







“iCaRL: Incremental Classifier and Representation Learning”(CVPR 2017)
Motivation
Methods
- 数据集构建
- 从上述算法流程图可以看出来,作者设计了一个memory set来存放旧任务的数据。假定memory set的容量为K,当前模型已经见过的类别数目为m,那么在memory set中,每个类别存放的样本个数为K/m,在这里值得注意的一点是,m是动态变化的。经由上述分析可知,该memory set至少满足以下两条属性:
- 能够随时添加新任务的数据(保证样本集的类别质心尽可能靠近训练集的类别质心)
- 能够动态丢弃旧任务所保存的数据,并尽可能保留旧任务中比较重要的信息

如何向exampler set扩充新样本?

如何删除exampler set中的旧样本?

- 从上述算法流程图可以看出来,作者设计了一个memory set来存放旧任务的数据。假定memory set的容量为K,当前模型已经见过的类别数目为m,那么在memory set中,每个类别存放的样本个数为K/m,在这里值得注意的一点是,m是动态变化的。经由上述分析可知,该memory set至少满足以下两条属性:
- 损失函数设计
损失函数主要包括了两个部分:一个是calssification loss,一个是distillation loss.其中,classification loss主要是针对当前新任务下的训练样本设计的,也就是我们常提到的交叉熵损失函数,另一个的ditillation loss,主要是为了让模型保存其在旧任务中学到的知识

- 模型的预测
查找距离当前样本最近的类别中心来给样本分配标签,类似于聚类的做法。细节如下:
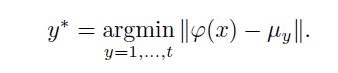
“Leanring without forgetting”(ECCV 2018, TPAMI 2019)
Motivation
现有的关于continual learning的方法主要分为以下三大类:
- Feature Extraction
- 这类方法通常会固定住共享网络以及old task head分支的参数,单独训练new task head分支
- Fine-tuning
- 这类方法主要微调共享网络的参数,固定old task head分支的参数,并重新训练new task head上的参数
- Joint training
- 这类方法会同时给网络输入所有的训练数据,并从头到尾训练整个模型
上述三种方式的缺陷在于:
- 基于Feature extraction的方法,通常在新任务上的表现会比较差,旧任务上表现性能则比较好,原因是共享网络的参数被固定住了,并没有很好地学习到对于新任务而言更加具有鉴别力的特征;
- 基于Fine-tuning的方法在新任务上的表现性能相对好一些,但是在旧任务上的表现性能则相对差一些,这是因为每次在训练新任务的过程中,并没有旧任务的数据加以引导;
- 基于joint-training的方法通常是continuing learning方法的上界,但是这类方法通常会用到旧任务的数据,此外,其训练的难度也会随着任务数量的增加而增大。
Methods

LwF与前人方法相比,一方面,其在学习新任务的过程中,始终没有用到旧任务的数据;另外一方面,其借鉴了知识蒸馏的思想,通过对齐新任务分支和旧任务分支的输出,来尽可能保留旧任务上学到的知识。
具体算法思想如下:
















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









