







1分类型变量变换
- 类型的数值编码
当训练模型时,数据集中的字段包含符号字段(分类字段)时,而且该字段也需要被用来参与建模,并且该模型算法需要使用所有记录的数值来进行算法计算。这种情况下就对符号字段提出了挑战。
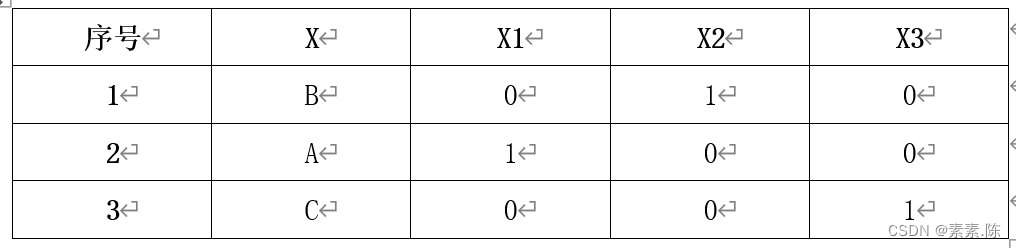
一般的做法是将该符号字段编码为一组数值字段,该组数值字段的个数等于该符号字段的分类个数,一个分类对应一个数值字段。对于该符号字段的每一个取值,对应于该值的那个数值字段的值均被设置为1,其他数值字段的值均被设置为0。这组数值字段(衍生字段)被称为indicator(指示)字段,或者dummy(虚拟)字段。例如,对于下列3条数据,X是一个符号字段,取值为A,B,C,那么他可以被转化为衍生字段X1,X2,X3。
- 联合字段合并
稀疏矩阵是数据分析时一种常见的数据形式。稀疏矩阵是指一个矩阵中,非零元素的值占很小一部分,绝大多数元素取值为零,并且非零元素的分布一般没有什么规律。笔者在做项目过程中遇到一个实际的项目时,遇到一个稀疏矩阵的问题,二维表中每一列代表客户持有的产品状态,1代表持有,0代表未持有。要找出客户持有产品的规律,就是将稀疏矩阵中每行的取值转化为一个字符串,即字符串“0000000000”代表十列数据取值都为0的情况。通过这种方式,其实就是用新的一列代表了原来10列数据信息。
df = pd.get_dummies(df , columns=col_name)
2数据归约
数据归约(DataReduction)是指在理解数据分析任务和数据本身内容的基础上,寻找依赖于发现目标的数据的有用特征,以缩减数据规模,从而在尽可能保持数据原貌的前提下,最大限度地精简数据量。数据归约主要通过属性选择 和数据采样途径来实现。
数据集中的变量并不都是重要的,其存在不会提高数据挖掘模型的效率,甚至会增加模型的复杂度,进而降低模型的效率与稳定性,我们把这类变量称之为无效变量。因此在模型中应当尽量包含对目标变量影响大的关键变量,去除无效变量,保证模型准确性与稳定性。根据无效变量与目标变量之间关系的不同,可以将其分为不相关变量和多余变量两种类型。不相关变量指的是与目标变量之间相互独立,不存在相关性的变量。多余变量指的是与目标变量之间存在相关性,但是与数据集中的另一变量相重合或者对目标字段的影响是通过影响数据集中的另一变量而实现的。
2.1属性选择指的是从大量的属性中筛选出与目标值(针对有监督的模型)或业务目标(无监督的模型)相关的属性,并将大量的不相关的属性摒弃。属性选择方法主要有:
- 信息增益:信息增益最大,说明属性越重要。
- 信息增益率:信息增益法对可取值较多的类别划分属性有所偏好,可能影响模型的泛化能力。
- 基尼指数:概率越低,说明纯度越高。
- IV值:变量的IV值越大,说明该指标越重要。
2.2数据采样
数据采样指的是从总体中确定抽样范围并进行抽样,通过对样本的研究来估计或反映总体的特征。 - 概率抽样:适用的场景是采用样本数据来体现整体的特征,包括以下几种
- 简单随机抽样:假设数据集合中的数据记录数量为N,则每一笔被选择的机率为1/N。随机抽样包括取回式随机抽样和不取回式随机抽样。在取回式随机抽样中,每一笔被挑选的数据记录,仍可以重复再被挑选;而在不取回式随机抽样中,每一数据记录仅能被挑选一次,不可重复被挑选。
- 系统随机抽样:将总体中的各单元先按照一定顺序排列并编号,然后按照不一定的规则抽样,其中最常采用的是等距离抽样,根据整体单位数和样本单位计算出抽样距离(相同的间隔),然后按相同的距离或间隔抽选样本单位。
优点:操作简便,且与简单随机抽样相比,在一定条件下更能体现总体的特征。 - 分层随机抽样:把调查总体分为同质的、互不交叉的层(或类型),然后在各层(或类型)中独立抽取样本。从另外一个角度来说,分层抽样就是在抽样之前引入一些维度,对总量的群体进行分层或分类,在此基础上再进行抽样。
- 整群抽样(ClusterSampling):先将调查总体分为群,然后从中抽取群,对被抽中的群的全部单位进行调查。
- 非概率抽样:都是按照抽样者的意愿来进行的,典型的方式如下:
- 方便抽样:根据调查者方便选取的样本,以无目标、随意的方式进行。例如,街头拦截访问(看到谁就访问谁)
- 判断抽样:由专家判断而有目的地抽取他认为“有代表性的样本”。例如,社会学家研究某国家的一般家庭情况时,常以专家判断方法挑选“中型城镇”进行;在探索性研究中可以使用这种方法。
- 配额抽样:先将总体元素按某些控制的指标或特征分类,然后按方便抽样或判断抽样选取样本元素。
3衍生指标的加工
所谓衍生指标是指利用给定数据集中的字段,通过一些计算而加工产生一些新的指标,衍生指标将人们的见解融入建模过程,使得模型的结论充分体现业务,市场的重要特征,精心挑选的衍生指标能增强模型的可理解性和解释能力。衍生指标加工的方法有: - 将数值转化为百分位数:数值体现被描述对象的某个维度的指标大小,百分比则体现程度。
- 将类别变量替换为数值:把类别变量转化为dummy虚拟变量,从实际业务指导的角度来看,分类变量的易用性远远大于数值型变量。从模型算法的角度来看,采用数值型值型的指标会显著提高模型的性能。
- 多变量组合:多变量组合计算出一个新的指标,是非常常用的衍生指标。
- 从时间序列中提取特征:时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。例如:电价执行异常模型中最大用电量发生的季度指标就是从时间序列中提取出来的。















 2403
2403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









