









用KMH(k-means hashing)学习二值编码论文 理解
本篇论文[1]是微软研究院的何凯明等人提出,何凯明在微软2015年一年参与发表5篇CVPR,还有好多其他高质量论文,这篇论文是其2013年CVPR上发表的一篇。下面进入正题。
一、问题提出
ANN检索方法中,向量量化和乘积量化方法是基于查找表的,查找表是放在内存中的。基于hamming距离的方法检索速度快,1.5ms内可以扫描完1百万64bit的hamming码,但是检索结果又没有基于查找表的好。如何才能兼容并蓄、博采众长呢?何凯明等人想到了一种结合上述两类方法优点的做法,思想很直白,且其要优化的目标函数式形式非常简单。
二、思想和原理
1.思想:
将乘积量化过程作为构建索引的第一步,用样本量化后的类中心距离代表样本之间的距离;将hamming hash表的编码过程作为第二步,用hamming码来表示前一步样本量化后的类中心;中间用个最优化函数联系起来,保证目标函数的误差达到最小。最后采用hamming码来表示类中心。用数学式表达目标函数就是:
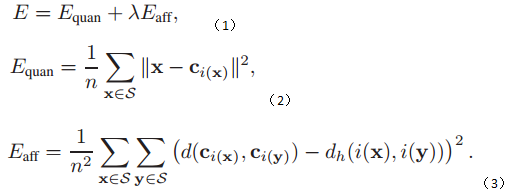
优化目标式(1)就是要优化(2)式和(3)式,优化(2)式采用k-means方法,优化(3)采用ITQ方法学习一个正交变换,使得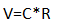
2.原理推导
主要推导下如何优化目标式(3)。
当
λ→∞
时,优化(1)等价于使(3)为0,即
d(Ci(x),Ci(y))和dh(i(x),i(y))
是完全相同的,
dh(⋅,⋅)
是hamming 空间中超立方体的两个顶点之间的距离,超立方体的一个简单例子如下:
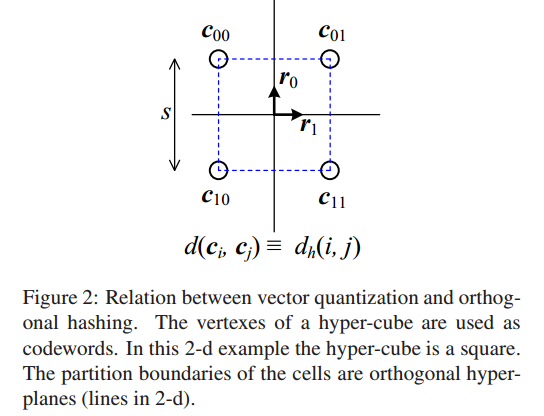
超立方体中两点之间的距离不是把两点用直线连起来,而是像蚂蚁从一个顶点爬到另一个顶点要走的最短距离。这时,论文作者说在误差为零时,任何一个类中心映射到hamming空间中后必定是要在超立方体的一个顶点上。至于这种映射关系是有多少种?假如hamming码长为b,那么超立方体的定点数就是
2b
个,那么一一映射的话,就共有
(2b)!
个。非一一映射的情况是采用较长的码来编码较少数目的类中心,这有助于区别类中心之间的距离,相似类中心之间距离应该尽可能小,差别很大的类中心之间的距离应该足够大,这正是论文中对hashing技术的理解。
在这种
λ→∞
情况下,必定存在一个解使(3)式达到最小值,大胆推广到其他情况下,那么用数学公式来表示这种一一映射关系就是:
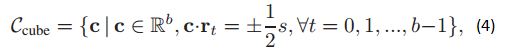
写成矩阵形式就是
V=CR
,要求
R
是正交矩阵,因为正交矩阵有一系列好的性质,它可以保持向量模长不变,可以保持各个编码的bit位相互独立(在实现ITQ时先进行PCA投影使得各个维度不相关了),旋转矩阵就是正交矩阵的一种特例。由于可以保持向量模长不变,那么KMH方法就具有了Affinity-Preserving特性。
公式(4)中的
求一个正交变换R,使得
总之,k-means hashing方法在样本
x,y
之间距离
d(x,y)
和hamming码
i和j
之间的距离
dh(i,j)
建立联系,中间是两个近似过程和一个定义过程。数学表达如下:
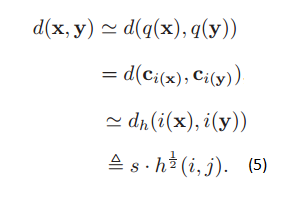
hamming码i和j之间的距离就i xor j,再统计其中bit为1的个数。
三、推广到乘积空间
由于hamming编码的码书计算和存放需要空间,而且b个bit的hamming码最多只能表示
2b
个码字,于是采用论文[3]中的做法,将k-means hashing的方法推广到乘积量化空间。
证明主要过程如下:

跟(5)式相同。
四、最优化函数的求导

参考文献:
[1]He K, Wen F, Sun J. K-means hashing: An affinity-preserving quantization method for learning binary compact codes[C]//Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on. IEEE, 2013: 2938-2945.
[2]Schönemann P H. A generalized solution of the orthogonal Procrustes problem[J]. Psychometrika, 1966, 31(1): 1-10.
[3]Jegou H, Douze M, Schmid C. Product quantization for nearest neighbor search[J]. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 2011, 33(1): 117-128.















 3208
3208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









