






Meta在周四(4月18日)发布了其最新大型语言模型 LLaMA 3。该模型将被集成到其虚拟助手Meta AI中。Meta自称8B和70B的LLaMA 3是当今 8B 和 70B 参数规模的最佳模型,并在推理、代码生成和指令跟踪方面有了很大进步。(点赞是我们分享的动力)
--------------------------------------------------
主编作者陈巍 博士,高级职称,曾担任华为系相关自然语言处理( NLP )企业的首席科学家,大模型算法-芯片协同设计专家,国际计算机学会(ACM)会员、中国计算机学会(CCF)专业会员。主要研究领域包括大模型(Finetune、Agent、RAG)、存算一体、GPGPU。
1 LLaMA 3 简介
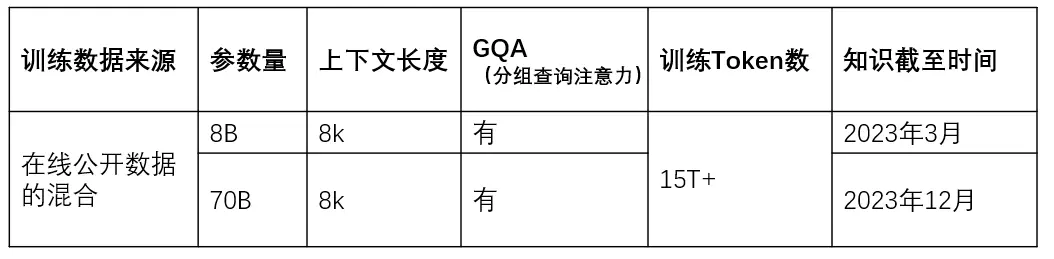
目前发布的是早期版本,包括 8B 和 70B 大小两个不同版本。目前发布的LLaMA 3仅支持文本输入和输出,今年晚些会发布405B(也称400B)和多模态版本。
Llama 3 8B 在 MMLU、ARC、DROP 和 HumanEval 等 9 个基准测试中,优于具有相似参数数量的其他开源模型,例如 Mistral 的 Mistral 7B 和 Google 的 Gemma 7B。 Llama 3 70B 超越了 Claude 3 Sonnet,并可与 Google 的 Gemini 1.5 Pro 匹敌。
LLaMA 3仍然基于Transformer架构,使用了有监督微调(SFT)和人类反馈的强化学习(RLHF)。
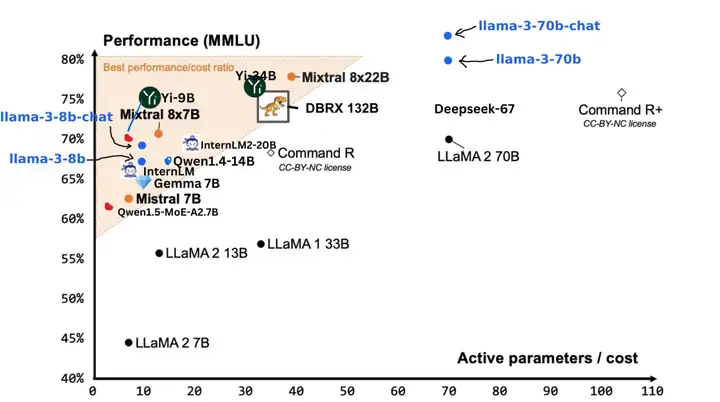
LLaMA 3 与其他模型的精度和运行成本对比(来源:@tianle_cai)
目前LLaMA 3 可以理解中文问题的意思,但跟原生LLaMA 2类似,输出内容一般还是英文。在提示词(Prompt)中要求用中文时,会使用中文或中英文结合作答,在中文方面的表现还有很大提升空间。
2 LLaMA 3模型架构
2.1 还是典型的Decoder-only的 Transformer
Llama 3 仍旧使用Decoder-only的 Transformer 架构。

LLaMA-2 使用普通Transformer的预归一化变体
LLaMA2/3 模型没有使用绝对或相对位置嵌入,而是采用 RoPE方案。这种位置嵌入方法用旋转矩阵对绝对位置进行编码,并将相对位置信息直接添加到自注意力操作中。 RoPE 这类嵌入方法在长文本任务具有天然的外推优势。
与LLaMA 2 相比:
1)LLaMA 3具有 128K词汇量大小的Tokenizer,可以更有效的对文本进行编码,从而显着提高模型性能。
2)8B 和 70B 的LLaMA3都采用了分组查询注意力 (GQA)机制,以提高Inference速度。(LLaMA 2 70B也采用了GQA)
3)在8,192 个Token的较长序列上训练模型,使用掩码机制确保自注意力不会跨越文档边界。需要注意的是LLaMA 3采用了8K Token进行训练,并不代表只能生成8K Token以内文本。(LLaMA 2 为4096)
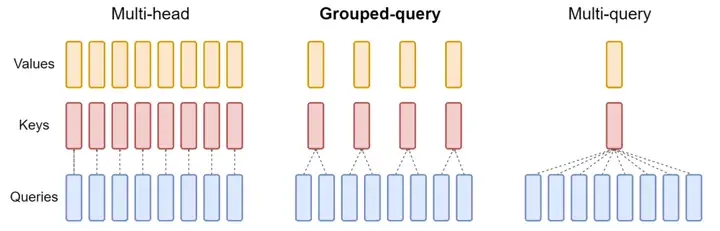
分组查询注意力与其他计算模式对比
2.2 长文本支持RoPE
LLaMA 3 中依然采用了原始的RoPE(旋转嵌入)作为位置嵌入编码方案,没有使用诸如Position Interpolation,Dynamic NTK之类的技术。当然这也给国内魔改中文LLaMA 3提供了更大的空间。RoPE的主要优势包括:
- 可以扩展到任意序列长度。
- 随着相对距离的增加,Token间的依赖性减弱。
- 为线性自注意力配备相对位置编码的能力。
旋转位置嵌入(RoPE)使用旋转矩阵对绝对位置进行编码,同时在自注意力公式中结合了明确的相对位置依赖性。旋转位置嵌入保持了序列长度的灵活性、随相对距离的增加而衰减的token间依赖性,以及为线性自注意力配备的相对位置编码的能力。
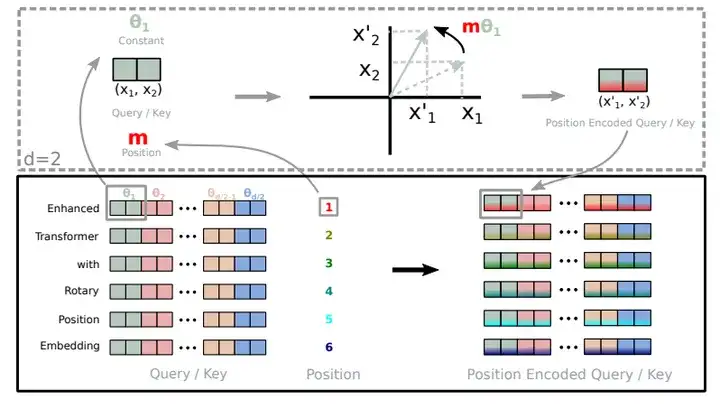
旋转位置嵌入(RoPE)示意图
3 LLaMA 3模型训练
3.1 训练的算力
LLaMA 3在H100-80GB 的GPGPU上训练(TDP 为 700W),8B和70B的模型训练累计使用了 770 万个 GPGPU 时长。
训练过程使用了3种并行加速:数据并行、模型并行和管道并行。
在 16000个 GPU 上进行训练时,可实现每个 GPU 超过 400 TFLOPS 的计算利用率。(需要注意H100的稠密算力约为2000TFLOPS)
Meta还开发了一种先进的训练堆栈,可以自动执行错误检测、处理和维护。改进了硬件可靠性和静默数据损坏检测机制,并开发了新的可扩展存储系统,以减少检查点和训练回滚的开销。
以上这些改进使总体有效培训时间超过 95%,训练效率比 Llama 2 提高了约3倍。
3.2 训练数据集
LLaMA 3 使用来自公开来源的超过 15 万亿个Token的数据进行预训练。微调数据包括公开可用的指令数据集,以及超过 1000 万个人工注释的示例。简而言之就是 More Data = Better Model。
8B 模型的预训练数据截止日期为 2023 年 3 月,70B 模型的预训练数据截止日期为 2023 年 12 月。

训练数据集比 LLaMA 2 使用的数据集大7倍,并且包含4倍多的代码。超过 5% 的 LLaMA3 预训练数据集由30 多种语言的高质量非英语数据组成。
Meta使用一系列数据清洗方法,包括使用启发式过滤器、NSFW 过滤器、语义重复数据删除方法和文本分类器来预测数据质量。其中LLaMA 2 为LLaMA 3 提供文本质量分类器的训练数据。
3.3 缩放定律
缩放定律能够在实际模型训练完成之前预测在关键任务上的性能。
8B 参数的 Chinchilla 最佳训练计算量对应于约 200B 个标记,但在模型进行额外的两个数量级以上的数据训练后(15T Token)8B 和 70B 参数模型都继续以对数线性方式改进精度。
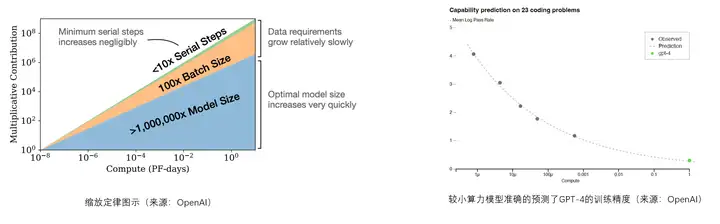
缩放定律
3.4 微调方法
Meta在预训练后使用了有监督微调(SFT)、拒绝采样、近端策略优化(PPO)和直接策略优化(DPO)的组合微调算法。 SFT 中使用的提示(Prompt)质量、PPO 和 DPO 中使用的偏好排名对对齐(Align)模型的性能有巨大影响。
在训练后,模型知道如何生成不同的答案,但模型一般不知道如何选择出正确的答案。对偏好排名的训练使模型能够学习如何选出正确答案,提升在推理和编码任务上的性能。
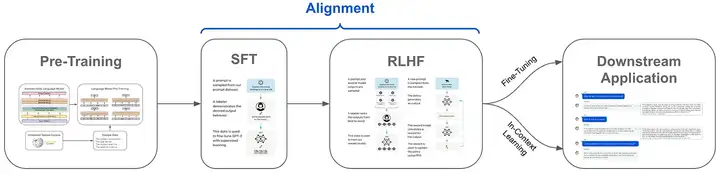
使用有监督微调(SFT)、近端策略优化(PPO)和直接策略优化(DPO)的组合微调
4 安全
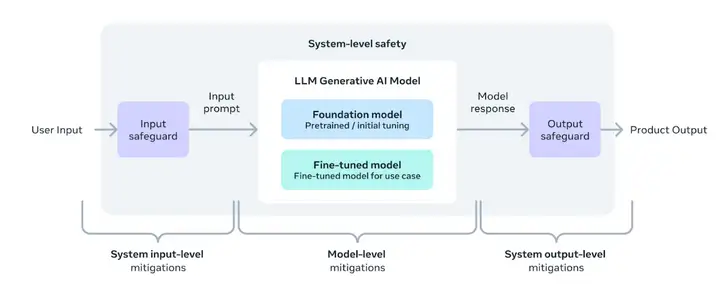
LLaMA 3的安全机制
LLaMA 3指令微调已经通过红队测试。
与 LLaMA 3 同时发布的是的安全工具Llama Guard 2,经过优化以支持新发布的MLCommons AI 安全基准。该模型改进了对自定义策略的零样本和少样本适应性。
Cybersec Eval 2 是一个更新的基准,用于量化 LLM 安全风险和能力。CyberSecEval 2添加了对 LLM 允许滥用其代码解释器的倾向、攻击性网络安全功能以及对提示注入攻击的敏感性的测量。
LLaMA 3还引入了 Code Shield对 LLM 生成的不安全代码的可在推理时过滤,以缓解不安全代码建议、代码解释器滥用和安全命令执行方面的风险。

















 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









