







目录
一、随机变量
随机变量是可以随机地取不同值的变量,不同值即随机变量不同的状态。一个随机变量只是对可能的状态的描述,它必须伴随着一个概率分布来指定每个状态的可能性。
随机变量可以是离散的或者连续的。
离散型随机变量拥有有限或可数无限多的状态,这些状态也不一定都是数值型的。
连续性随机变量的状态一定是数值型的,且有无限多状态。
二、概率分布
概率分布用来描述随机变量或者多个随机变量(联合分布)在每一个可能取到的状态的可能性大小,概率分布的描述方式取决于随机变量是离散的,还是连续的。
离散型:概率质量函数PMF,也叫概率分布律。
概率质量函数直接把随机变量的每一个状态映射到该随机变量取该状态的可能性。
通常用大写字母P表示概率质量函数。
如,随机变量 x ~ P(x),表示随机变量x服从概率分布P(x),P(x = x1)表示随机变量x取值x1时候的概率大小,有时候简写成P(x1) 概率质量函数可以同时作用于多个随机变量,即联合概率分布。 P(x = x1,y = y1)表示x 取到x1,y取到y1同时发生的概率,也可简写成P(x1, y1)
概率质量函数满足条件:

连续型:连续型随机变量用概率密度函数来描述概率分布。
概率密度函数满足以下条件:

概率密度函数并没有对每一个状态给出概率,而是对一段状态,通过求积分的方法,给出对应的概率质量。

这里很重要的一点,在概率密度函数中,分号;表示以什么为参数。
三、边缘概率
求边缘分布:
已知一组随机变量的联合概率分布,求其中一个或几个变量的概率分布,即为求边缘概率分布。
对离散型随机变量,用求和法则:
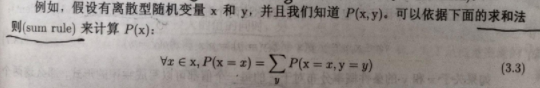
对连续型随机变量,用积分法则:

求联合分布:
一般求不出来,除非是像高斯分布这样的具有可加性的特殊分布,可以通过边缘求联合。
四、条件概率
已知一个事件发生了,这个时候再看另一个事件发生的概率。

联合概率除以边缘概率等于条件概率。
条件概率链式法则:
也就是乘法法则,任意个变量的联合概率分布,可以分解成一系列单变量的条件概率相乘的形式,链式法则从右往左看,两个一组逐渐生成联合分布。

独立性和条件独立性:

五、期望,方差,协方差
离散型和连续型随机变量的期望:
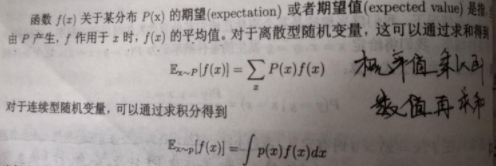
上图中是随机变量的函数的期望,如果要求随机变量本身的期望直接把f(x)换成x就行。
期望是衡量随机变量或随机变量的函数的平均值的量。
随机向量的期望即对随机向量中的每个随机变量分别求期望然后写到一个向量中。
期望的线性性质:
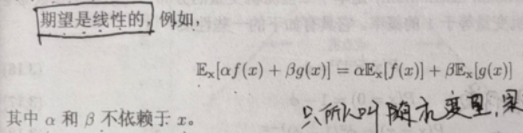
方差:
衡量单个随机变量变化程度的量。
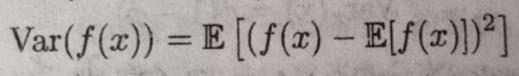
方差是随机变量与随机变量的均值的差的平方的期望。
协方差:
衡量两个随机变量之间的线性相关程度。
![]()
可以看到方差是协方差的一种特殊情况。
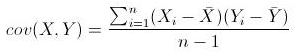
具体计算协方差采用上图公式,注意上边是用随机变量X和Y的n个样本来计算的两个随机变量的协方差,最后除以n-1是为了无偏估计。
协方差矩阵:
协方差是两个随机变量的性质,协方差矩阵是针对一个随机向量的。把一个随机向量中的随机变量两两组合计算协方差,最终得到的就是协方差矩阵,因此协方差矩阵是对称的。
六、常见概率分布
伯努利分布:
就是两点分布,离散型随机变量的分布,且这个离散型随机变量只有2种状态。

Multinoulli分布/范畴分布:
也是单个随机变量的分布,是伯努利分布的推广。
伯努利分布中只有两种状态,范畴分布可以有k个状态,代表k种类别。
范畴分布通常用于多分类任务中表示对象类别的分布,比如十分类模型的推理结果?
一般不计算服从范畴分布的随机变量的期望和方差。
高斯分布:不说了,懂得都懂。
指数分布:

Laplace分布:
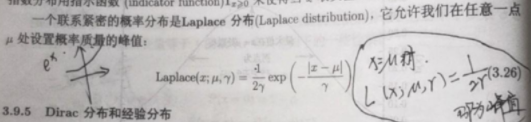
七、Dirac分布与经验分布
连续性随机变量与Dirac分布:
delta函数是利用积分定义的广义函数,其实就是信号与系统中的脉冲函数。

需要注意的是Dirac分布是用来定义概率密度函数的,不是用来定义概率质量函数的,也就是说是针对连续型随机变量才能用Dirac函数来作为其概率密度函数。
经验分布:

delta函数的一大作用就是用来定义连续性随机变量的经验分布。
经验分布用于连续型随机变量,如果有m个样本点,则在每个点所在的位置定义为1/m乘以delta函数,这样最后得到的经验分布概率密度的积分刚好是1.
如果是离散型随机变量,直接按样本出现的频率来定义样本点处的概率,也就是用范畴分布来定义就好了。
经验分布是训练数据集的似然最大的那个概率密度函数。
八、分布的混合

对于经验分布来举例,看作混合分布,则里边的范畴分布有m个状态,每个状态的概率都是1/m,每个从范畴分布中采样得到一个dirac分布,从这个分布产生一个样本点。比如在范畴分布中以1/m的概率采样得到了其中一个组件,δ(x-1),对应的x=1这个样本就是由密度函数为δ(x-1)的这个组件分布产生的。
经验分布的每个组件都是Dirac分布。经验分布就是一个混合分布。
其实分布的混合从另一个角度来说就是概率密度函数的加权组合。
潜变量模型:
混合模型中的组件标识变量就是潜变量的一个例子,潜变量是我们不能直接观察到的随机变量。其实我的理解就是潜变量其实取值就是混合模型的各个组件的加权系数。
矩阵各向同性:
就是一个标量乘以单位矩阵。
GMM高斯混合模型:
各个组件都是高斯分布。
GMM是概率密度的万能近似器,任何平滑的概率密度都可以用足够多组件的高斯混合模型以任意精度来逼近。
九、常用函数及其性质
1:sigmoid函数


2:softplus函数
其实relu的平滑版

3:sigmoid和softplus函数计算性质


十、贝叶斯规则
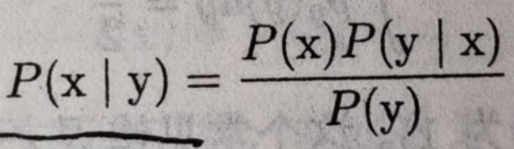
贝叶斯规则中y通常是样本,x是样本的类别,P(x)就是类别的先验,是统计概率(小鱼分割例子中,先验概率就是每个类别像素除以像素总数目,性别分类中,判断某一电子科大学生是男生,就是直接根据先验概率,男生类别的先验概率是4/5,女生类别的先验概率是1/5),P(y|x)是类条件概率密度(通常我们并不知道,需要假设),也就是某一个类别对应分布的概率密度。P(x|y)是后验分布,后验分布是条件概率。
用贝叶斯可以建模样本与其类别之间的关系。















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









