







一: 本文的目的
如题目所说的,本文的主要工作是提出一个深度逐步改进的强化学习方法来做基于骨架的动作识别。说白了,就是做基于骨架数据的动作识别。

如上图所示,给定一个输入:vedio,然后最终目的是输入一个标签能判断这个视频中的模型在做什么动作。
思路简单概括为:
1. 我们的输入是一段视频,视频中有多个帧。
2. 我们想用RL的算法来选择关键帧(本文是FDNet)
3. 再把选取到的关键帧输入到GCNN网络,得到这个vedio的标签
二: 定义问题的决策链
由于要用RL来解决问题,那么就需要先把问题转化为一个决策链的问题
- 已知输入的是含有多个帧的一段视频,但我们不要全部用到全部帧数
- 所以我们想提取关键帧,设定提取的关键帧数为 m m ,把这个关键帧按序号排序,每一个action表示这些关键帧是要向左移动,向右移动或是保持当前位置。
- 设定迭代步数,当程序迭代步数达到设定值时,就停止程序

三: State and Action
State
- 针对选关键帧这个MDP问题,状态
S
S
可以表示为:
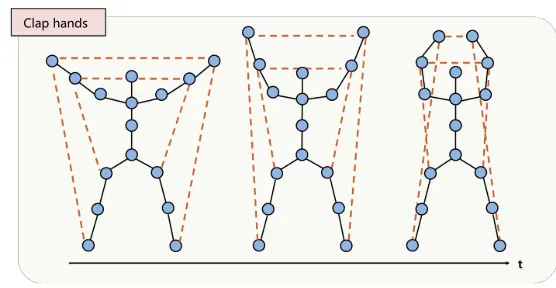
即它由来两部分组成,其中 Sa=[F,M] S a = [ F , M ] 也是由两部分组成的。 F F 表示整个视频的信息, 它张量的形状为:。 其中 f f 表示视频的所有帧数,表示每一帧中的骨架模型的节点数, 3 3 表示每一个骨架节点的3D坐标。 如下图所示是一个拍手动作的其中三帧,每一帧都是用一些骨架信息表示,其中包含了骨架中有多少个关节节点以及它们的3D坐标。

对于就表示所有被提取的关键帧信息,用一个形如 m×N×3 m × N × 3 的张量表示,其中 m m 表示关键帧的数目
- 最后one-hot, 它对应到整个视频的每一帧,如果对应的元素值为1,那么说明该帧被提取为关键帧,其余则为0

Action
action的动作由FDNet输出
action的定义比较简单:
1. 帧向左移动
2. 帧向右移动
3. 帧保持不动
现在,我们打开看一下FDNet网络的结构

上图的执行流程如下
1.
Sb
S
b
经过一个全连接层得到一段向量
2.
Sa
S
a
经过3层卷积后,在经过一层全连接层得到另一段向量
3. 将上面两个结果合并起来,通过一个全连接层输出结果
4. 输出的结果由3个3个神经元组成,每一组神经元表示对应关键帧的action分布
四: Reward function

- 在本文的算法框架下,reward是由GCNN产生的(GCNN是什么下面说)
- GCNN拿 m m 个关键帧作为一个输入
初步的reward可以表示为:
其中 c c 是视频标签的ground truth此外,我们还需要对reward做一些改善: 如果预测的action是从不正确的关键帧跳到正确的关键帧,那么就会追加一个大的奖励,如果预测的action是从正确的关键帧跳到不正确的关键帧,那么就会给一个大的惩罚。最后reward表示如下
五: GCNN
GCNN 是基于图的卷积
1.首先,我们看看图是如何构建出来的:
我们根据上面的公式来构建图。为什么关节不相互连接都要给权重呢?比如看下面这个拍手的动作,左右手虽然没有相互连接,但是它们之间是有一定的位置关系的,即能体现出拍手这么个动作信息
图的卷积
- 首先,给定 T 个关键帧,根据上面第一点提到的公式构建图 [1,2,...,T] [ G 1 , G 2 , . . . , G T ]
- 对每一个图,都进行卷积操作:
zt=y(η,W)∗xt z t = y ( η , W ) ∗ x t
- 卷积过后再用全连接层处理,得到一个输出向量 gt g t
- 最后把所有的输出向量合并起来
G=concat[g1,g2,...,gT] G = c o n c a t [ g 1 , g 2 , . . . , g T ]
GCNN的输出
对于2的输出结果,用熵函数作用后,就得到了我们的reward(训练时作为reward, 测试时作为标签)
算法和实验
















 2637
2637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









