficient-l1-regularized-logistic-regression/















 9344
9344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









