







本文是在做课题组研讨会时的报告,仅代表我个人的理解,错误之处,请直接指出!
Batch Normalization 的意思是 批正规化。意思就是从所有的数据中选取一部分或者叫做一批数据进行正规化。
Internal corvariate shift:由于在训练过程中上一层的参数的变化导致了本层输入分布的变化。这会减缓学习速率,而且需要小心的选择初始参数。
首先来看一幅图。
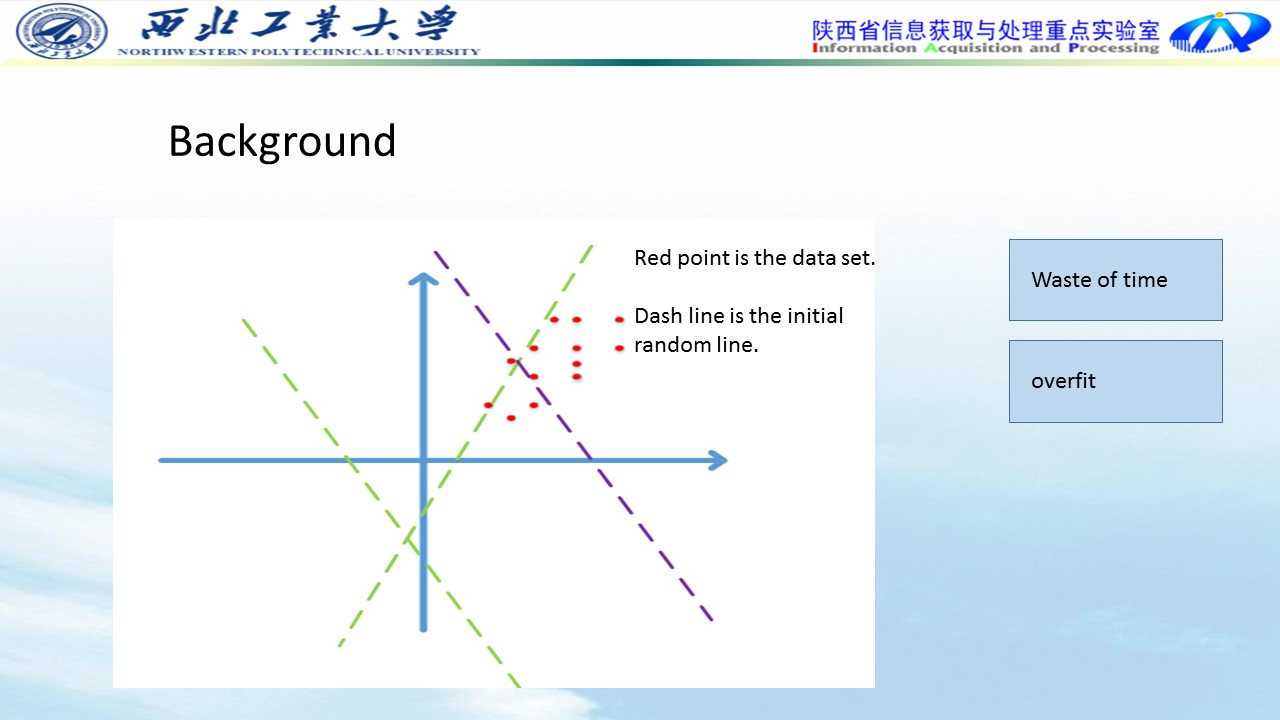
图中红点代表2维的初始数据点,数据落在第一象限内,数据具有一定的相关性,比如第一个灰度值为30,比较黑,那它旁边的一个像素值一般不会超过100,否则给人的感觉就像噪声一样。形成类似上图所示的狭长分布。
而神经网络模型在初始化的时候,权重W是随机采样生成的,随机的Wx+b=0表现为上图中的随机虚线,注意到,两条绿色虚线实际上并没有什么意义,在使用梯度下降时,可能需要很多次迭代才会使这些虚线对数据点进行有效的分割,就像紫色虚线那样,这势必会带来求解速率变慢的问题。如果维数过多,则速率下降更明显。如果不对数据进行预处理,这将带来了极大运算资源的浪费,而且大量的数据外分割面在迭代时很可能会在刚进入数据中时就遇到了一个局部最优,导致overfit的问题。
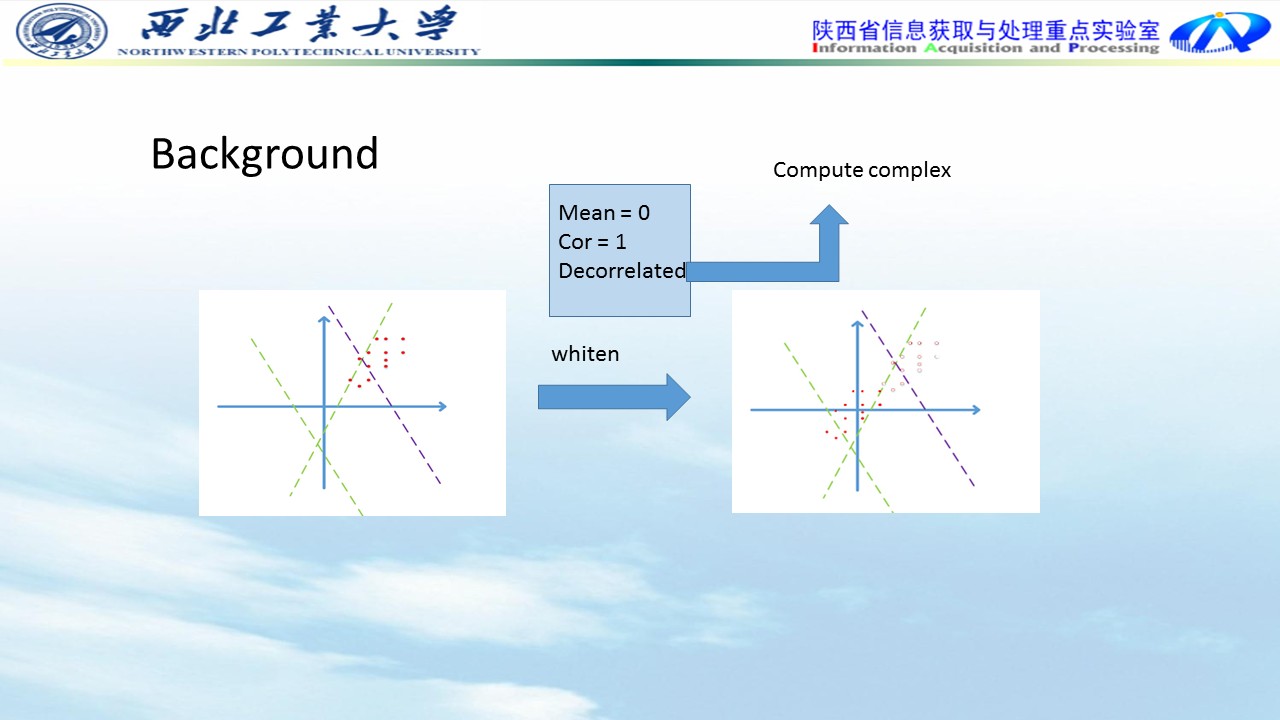
如果我们使用一些预处理的算法,例如PCA和ZCA白化,数据不再是一个狭长的分布,随机分界面有效的概率就又大大增加了。
不过计算协方差矩阵及其特征值太耗时也太耗空间,我们一般最多只进行前两步,也就是数据减去其均值,再除以标准差,这样能使数据点在每维上具有相似的宽度,可以起到一定的增大数据分布范围,进而使更多随机分界面有意义的作用。
下面说说正规化的对象。

full batch learning:
advantages: 全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。 disadvantages: 1、随着数据集的海量增长和内存限制,一次性载入所有的数据进来变得越来越不可行2、数据量大,收敛比较慢。
online learning:
使用在线学习,每次修正方向以各自样本的梯度方向修正,各自走自己的,收敛速度慢,甚至有可能不收敛。
batch learning: 内存利用率提高,跑完一个epoch(全数据集)的迭代次数减少,提高处理速度,收敛的方向准。
如何选取batch不是本文的重点,个人觉得如何选取好的batch应该做实验得到。

假设有两层神经网络,第一层的输出是第二层的输入,用x表示。公式中:k表示的是输入的第k维。X(k)表示一个batch中的所有第K维数据,注意x(k)是一个向量。假设现在batch的大小是7,每个输入有4维特征。则X(1) ={ X1(1), x2(1), x3(1), x4(1), x5(1), x6(1), x7(1)}构成的集合。x带帽k就表示输入的第k维减去输入第k维的均值,再除以第k维的标准差。这就是基本思想。
但是本文在此基础上,又做这一步。具体为什么也说不清楚。但是有一个解释,如果我们令gamma等于之前求得的标准差,即gammak等于根号下var xk,beta等于之前求得的均值,即betak= e(xk),则这个变换就又将数据还原回去了。在他们的模型中,这两个参数与每层的W和b一样,是需要迭代求解的。

这是他们的算法。
第2到5步,batch normalization 对每一层数据处理。
第6到7步,然后训练网络优化参数theta和gamma,beta。
后面几步是进行测试
我在读这篇文章的时候,李波师兄向我提出了两个问题,
问题一:

答案:Ex 用训练时的batch的均值。训练时每一个batch都有一个E(xk),那我们就取1/m*(Exk)的和。
问题二:
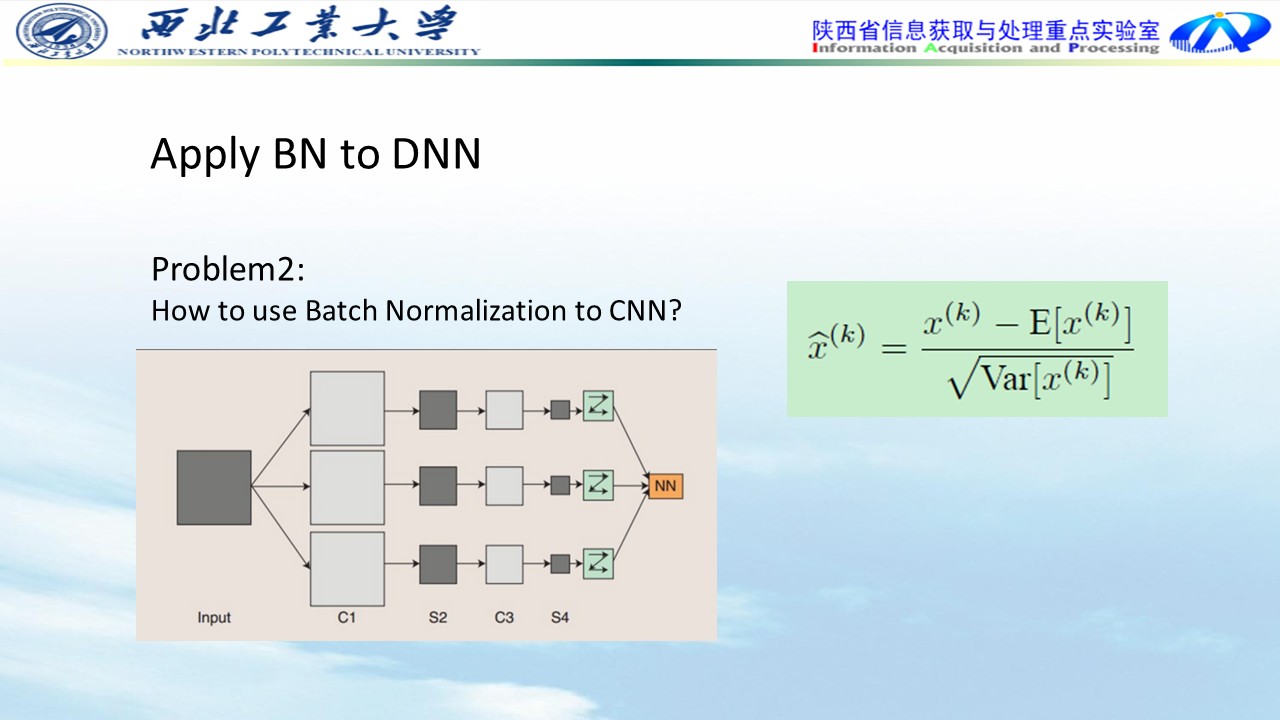
在feature maps(特征映射) 上,将其BN。假设一个batch有7个样本,feature maps是p * q的大小,则将m*p*q个数进行BN。之前取得是7个数据的均值和标准差,cnn取的就是7*p*q的数据的均值和方差。
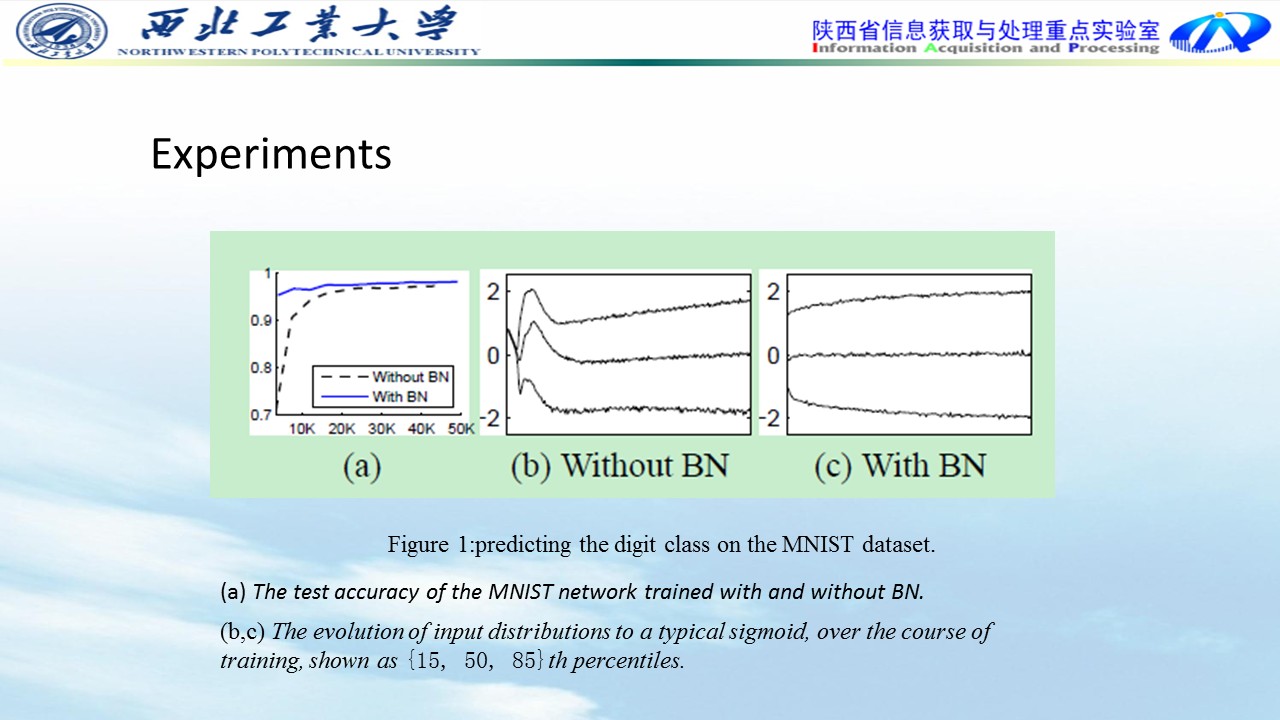
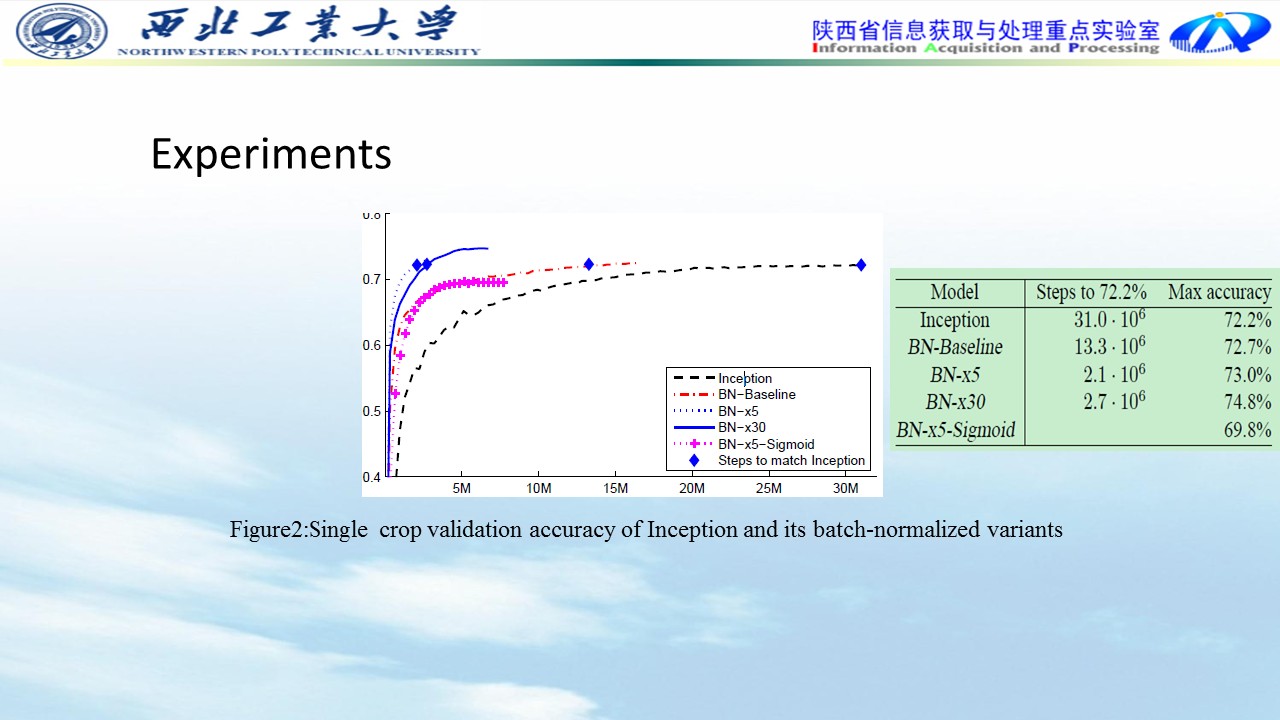
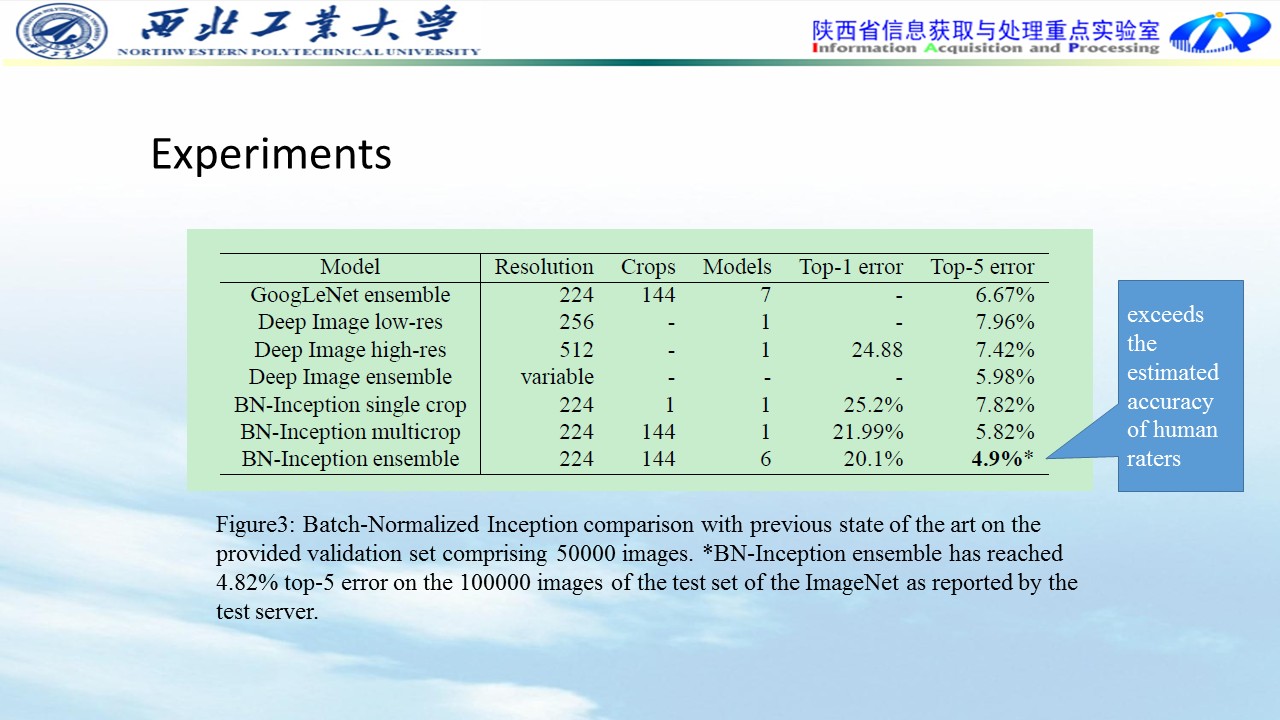
Experiments:
BN比无BN收敛速度快的多,精度稍微高一点。
无BN均值和方差波动较大,BN均值和方差较为平缓。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









