







1. 支撑向量机SVM介绍
支持向量机SVM算法可用来解决分类问题及回归问题。通过引入核函数,也能有效地解决非线性数据集的分类及回归问题,其主要思想即为支撑向量的建立。在分类问题中,通过建立两个平行支撑向量,在尽可能分开不同类别数据集的同时,保证两个支撑向量距离最远,支撑向量中间的直线即为决策边界。回归问题中,建立两个平行支撑向量,在尽可能揽括所有数据样本的同时,保证两个支撑向量距离最近,支撑向量中间的直线即为回归模型。
2 Hard Margin SVM
为了直观的展示支持向量机的分类原理,以下图一个线性可分问题为例,首先对两拨数据使用两条平行虚线分开,为了最大限度的区分开这两拨数据,要求这两条虚线距离最远,两条虚线中间的实线即为我们最终用来分隔数据的最优决策边界,两条虚线又称作支持向量,所有样本都完全被这两条平行线分开,不允许有任何容错偏差样本点,称为硬间隔(Hard Margin SVM)。注意,SVM的决策边界与线性回归的最小二乘法所得到的决策边界原理不同,故损失函数也不一样,如下公式所示,SVM的损失函数是一个有条件的最优化求解。

使用sklearn代码实现如下所示,以鸢尾花数据集为例,以下代码为模块引用及数据集准备:
from sklearn.svm import SVC, SVR
from sklearn.preprocessing import PolynomialFeatures
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVR
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
def dataInit(type='linear'):
if type == 'linear':
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X[y < 2, :2] # 只取两类二分类数据集 特征向量只取前两个
standardScaler = StandardScaler()
standardScaler.fit(X)
X, y = standardScaler.transform(X), y[y < 2] # 只取两类二分类数据集
elif type == 'polynomial':
X, y = datasets.make_moons(noise=0.15, random_state=666)
elif type == 'boston':
# boston = datasets.load_boston() # sklearn 1.2 版本之前适用,之后数据被删了,可用下列http方式获取
# ImportError:
# `load_boston` has been removed from scikit-learn since version 1.2.
data_url = "http://lib.stat.cmu.edu/datasets/boston"
boston = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([boston.values[::2, :], boston.values[1::2, :2]])
target = boston.values[1::2, 2]
X,y = data, target
return X, y调用模型LinearSVC进行SVM硬间隔分类:
# 1 线性可分 硬间隔 支持向量机
def hardLinearSVCFunction():
X, y = dataInit()[0], dataInit()[1]
svc = LinearSVC()
svc.fit(dataInit()[0], dataInit()[1])
print("线性可分 硬间隔 支持向量机 svc.score = {}".format(svc.score(X, y)))3 Soft Margin SVM
如果部分样本点类别区域中有一定的穿插,如下图所示,继续使用上诉硬间隔SVM的思想就无法进行分类。于是为了让模型具备更好的适应性,让支持向量可以有一定的容错性,允许部分点不在类别中。为了调和误差点的影响程度,在损失函数中加入超参数C,使用误差点离决策边界的距离和作为调和项,C即为其系数,损失函数如下所示。
值得注意的是,即使样本可以进行硬间隔分类,笔者也建议进行软间隔分类,因为软间隔分类除了能将分类穿插的样本忽略,还可以通过调节超参数的大小,忽略离决策边界过近的点,从而扩大模型的泛化能力。

在sklearn中,软间隔分类与硬间隔分类使用了相同的方法LinearSVC,只需要在模型方法中传入超参数C即可:
# 2 线性不可分 软间隔 支持向量机
def softLinearSVCFunction():
X, y = dataInit()[0], dataInit()[1]
svc = LinearSVC(C=1e9)
svc.fit(dataInit()[0], dataInit()[1])
print("线性不可分 软间隔 支持向量机 svc.score = {}".format(svc.score(X, y)))4 非线性SVM分类
为了解决非线性问题,在回归算法中笔者有讲到,可将非线性样本映射到更高维空间进行线性计算,即通过对输入空间向量进行多项式组合预处理,得到新的输入空间进行运算。其实现代码如下所示:
# 3 多项式 支持向量机
def polyLinearSVCFunction():
def PolynomialSVC(degree, C=1.0):
return Pipeline([
("poly", PolynomialFeatures(degree=degree)),
("std_scaler", StandardScaler()),
("linearSVC", LinearSVC(C=C))
])
X, y = dataInit(type='polynomial')[0], dataInit(type='polynomial')[1]
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(dataInit(type='polynomial')[0], dataInit(type='polynomial')[1])
print("多项式 支持向量机 poly_svc.score = {}".format(poly_svc.score(X, y)))5 核函数SVM分类
笔者并不推荐上述方式进行非线性数据集分类,这样做的弊端是通过多项式组合后,样本集将会变得特别大,给内存和计算资源带来很大的负担。SVM提供了核函数功能,可将样本集通过核函数进行映射,同样能达到非线性分类的功能。其中核函数可使用多项式、高斯等。
多项式 :
SVC(kernel="poly", degree=degree, C=C)
degree 代表多项式的阶数,阶数越高过,计算量越大,拟合越严重。
C 是正则化参数,正则化的强度与C成反比
高斯函数 :
SVC(kernel="rbf", gamma=gamma)
gamma 越大,高斯分布越窄,模型复杂度越高,容易过拟合;越小越容易欠拟合
代码实现如下:
# 4 多项式核函数 支持向量机
def polyKernelSVCFunction():
def PolynomialKernelSVC(degree, C=1.0):
return Pipeline([
("std_scaler", StandardScaler()),
("kernelSVC", SVC(kernel="poly", degree=degree, C=C))
])
X, y = dataInit(type='polynomial')[0], dataInit(type='polynomial')[1]
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(dataInit(type='polynomial')[0], dataInit(type='polynomial')[1])
print("多项式核函数 支持向量机 poly_kernel_svc.score = {}".format(poly_kernel_svc.score(X, y)))
# 5 高斯核函数 支持向量机
def RBFKernelSVCFunction():
def RBFKernelSVC(gamma):
return Pipeline([
("std_scaler", StandardScaler()),
("svc", SVC(kernel="rbf", gamma=gamma))
])
X, y = dataInit(type='polynomial')[0], dataInit(type='polynomial')[1]
svc = RBFKernelSVC(gamma=1) # gamma 越大,高斯分布越窄,模型复杂度越高,容易过拟合;越小越容易欠拟合
svc.fit(X, y)
print("高斯核函数 支持向量机 svc.score = {}".format(svc.score(X, y)))
6 线性回归问题
使用支撑向量机解决回归问题时,其原理还是使用两条平行虚线,与分类问题相反的是,此时的支撑向量需要尽可能将所有的样本点都揽括其中,支撑向量到中间实线的距离即为epsilon,其值越大,模型泛化能力越强。
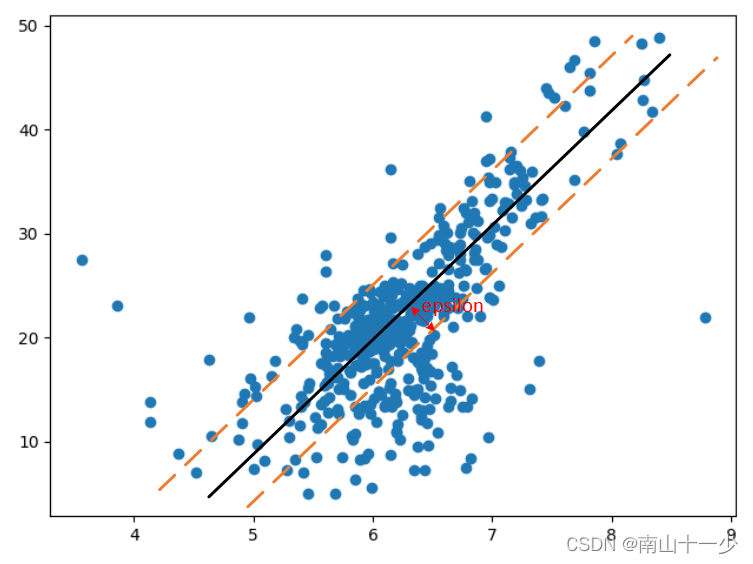
使用模型LinearSVR(epsilon=epsilon)进行线性回归,epsilon为模型margin宽度,可通过网格搜索的方法找到最佳超参数,其代码如下所示:
# 6 线性回归问题 支持向量机
def regressionLinearSVRFunction():
X, y = dataInit(type='boston')[0], dataInit(type='boston')[1]
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
def StandardLinearSVR(epsilon=0):
return Pipeline([
('std_scaler', StandardScaler()),
('linearSVR', LinearSVR(epsilon=epsilon))
])
best_score, best_epsilon = 0, 0
for i in np.arange(0, 2, 0.01):
svr = StandardLinearSVR(epsilon=i)
svr.fit(X_train, y_train)
score = svr.score(X_test, y_test)
if score > best_score:
best_score = score
best_epsilon = i
print("回归问题 支持向量机 best_score = {}, best_epsilon = {}".format(best_score, best_epsilon))7 非线性回归问题
同理,可通过加入核函数对样本映射,同样可以解决非线性的回归问题,sklearn方法中,只需传入相应的参数即可实现:
SVR(kernel="rbf", gamma=gamma)
kernel="rbf" 代表为高斯核函数,具体代码实现如下,同样也可以加入网格搜索对超参数进行最优化求解:
# 7 非回归问题 支持向量机
def regressionKernelSVRFunction():
X, y = dataInit(type='boston')[0], dataInit(type='boston')[1]
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
def StandardLinearSVR(gamma=0):
return Pipeline([
('std_scaler', StandardScaler()),
('linearSVR', SVR(kernel="rbf", gamma=gamma))
])
best_score, best_gamma = 0, 0
for i in np.arange(0, 2, 0.01):
svr = StandardLinearSVR(gamma=i)
svr.fit(X_train, y_train)
score = svr.score(X_test, y_test)
if score > best_score:
best_score = score
best_gamma = i
print("回归问题 高斯核函数支持向量机 best_score = {}, best_gamma = {}".format(best_score, best_gamma))
8 总结
本文通过对支撑向量机SVM进行原理讲解,并基于sklearn对硬间隔SVM、软间隔SVM、非线性SVM分类、核函数SVM分类,以及利用支撑向量机处理线性和非线性回归问题进行了代码示例。















 609
609











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









