






数据完全存于内存的数据集类
本章节主要学习构造InMemory数据集类的方式,这是一种完全存储于内存的数据集类。
学习安排:
- 学习PyG规定的使用数据集的一般过程;
- 学习InMemoryDataset基类;
- 学习一个简化的InMemory数据集类;
- 学习一个InMemory数据集类实例,以及使用该数据集类时会发生的一些过程。
一、使用数据集的一般过程
PyG定义了使用数据的一般过程:
- 从网络上下载数据原始文件;
- 对数据原始文件做处理,为每一个图样本生成一个Data对象;
- 对每一个Data对象执行数据处理,使其转换成新的Data对象;
- 过滤Data对象;
- 保存Data对象到文件;
- 获取Data对象,在每一次获取Data对象时,都先对Data对象做数据变换(于是获取到的是数据变换后的Data对象)。
实际中可能无需严格执行每一个步骤,有些步骤在特定条件下可以被跳过。
二、InMemoryDataset基类简介
在PyG中,我们通过继承InMemoryDataset类来自定义一个数据可全部存储到内存的数据集类。
class InMemoryDataset(root: Optional[str] = None, transform: Optional[Callable] = None, pre_transform: Optional[Callable] = None, pre_filter: Optional[Callable] = None)
-
root:字符串类型,存储数据集的文件夹的路径。该文件夹下有两个文件夹:
- 一个文件夹为记录在raw_dir,它用于存储未处理的文件,从网络上下载的数据集原始文件会被存放到这里;
- 另一个文件夹记录在processed_dir,处理后的数据被保存到这里,以后从此文件夹下加载文件即可获得Data对象。
- 注:raw_dir和processed_dir是属性方法,我们可以自定义要使用的文件夹。
-
transform:函数类型,一个数据转换函数,它接收一个Data对象并返回一个转换后的Data对象。此函数在每一次数据获取过程中都会被执行。获取数据的函数首先使用此函数对Data对象做转换,然后才返回数据。此函数应该用于数据增广(Data Augmentation)。该参数默认值为None,表示不对数据做转换。
-
pre_transform:函数类型,一个数据转换函数,它接收一个Data对象并返回一个转换后的Data对象。此函数在Data对象被保存到文件前调用。因此它应该用于只执行一次的数据预处理。该参数默认值为None,表示不做数据预处理。
-
pre_filter:函数类型,一个检查数据是否要保留的函数,它接收一个Data对象,返回此Data对象是否应该被包含在最终的数据集中。此函数也在Data对象被保存到文件前调用。该参数默认值为None,表示不做数据检查,保留所有的数据。
通过继承InMemoryDataset类来构造一个我们自己的数据集类,我们需要实现四个基本方法:
- raw_file_names():这是一个属性方法,返回一个数据集原始文件的文件名列表,数据集原始文件应该能在raw_dir文件夹中找到,否则调用process()函数下载文件到raw_dir文件夹。
- processed_file_names()。这是一个属性方法,返回一个存储处理过的数据的文件的文件名列表,存储处理过的数据的文件应该能在processed_dir文件夹中找到,否则调用process()函数对样本做处理,然后保存处理过的数据到processed_dir文件夹下的文件里。
- download(): 下载数据集原始文件到raw_dir文件夹。
- process(): 处理数据,保存处理好的数据到processed_dir文件夹下的文件。
三、一个简化的InMemory数据集类
import torch
from torch_geometric.data import InMemoryDataset, download_url
class MyOwnDataSet(InMemoryDataset):
def __init__(self, root, transform=None, pre_transform=None, pre_filter=None):
super().__init__()
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_file_names(self):
return ['some_file_1', 'some_file_2', ...]
@property
def processed_file_names(self):
return ['data.pt']
def download(self):
# Download to `self.raw_dir`.
download_url(url, self.raw_dir)
...
def process(self):
# Read data into huge `Data` list.
data_list = [...]
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
- 在raw_file_names属性方法里,写上数据集原始文件有哪些,在此例子中有some_file_1, some_file_2等。
- 在processed_file_names属性方法里,写上处理过的数据要保存在哪些文件里,在此例子中只有data.pt。
- 在download方法里,我们实现下载数据到self.raw_dir文件夹的逻辑。
- 在process方法里,我们实现数据处理的逻辑:
- 首先,我们从数据集原始文件中读取样本并生成Data对象,所有样本的Data对象保存在列表data_list中。
- 其次,如果要对数据做过滤的话,我们执行数据过滤的过程。
- 接着,如果要对数据做处理的话,我们执行数据处理的过程。
- 最后,我们保存处理好的数据到文件。但由于python保存一个巨大的列表是相当慢的,我们需要先将所有Data对象合并成一个巨大的Data对象再保存。collate()函数接收一个列表的Data对象,返回合并后的Data对象以及用于从合并后的Data对象重构各个原始Data对象的切片字典slices。最后我们将这个巨大的Data对象和切片字典slices保存到文件。
四、InMemoryDataset数据集类实例
我们以公开数据集PubMed为例子,进行InMemoryDataset数据集实例分析。PubMed 数据集存储的是文章引用网络,文章对应图的结点,如果两篇文章存在引用关系(无论引用与被引),则这两篇文章对应的结点之间存在边。PyG中的Planetoid数据集类包含了数据集PubMed的使用,因此我们直接基于Planetoid类进行修改,得到PlanetoidPubMed数据集类。
PlanetoidPubMed数据集类的构造
import os.path as osp
import torch
from torch_geometric.data import InMemoryDataset, download_url
from torch_geometric.io import read_planetoid_data
class PlanetoidPubMed(InMemoryDataset):
url = 'https://gitee.com/RongqinChen/planetoid/raw/master/data'
def __init__(self, root, transform=None, pre_transform=None):
super().__init(root, transform, pre_transform)
self.data, self.slices = torch.load(self.processed_paths[0])
@property
def raw_dir(self):
return osp(self.root, 'raw')
@property
def processed_dir(self):
return osp(self.root, 'processed')
@property
def raw_file_names(self):
names = ['x', 'tx', 'allx', 'y', 'ty', 'ally', 'graph', 'test.index']
return [f'ind.pubmed.{name}' for name in names]
@property
def processed_file_names(self):
return 'data.pt'
def download(self):
for name in self.raw_file_names:
download_url('{}/{}'.format(self.url, name), self.raw_dir)
def process(self):
data = read_planeoid_data(self.raw_dir, 'pubmed')
data = data if self.pre_transform is None else self.pre_transform(data)
torch.save(self.collate([data]), self.processed_paths[0])
def __repr__(self):
return 'pubmed()'
可参考 https://pytorch-geometric.readthedocs.io/en/latest/_modules/torch_geometric/datasets/planetoid.html#Planetoid
以及之前下载的cora数据集的存储结构。
该数据集类的使用
在我们生成一个PlanetoidPubMed类的对象时,程序运行流程如下:
- 首先,检查数据原始文件是否已下载:
- 检查self.raw_dir目录下是否存在raw_file_names()属性方法返回的每个文件
- 如有文件不存在,则调用download()方法执行原始文件下载
- self.raw_dir为osp.join(self.root, ‘raw’)
- 其次,检查数据是否经过处理:
- 首先,检查之前对数据做变换的方法:检查self.processed_dir目录下是否存在pre_transform.pt文件:
- 如果存在,意味着之前进行过数据变换,接着需要加载该文件,以获取之前所用的数据变换的方法,并检查它与当前pre_transform参数指定的方法是否相同,如果不相同则会报出一个警告,“The pre_transform argument differs from the one used in ……”。
- self.processed_dir为osp.join(self.root, ‘processed’)。
- 其次,检查之前的样本过滤的方法:检查self.processed_dir目录下是否存在pre_filter.pt文件:
- 如果存在,则加载该文件并获取之前所用的样本过滤的方法,并检查它与当前pre_filter参数指定的方法是否相同,如果不相同则会报出一个警告,“The pre_filter argument differs from the one used in ……”。
- 接着,检查是否存在处理好的数据:检查self.processed_dir目录下是否存在self.processed_file_names属性方法返回的所有文件,如有文件不存在,则需要执行以下的操作:
- 调用process()方法,进行数据处理。
- 如果pre_transform参数不为None,则调用pre_transform()函数进行数据处理。
- 如果pre_filter参数不为None,则进行样本过滤(此例子中不需要进行样本过滤,pre_filter参数为None)。
- 保存处理好的数据到文件,文件存储在**processed_paths()**属性方法返回的文件路径。如果将数据保存到多个文件中,则返回的路径有多个。
- processed_paths()属性方法是在基类中定义的,它对self.processed_dir文件夹与processed_file_names()属性方法的返回每一个文件名做拼接,然后返回。
- 最后保存新的pre_transform.pt文件和pre_filter.pt文件,它们分别存储当前使用的数据处理方法和样本过滤方法。
- 首先,检查之前对数据做变换的方法:检查self.processed_dir目录下是否存在pre_transform.pt文件:
dataset = PlanetoidPubMed('dataset/PlanetoidPubMed')
print(len(dataset))
print(dataset.num_classes)
print(dataset[0].num_nodes)
print(dataset[0].num_edges)
print(dataset[0].num_features)

节点预测与边预测任务实践
任务:用PlanetoidPubMed数据集类,来实践节点预测与边预测任务
一、节点预测任务实践
重新定义一个GAT图神经网络,使其能够通过参数来定义GATConv的层数,以及每一层GATConv的out_channels。
torch.nn.Sequential
classNet中首先通过super函数继承torch.nn.Module模块的构造方法,再通过添加属性的方式搭建神经网络各层的结构信息,在forward方法中完善神经网络各层之间的连接信息,然后再通过定义Net类对象的方式完成对神经网络结构的构建。
构建神经网络的另一个方法,也可以说是快速构建方法,就是通过torch.nn.Sequential,直接完成对神经网络的建立。
import torch
from torch.nn import Linear, ReLU
import torch.nn.functional as F
from torch_geometric.nn import GCNConv, Sequential
class GAT(torch.nn.Module):
def __init__(self, num_features, hidden_channels_list, num_classes):
super().__init__()
torch.manual_seed(12345)
hns = [num_features] + hidden_channels_list
conv_list = []
for idx in range(len(hidden_channels_list)):
conv_list.append((GCNConv(hns[idx], hns[idx + 1]), 'x, edge_index -> x'))
conv_list.append(ReLU(inplace=True))
self.convseq = Sequential('x, edge_index', conv_list)
self.linear = Linear(hidden_channels_list[-1], num_classes)
def forward(self, x, edge_index):
x = self.convseq(x, edge_index)
x = F.dropout(x, p=0.5, training=self.training)
x = self.linear(x)
return x
我们通过hidden_channels_list参数来设置每一层GATConv的outchannel,所以hidden_channels_list长度即为GATConv的层数。通过修改hidden_channels_list,我们就可构造出不同的图神经网络。
模型的训练、测试:
可视化代码
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
def visualize(color):
z = TSNE(n_components=2).fit_transform(out.detach().cpu().numpy())
plt.figure(figsize=(10, 10))
plt.xticks([])
plt.yticks([])
plt.scatter(z[:, 0], z[:, 1], s=70, c=color, cmap="Set2")
plt.show()
未经训练的模型:
dataset = PlanetoidPubMed('dataset/PlanetoidPubMed')
data = dataset[0]
model = GAT(num_features=dataset.num_features, hidden_channels_list = [200, 100], num_classes=dataset.num_classes)
print(model)
model.eval()
out = model(data.x, data.edge_index)
visualize(color=data.y)


模型的训练和测试代码:
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
optimizer.zero_grad()
out = model(data.x, data.edge_index)
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
return loss
def test():
model.eval()
out = model(data.x, data.edge_index)
pre = out.argmax(dim=1)
test_correct = pre[data.test_mask] == data.y[data.test_mask]
test_acc = int(test_correct.sum()) / int(data.test_mask.sum())
return test_acc
for epoch in range(1, 201):
loss = train()
print(f'Epoch:{epoch}, Loss: {loss}')
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
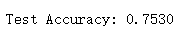
训练后的模型测试结果可视化:
model.eval()
out = model(data.x, data.edge_index)
visualize(color=data.y)

二、边预测任务实践
边预测任务,目标是预测两个节点之间是否存在边。拿到一个图数据集,我们有节点属性x,边端点edge_index。edge_index存储的便是正样本。为了构建边预测任务,我们需要生成一些负样本,即采样一些不存在边的节点对作为负样本边,正负样本数量应平衡。此外要将样本分为训练集、验证集和测试集三个集合。
PyG中为我们提供了现成的采样负样本边的方法,train_test_split_edges(data, val_ratio=0.05, test_ratio=0.1):
- 第一个参数为torch_geometric.data.Data对象,
- 第二参数为验证集所占比例,
- 第三个参数为测试集所占比例。
该函数将自动地采样得到负样本,并将正负样本分成训练集、验证集和测试集三个集合。它用train_pos_edge_index、train_neg_adj_mask、val_pos_edge_index、val_neg_edge_index、test_pos_edge_index和test_neg_edge_index,六个属性取代edge_index属性。
train_neg_adj_mask与其他属性格式不同,其实该属性在后面并没有派上用场,后面我们仍然需要进行一次训练集负样本采样。
下面我们使用Cora数据集作为例子,进行边预测任务说明。
取数据集并进行分析
import os.path as osp
from torch_geometric.utils import negative_sampling
from torch_geometric.datasets import Planetoid
import torch_geometric.transforms as T
from torch_geometric.utils import train_test_split_edges
dataset = Planetoid('dataset/Planetoid', 'Cora', transform=T.NormalizeFeatures())
data = dataset[0]
data.train_mask = data.val_mask = data.test_mask = data.y = None # 这几个属性不再有用
print(data.edge_index.shape)
data = train_test_split_edges(data)
print("=============================")
for key in data.keys:
print(key, getattr(data, key).shape) # getattr() 函数从指定的对象返回指定属性的值。

正样本边数量之和:
263 + 527 + 8976 = 9766 ! 10556
这是因为,现在所用的Cora图是无向图,在统计原始边数量时,每一条边的正向与反向各统计了一次,训练集也包含边的正向与反向,但验证集与测试集都只包含了边的一个方向。
263 + 527 + 8976/2 = 5287 = 10556/2
**为什么训练集要包含边的正向与反向,而验证集与测试集都只包含了边的一个方向? **
训练集用于训练,训练时一条边的两个端点要互传信息,只考虑一个方向的话,只能由一个端点传信息给另一个端点,而验证集与测试集的边用于衡量检验边预测的准确性,只需考虑一个方向的边即可。
torch.sum()对输入的tensor数据的某一维度求和,一共两种用法
1.torch.sum(input, dtype=None)
2.torch.sum(input, list: dim, bool: keepdim=False, dtype=None) →
Tensorinput:输入一个tensor
dim:要求和的维度,可以是一个列表
keepdim:求和之后这个dim的元素个数为1,所以要被去掉,如果要保留这个维度,则应当keepdim=True

边预测图神经网络的构造
import torch
from torch_geometric.nn import GCNConv
class Net(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, 128)
self.conv2 = GCNConv(128, out_channels)
def encode(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
return self.conv2(x, edge_index)
def decode(self, z, pos_edge_index, neg_edge_index):
edge_index = torch.cat([pos_edge_index, neg_edge_index], dim=1) # cat: 在给定维度上对输入的张量序列seq 进行连接操作。
# https://blog.csdn.net/weixin_45281949/article/details/103282148
return (z[edge_indx[0]] ** z[edge_index[1]]).sum(dim=-1)
def decode_all(self, z):
prob_adj = z @ z.t()
return (prob_adj > 0).nonzero(as_tuple=False).t()
用于做边预测的神经网络主要由两部分组成:其一是编码(encode),它与我们前面介绍的节点表征生成是一样的;其二是解码(decode),它根据边两端节点的表征生成边为真的几率(odds)。decode_all(self, z)用于推理(inference)阶段,我们要对所有的节点对预测存在边的几率。
边预测图神经网络的训练
定义单个epoch的训练过程
def get_link_labels(pos_edge_index, neg_edge_index):
num_links = pos_edge_index.size(1) + neg_edge_inede.size(1)
link_labels = torch.zeros(num_links, dtype=torch.float)
link_labels[:pos_edge_index.size(1)] = 1.
return link_labels
def train(data, model, optimizer):
model.train()
neg_edge_index = negative_sampling(edge_index=data.train_pos_edge_index, num_nodes=data.num_nodes, num_neg_samples=data.train_pos_edge_index.size(1))
optimizer.zero_grad()
z = model.encode(data.x, data.train_pos_edge_index)
link_logits = model.decode(z, data.train_pos_edge_index, neg_edge_index)
link_labels = get_link_labels(data.train_pos_edge_index, neg_edge_index).to(data.x.device)
loss = F.binary_cross_entropy_with_logits(link_logits, link_labels)
loss.backward()
optimizer.step()
return loss
通常,存在边的节点对的数量往往少于不存在边的节点对的数量。我们在每一个epoch的训练过程中,都进行一次训练集负样本采样。采样到的样本数量与训练集正样本相同,但不同epoch中采样到的样本是不同的。这样做,我们既能实现类别数量平衡,又能实现增加训练集负样本的多样性。在负样本采样时,我们传递了train_pos_edge_index为参数,于是negative_sampling()函数只会在训练集中不存在边的节点对中采样。get_link_labels()函数用于生成完整训练集的标签。
# 运行完整的训练、验证与测试
import os.path as osp
import torch
import torch.nn.functional as F
import torch_geometric.transforms as T
from sklearn.metrics import roc_auc_score
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConv
from torch_geometric.utils import negative_sampling, train_test_split_edges
class Net(torch.nn.Module):
def __init__(self, in_channels, out_channels):
super(Net, self).__init__()
self.conv1 = GCNConv(in_channels, 128)
self.conv2 = GCNConv(128, out_channels)
def encode(self, x, edge_index):
x = self.conv1(x, edge_index)
x = x.relu()
return self.conv2(x, edge_index)
def decode(self, z, pos_edge_index, neg_edge_index):
edge_index = torch.cat([pos_edge_index, neg_edge_index], dim=-1)
return (z[edge_index[0]] * z[edge_index[1]]).sum(dim=-1)
def decode_all(self, z):
prob_adj = z @ z.t()
return (prob_adj > 0).nonzero(as_tuple=False).t()
def get_link_labels(pos_edge_index, neg_edge_index):
num_links = pos_edge_index.size(1) + neg_edge_index.size(1)
link_labels = torch.zeros(num_links, dtype=torch.float)
link_labels[:pos_edge_index.size(1)] = 1.
return link_labels
def train(data, model, optimizer):
model.train()
neg_edge_index = negative_sampling(
edge_index=data.train_pos_edge_index,
num_nodes=data.num_nodes,
num_neg_samples=data.train_pos_edge_index.size(1))
train_neg_edge_set = set(map(tuple, neg_edge_index.T.tolist()))
val_pos_edge_set = set(map(tuple, data.val_pos_edge_index.T.tolist()))
test_pos_edge_set = set(map(tuple, data.test_pos_edge_index.T.tolist()))
if (len(train_neg_edge_set & val_pos_edge_set) > 0) or (len(train_neg_edge_set & test_pos_edge_set) > 0):
print('wrong!')
optimizer.zero_grad()
z = model.encode(data.x, data.train_pos_edge_index)
link_logits = model.decode(z, data.train_pos_edge_index, neg_edge_index)
link_labels = get_link_labels(data.train_pos_edge_index, neg_edge_index).to(data.x.device)
loss = F.binary_cross_entropy_with_logits(link_logits, link_labels)
loss.backward()
optimizer.step()
return loss
@torch.no_grad()
def test(data, model):
model.eval()
z = model.encode(data.x, data.train_pos_edge_index)
results = []
for prefix in ['val', 'test']:
pos_edge_index = data[f'{prefix}_pos_edge_index']
neg_edge_index = data[f'{prefix}_neg_edge_index']
link_logits = model.decode(z, pos_edge_index, neg_edge_index)
link_probs = link_logits.sigmoid()
link_labels = get_link_labels(pos_edge_index, neg_edge_index)
results.append(roc_auc_score(link_labels.cpu(), link_probs.cpu()))
return results
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dataset = 'Cora'
path = osp.join(osp.dirname(osp.realpath('__file__')), '..', 'data', dataset)
dataset = Planetoid(path, dataset, transform=T.NormalizeFeatures())
data = dataset[0]
ground_truth_edge_index = data.edge_index.to(device)
data.train_mask = data.val_mask = data.test_mask = data.y = None
data = train_test_split_edges(data)
data = data.to(device)
model = Net(dataset.num_features, 64).to(device)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
best_val_auc = test_auc = 0
for epoch in range(1, 101):
loss = train(data, model, optimizer)
val_auc, tmp_test_auc = test(data, model)
if val_auc > best_val_auc:
best_val_auc = val_auc
test_auc = tmp_test_auc
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Val: {val_auc:.4f}, '
f'Test: {test_auc:.4f}')
z = model.encode(data.x, data.train_pos_edge_index)
final_edge_index = model.decode_all(z)
if __name__ == "__main__":
main()
作业
1、尝试使用PyG中的不同的网络层去代替GCNConv,以及不同的层数和不同的out_channels,来实现节点分类任务。
# 尝试使用PyG中的不同的网络层去代替GCNConv,以及不同的层数和不同的out_channels,来实现节点分类任务。
from torch_geometric.nn import SAGEConv
class SAGE(torch.nn.Module):
def __init__(self, num_features, hidden_channels_list, num_classes):
super().__init__()
torch.manual_seed(12345)
hns = [num_features] + hidden_channels_list
conv_list = []
for idx in range(len(hidden_channels_list)):
conv_list.append((SAGEConv(hns[idx], hns[idx+1]), 'x, edge_index -> x'))
conv_list.append(ReLU(inplace=True),)
self.convseq = Sequential('x, edge_index', conv_list)
self.linear = Linear(hidden_channels_list[-1], num_classes)
def forward(self, x, edge_index):
x = self.convseq(x, edge_index)
x = F.dropout(x, p=0.5, training=self.training)
x = self.linear(x)
return x
def train():
model.train()
optimizer.zero_grad() # Clear gradients.
out = model(data.x, data.edge_index) # Perform a single forward pass.
# Compute the loss solely based on the training nodes.
loss = criterion(out[data.train_mask], data.y[data.train_mask])
loss.backward() # Derive gradients.
optimizer.step() # Update parameters based on gradients.
return loss
def test():
model.eval()
out = model(data.x, data.edge_index)
pred = out.argmax(dim=1) # Use the class with highest probability.
test_correct = pred[data.test_mask] == data.y[data.test_mask] # Check against ground-truth labels.
test_acc = int(test_correct.sum()) / int(data.test_mask.sum()) # Derive ratio of correct predictions.
return test_acc
model = SAGE(num_features=dataset.num_features, hidden_channels_list=[300, 200, 100], num_classes=dataset.num_classes)
print(model)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(1, 201):
loss = train()
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}')
test_acc = test()
print(f'Test Accuracy: {test_acc:.4f}')
2、在边预测任务中,尝试用torch_geometric.nn.Sequential容器构造图神经网络。
class Net(torch.nn.Module):
def __init__(self, in_channels, out_channels, hidden_channels):
super().__init__()
hns = [in_channels, hidden_channels, out_channels]
conv_list = []
for idx in range(0, 3):
conv_list.append((SAGEConv(hns[idx], hns[idx+1])), 'x, edge_index -> x')
conv_list.append(ReLU(inplace=True))
self.convseq = Sequential('x, edge_index', conv_list)
def encode(self, x, edge_index):
x = self.convseq(x, edge_index)
return x
def decode(self, z, pos_edge_index, neg_edge_index):
edge_index = torch.cat([pos_edge_index, neg_edge_index], dim=-1)
return (z[edge_index[0]] * z[edge_index[1]]).sum(dim=-1)
def decode_all(self, z):
prob_adj = z @ z.t()
return (prob_adj > 0).nonzero(as_tuple=False).t()
3、如下方代码所示,我们以data.train_pos_edge_index为实际参数来进行训练集负样本采样,但这样采样得到的负样本可能包含一些验证集的正样本与测试集的正样本,即可能将真实的正样本标记为负样本,由此会产生冲突。但我们还是这么做,这是为什么?
neg_edge_index = negative_sampling(
edge_index=data.train_pos_edge_index,
num_nodes=data.num_nodes,
num_neg_samples=data.train_pos_edge_index.size(1))
标准答案:
首先我们讨论如果使用edge_index为实际参数会怎么样?如果以edge_index为实际参数,negative_sampling()函数采样到的是真实的负样本,以真实负样本作为训练集负样本,那么训练集负样本就不会与验证集正样本有交集,也不会与测试集正样本有交集。理论上这种采样方式产生的结果会更好,实际也是如此。但我们不能采用这种训练集负样本采样方式,这是为什么?
答案在教程里的这句话,“在训练阶段,我们应该只见训练集,对验证集与测试集都是不可见的。”如果我们在训练阶段知道了所有真实负样本,我们就相当于知道了训练集与验证集的正样本,没出现在训练集正样本与所有真实负样本里的样本为训练集或验证集的正样本。采用这种数据采样方式采样得到的数据集,用于神经网络的训练,训练得到的神经网络会在“现在整个数据集”上过拟合,于是就降低了对将来未知的数据的泛化能力。于是在训练阶段,我们只能知道训练集的正样本,剩余的样本我们都是未知的。
接着我们讨论如果以data.train_pos_edge_index为实际参数来进行训练集负样本采样结果会是怎么样?以data.train_pos_edge_index为实际参数来进行训练集负样本采样,也就是在非训练集正样本中采样。非训练集正样本包含了所有的负样本,和没有出现在训练集中的正样本。虽然包含了没有出现在训练集中的正样本,但其数量相对于所有的负样本的数量要少得多。即便将真实的正样本标记为负样本会产生冲突,但这带来影响相对较小。
综上,我们要以data.train_pos_edge_index为实际参数来进行训练集负样本采样,也就是我们要在非训练集正样本中采样训练集负样本。














 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









