







 本文介绍了假设检验在数据分析和机器学习中的重要性,用于判断样本间或样本与总体的差异是否由抽样误差引起。文章详细阐述了假设检验的基本概念、步骤、原假设与备择假设的选择、统计量与拒绝域,并通过双边和单边检验的实例进行解释。此外,还展示了如何利用Python进行假设检验的计算。
本文介绍了假设检验在数据分析和机器学习中的重要性,用于判断样本间或样本与总体的差异是否由抽样误差引起。文章详细阐述了假设检验的基本概念、步骤、原假设与备择假设的选择、统计量与拒绝域,并通过双边和单边检验的实例进行解释。此外,还展示了如何利用Python进行假设检验的计算。
前言:
前面讲过置信区间,置信度的概念,这里假设检验也很容易理解
假设检验在机器学习中,对数据分析非常有用。 例如,根据一组数据训练出来一个
模型准确率很高,但是在测试集上效果很差。这个时候怀疑是否是同一组数据,
那么通过假设检验,来确定是否为同一组分布。
常用的基础知识还是常见的4种分布,正太分布,t分布,F分布,卡方分布
目录
1: 假设检验基本概念
2: 假设检验基本步骤
3: 原假设和备择假设
4: 统计量与拒绝域
5: 例子
一 假设检验的基本概念
假设检验(hypothesis testing),又称统计假设检验,是用来判断样本与样本、样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。显著性检验是假设检验中最常用的一种方法,也是一种最基本的统计推断形式,其基本原理是先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。
常用的假设检验方法有Z检验、t检验、卡方检验、F检验等
二 假设检验基本步骤
主要有两种方案,效果基本相同,常用的是第一种
2.1 Neyman-pearson 方案
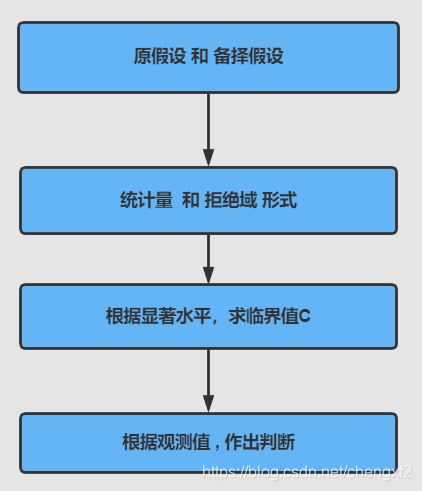
2.2 P_值法
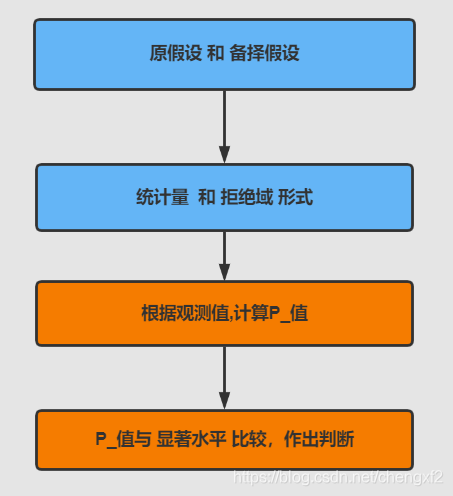
三 原假设和备择假设
3.1 原假设和备择假设
H0: 原假设 H1: 备择假设
通常依照如下优先级:
3.1 严重性:
如果错误的拒绝A ,比错误的拒绝B 更严重,则 A作为原假设
例: A假设: 某种药物有毒 B 假设: 某种药物无毒
如果错误的拒绝A(A药品实际有毒,被当作无毒,FN),
显然比错误的拒绝B 假设更 严重
所以A作为原假设假设
医生诊断也是把病人有病 作为原假设。
3.2 维持现状
当严重性差不多的时候,采用 无效果,无改进,无作用作为原假设.
例如同一个模型,机器学习训练的多次loss值有所偏差。
3.3 取简单假设
例如 A 只对一种可能做了假设,B 对多种假设做了可能,则通常选A做H0

H0 为真(P) ,预测为N, 称为第一类错误,弃真概率尽量要低
H0 为 假(N),预测为P, 称为第二类错误,取伪概率尽量要低
这是一对矛盾。全部预测为真,弃真概率为0,但是取伪概率就会很高。
四 统计量与拒绝域
4.1 统计量
根据参数的情况,确定随机变量的形式
例如 方差,均值已知
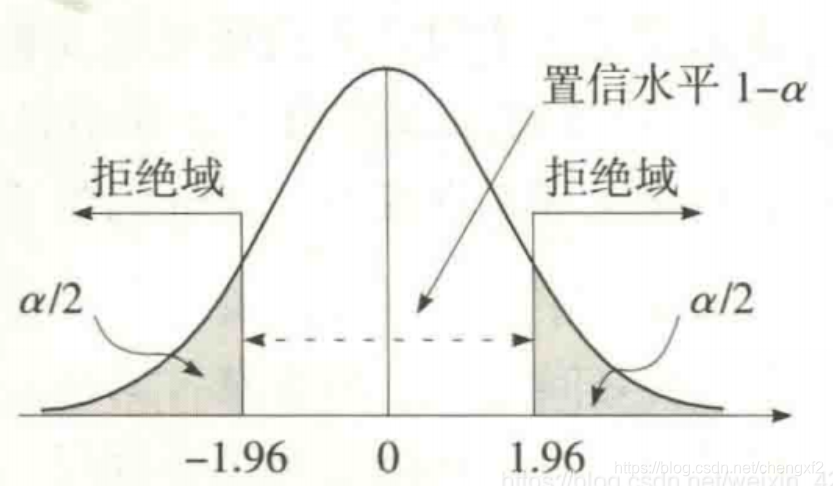
4.2 拒绝域
通常有三种形式
当统计量的值,落在拒绝域内,小概率事件发生了,也就是不可能事件。
则拒绝该假设(假设不发生),对立事件发生。
根据备择假设的情况分为三种情况:
3.1: 左边检验
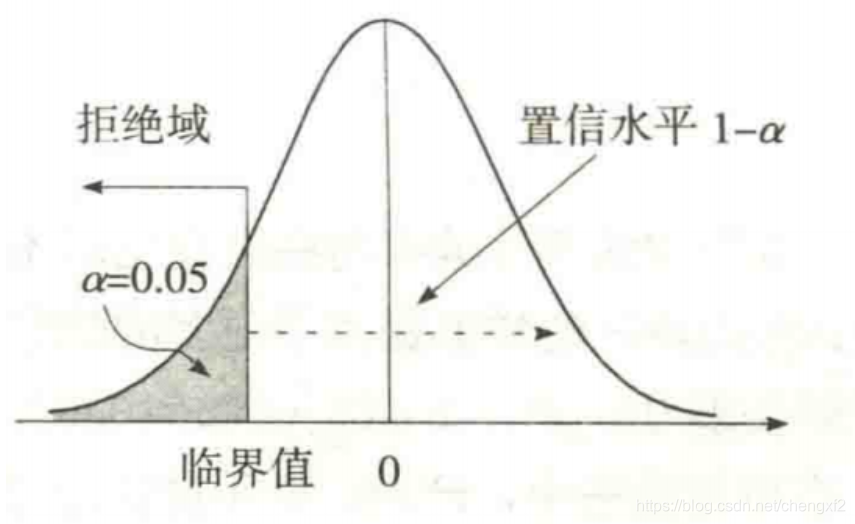
3.2 右边假设
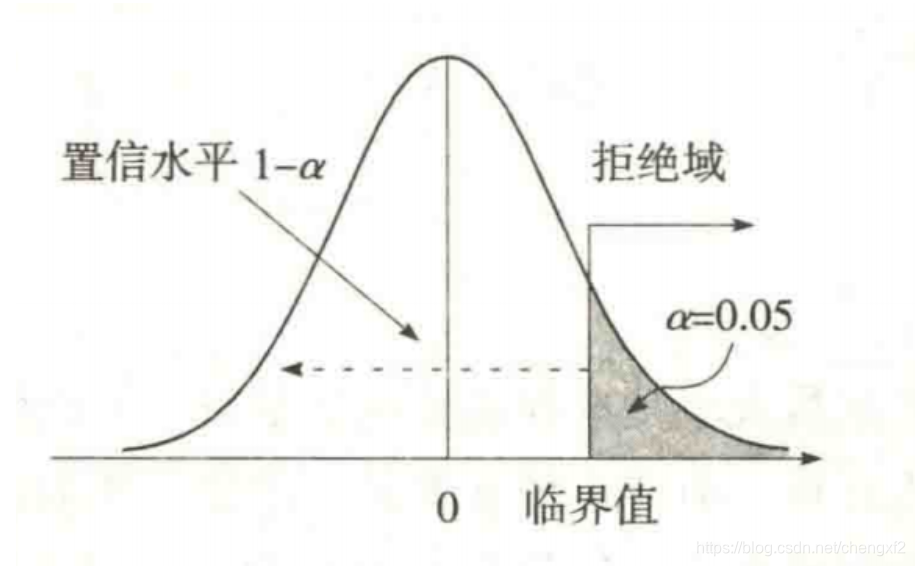
3.3 双边假设
五 例子
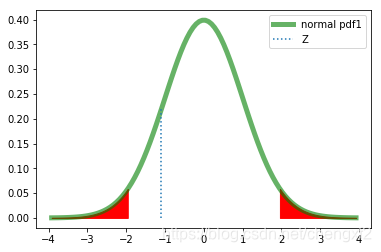
5.1 双边例子
某公司72人参加体检,指标平均值126.07.
已知该指标均值为128,方差为15.
该公司与总体是否有差异?
解:
step1: 做出假设
step2: 统计量以及拒绝域形式
step3 根据置信度求解 拒绝域C
Z< -1.96 & Z>1.96
step4 判断
Z0 落在拒绝域外,所以认为无差异
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 20 17:23:58 2021
@author: chengxf2
"""
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 20 15:13:21 2021
@author: chengxf2
"""
import numpy as np
from scipy.stats import norm #标准正太分布
from scipy.stats import chi2 # 卡方分布
from scipy.stats import t # t分布
from scipy.stats import f # F分布
import seaborn as sns
import matplotlib.pyplot as plt
def Test():
x = 1-norm.cdf(1.09)
print("\n x: ",2*x)
'''
画双边拟合曲线
z: 统计量
'''
def Draw(alpha,z):
fig,ax = plt.subplots(1,1)
a = norm.ppf(alpha/2) #拒绝域分位数
print("\n 拒绝域 -------",a)
x_low = np.linspace(2*a,a,100)
y_low = norm.pdf(x_low) #概率密度函数
x_high = np.linspace(-a,-2*a,100)
y_high = norm.pdf(x_high)
x_norm = np.linspace(2*a,-2*a,100) #标准正太分布
y_norm = norm.pdf(x_norm) #概率密度
z_y = norm.pdf(z) #统计量
a =[z,z]
b= [0,z_y]
#ax.plot(x,y,'r-',lw=5,alpha=0.6, label='normal pdf')
ax.plot(x_norm,y_norm,'g-',lw=5,alpha=0.6, label='normal pdf')
plt.fill_between(x_low, y_low, color = "r", alpha = 1.0) #填充坐标轴之间的空间
plt.fill_between(x_high, y_high, color = "r", alpha = 1.0) #填充坐标轴之间的空间
plt.plot(a, b,linestyle = 'dotted',label='Z')
plt.legend()
'''
根据置信度获得拒绝域
双边检验
'''
def GetRejectArea(alpha):
low = norm.ppf(alpha/2) #拒绝域【-inf, x]
up = norm.ppf(1-alpha/2)
print("\n 拒绝域 %4.2f"%low,up)
#因为是正太分布,为对称的
#Draw(alpha)
return np.abs(low)
'''
假设检验
H0: U=U0
H1: U<U1
左边检验
方法1: 统计量Z 与 C比较
方法2: 累计积分P 与 alpha 比较
'''
def hypothesis():
x_mean = 126.07 # 样本均值
u = 128 #假设值
n = 72 # 样本个数
var = 15 #样本方差
Z = (x_mean-u)/(var/np.sqrt(n))
print("\n 统计量Z%4.3f :"%Z)
#p = norm.cdf(Z)
#print("\n p: ",p)
C = GetRejectArea(0.05)
Draw(0.05,Z)
if Z<C:
print(" H1 成立")
else:
print(" ,H0 成立")
hypothesis()
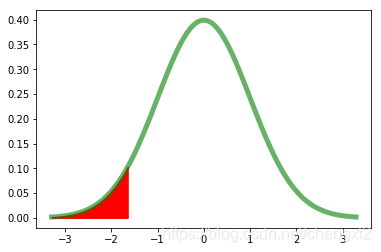
5.2 单边例子
某个学校A,随机抽取225 个学生,平均月消费1530元。
假设学生的消费服从正态分布,标准差为120.
高校B,月平均消费为1550元。是否可以认为高校A 消费水平低于高校B
解:
1: 做出假设
H0: U=1550 H1: U<1550
为左边假设
2: 解统计量,以及拒绝域的形式
因为服从正态分布
3: 根据显著水平,求解临界值C
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 20 15:13:21 2021
@author: chengxf2
"""
import numpy as np
from scipy.stats import norm #标准正太分布
from scipy.stats import chi2 # 卡方分布
from scipy.stats import t # t分布
from scipy.stats import f # F分布
import seaborn as sns
import matplotlib.pyplot as plt
'''
画出拟合曲线
'''
def Draw(alpha):
fig,ax = plt.subplots(1,1)
a = norm.ppf(alpha)
print("\n 拒绝域 -------",a)
x = np.linspace(2*a,a,100)
y = norm.pdf(x)
x_norm = np.linspace(2*a,-2*a,100) #标准正太分布
y_norm = norm.pdf(x_norm) #概率密度
#ax.plot(x,y,'r-',lw=5,alpha=0.6, label='normal pdf')
ax.plot(x_norm,y_norm,'g-',lw=5,alpha=0.6, label='normal pdf1')
plt.fill_between(x, y, color = "r", alpha = 1.0) #填充坐标轴之间的空间
'''
根据置信度获得拒绝域
'''
def GetRejectArea(alpha):
c = norm.ppf(alpha) #拒绝域【-inf, x]
print("\n 拒绝域 %4.2f"%c)
#x = norm.rvs(loc=0, scale=1, size=10000)
#sns.distplot(x)
#pdf : 概率密度函数
Draw(alpha)
return c
'''
假设检验
H0: U=U0
H1: U<U1
左边检验
方法1: 统计量Z 与 C比较
方法2: 累计积分P 与 alpha 比较
'''
def hypothesis():
#x = [1.5,0.6,-0.3,1.1,-0.8,0,2.2,-1.0,1.4]
x_mean = 1530 # 样本均值
n = 225# 样本个数
var = 120 #样本方差
u = 1550 #H0 U=U0
Z = (x_mean-u)/(var/np.sqrt(n))
print("\n 统计量Z :", Z)
p = norm.cdf(Z)
print("\n p: ",p)
C = GetRejectArea(0.05)
if Z<C:
print(" H1 成立")
else:
print(" ,H0 成立")
hypothesis()
4 : 做出判断
概率: 0.006209665325776132(方法2: <显著水平0.05,拒绝该假设)
统计量Z : -2.5
拒绝域 -1.64
H1 成立

















 5084
5084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









