







0. SVM简介
SVM是最常用的分类器之一,其可以用来做分类,回归以及异常检测。
其模型定义和学习如下:
原始问题:
min w,b,ζ 12 w T w+C∑ n i=1 ζ i
subject to y i (w T ϕ(x i )+b)≥1−ζ i ,
ζ i ≥0,i=1,...,n
对偶问题:
min α 12 α T Qα−e T α
subject to y T α=0
0≤α i ≤C,i=1,...,n
决策函数:
sgn(∑ n i=1 y i α i K(x i ,x)+ρ)
其中
e
是全为1的向量,
svm的优点:
- 在高纬空间的有效性。
- 在特征维度高于样本维度的情况下,依然有效。
- 它的决策函数只使用训练数据的一部分,通常把这一部分数据称之为支持向量,所以它是比较节省内存的。
- 可以提供各种各样的核函数来扩展SVM的功能。
SVM的缺点:
- 如果特征的维度远大于样本的数目,那么性能将大大的降低。
- SVM不直接提供概率估计。
1. SVM用来做分类:
SVC, NuSVC,LinearSVC
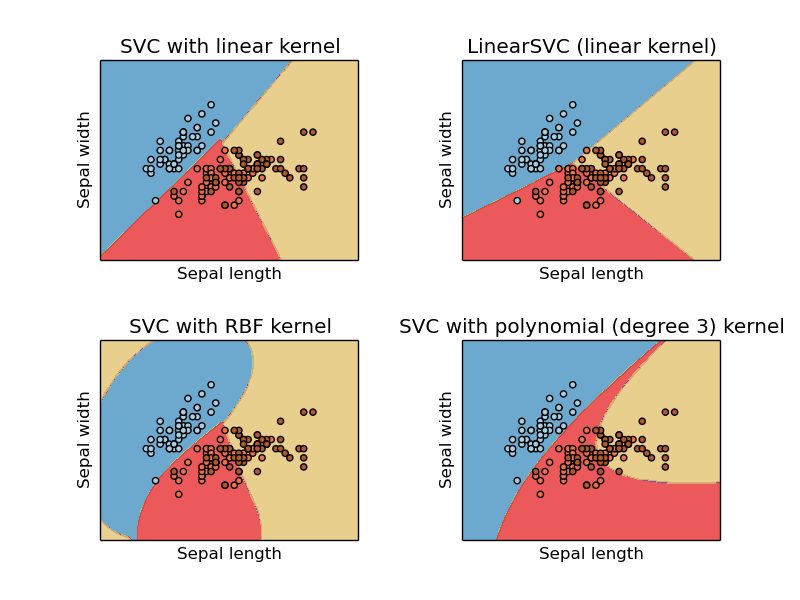
这三类都能用来做多类分类,SVC 和 NuSVC 类似,但是在一些参数上有所不同,LinearSVC 则是另外一种svm的实现,它是线性核。
输入:
SVC, NuSVC 和LinearSVC的输入训练数据:[n_samples, n_features] ,标签数据:[n_samples],标签可以是整数或者是字符串都可以。
#训练svm:
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y) `
#测试svm`
>>> clf.predict([[2., 2.]成员变量:
因为svm模型只需要用到训练数据中的一部分,也就是支持向量的部分。
support_vectors_:存放模型的支持向量。
support_ :存放模型的支持向量的索引。
n_support: 存放模型每一类的支持向量的数目。
多类分类
原始的svm只能支持二类的分类,而多类分类是通过多次二分类来实现的,具体有两种方式,即一对一和一对多两种方式。
SVC 和 NuSVC是采用一对一的方式,如果 n_class 是总的类别的数目,那么共需要训练n_class * (n_class - 1) / 2 个不同的二分类器。
#获取分类器的数目:
X = [[0], [1], [2], [3]]
Y = [0, 1, 2, 3]
clf = svm.SVC()
clf.fit(X, Y)
dec = clf.decision_function([[1]])
print dec.shape[1]不同的是, LinearSVC 是采用一对多的方式来进行多分类,具体来说,有 n_class 个类别就训练n_class 个分类器,显然,在了类别数目比较多的情况下,这样更节省空间和时间。
不平衡数据:
SVC实现了不平衡训练数据集上的处理,通过设置class_weight参数来给每个类别设置不同的权重,具体的使用还得看文档。
2. SVM用来做回归
SVM分类器可以很自然的被扩展用来做回归,被称之为支持向量回归。
SVR跟SVC一样,模型只考虑支持向量的数据,那些原理分界边际的点将被忽视。
跟SVC类似,其也有三个类来显示它,对应的是: SVR, NuSVR , LinearSVR,
>>> from sklearn import svm
>>> X = [[0, 0], [2, 2]]
>>> y = [0.5, 2.5]
>>> clf = svm.SVR()
>>> clf.fit(X, y)
SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma=0.0,
kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
>>> clf.predict([[1, 1]])
array([ 1.5])3. 密度估计,异常检测
类别:OneClassSVM 来实现异常检测,这是一种无监督的方法,它的训练数据只需要
X
,而无需
4. 复杂度分析
SVM是一个二次规划问题(QP问题),其实重训练数据集合中分离出支持向量的数据点,在基于libsvm的实现中,其复杂度介于: O(n features ×n 2 samples ) 和 O(n features ×n 3 samples ) 之间。
5. 核函数
• 线性核: ⟨x,x ′ ⟩ .
• 多项式核: (γ⟨x,x ′ ⟩+r) d . d is specified by keyword degree, r by coef0.
• rbf: exp(−γ|x−x ′ | 2 ) . γ is specified by keyword gamma, must be greater than 0.
• sigmoid (tanh(γ⟨x,x ′ ⟩+r)) , where r <script id="MathJax-Element-26" type="math/tex">r</script> is specified by coef0.
linear_svc = svm.SVC(kernel='linear')
linear_svc.kernel
'linear'
rbf_svc = svm.SVC(kernel='rbf')
rbf_svc.kernel
'rbf'参考文献:Scikit文档















 4272
4272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









