







1. 对Series进行排序
1.1 函数功能
按值对Series进行排序,返回结果:当inplace=False时为Series,当inplace=True时返回None
1.2 函数语法
Series.sort_values(*, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
1.3 函数参数
| 参数 | 含义 |
|---|---|
| axis | o或index,用于DataFrame的参数,对于Series不需要指定 |
| ascending | 布尔值,默认取值为True:升序 |
| inplace | 布尔值,默认取值为False:产生新的DataFrame |
| kind | 排序算法的选择,默认为:quicksort |
| na_position | 缺失值的位置,取值为last:放在最后(默认),取值为first,放在开头 |
| ignore_index | 布尔值,默认为False:不修改索引值 |
| key | 可选参数,可迭代对象,在排序前对Series运用key,比如:函数 |
1.3.1 默认参数排序
# 1. 获取Series,并排序,默认参数
sr = order['销售额'].copy()
print(sr.sort_values())
print(sr)
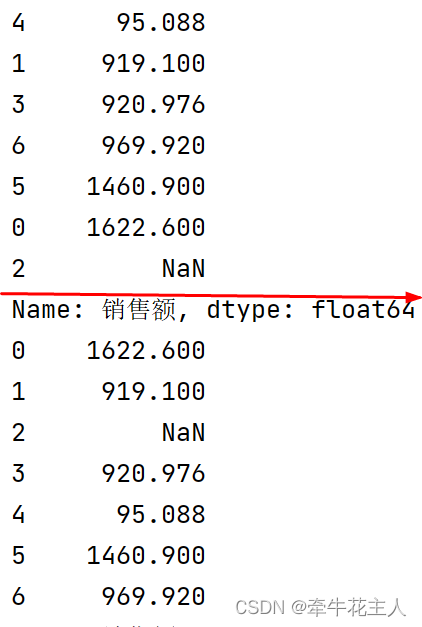
可以看到当Inplace=False时,原变量并没有发生变化
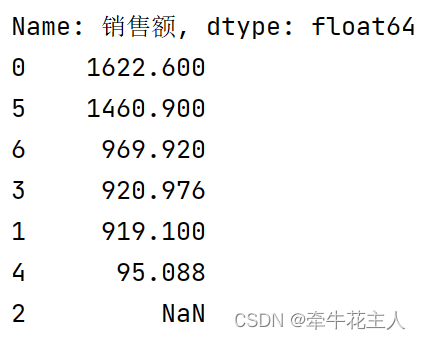
1.3.2 降序排列
# 2. 按照降序排列
print(sr.sort_values(ascending=False))
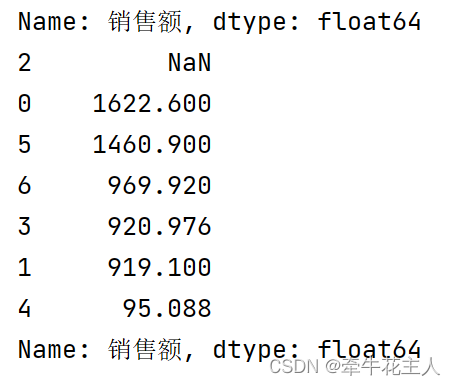
1.3.3 指定缺失值的位置
# 3. 将缺失值放在最前面
print(sr.sort_values(ascending=False,na_position='first'))
2. DataFrame排序
2.1 函数功能
依据某列对DataFrame进行排序
2.2 函数语法
DataFrame.sort_values(by, *, axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last', ignore_index=False, key=None)
2.3 函数参数
| 参数 | 含义 |
|---|---|
| by | 字符串或者字符串组成的列表,排序依据 |
| axis | o或index,1或columns用于DataFrame的参数,默认为0 |
| ascending | 布尔值或布尔值列表,默认取值为True:升序,当为布尔值列表时长度需要与by的长度相同 |
| inplace | 布尔值,默认取值为False:产生新的DataFrame |
| kind | 排序算法的选择,默认为:quicksort |
| na_position | 缺失值的位置,取值为last:放在最后(默认),取值为first,放在开头 |
| ignore_index | 布尔值,默认为False:不修改索引值 |
| key | 可选参数,可迭代对象,在排序前对Series运用key,比如:函数 |
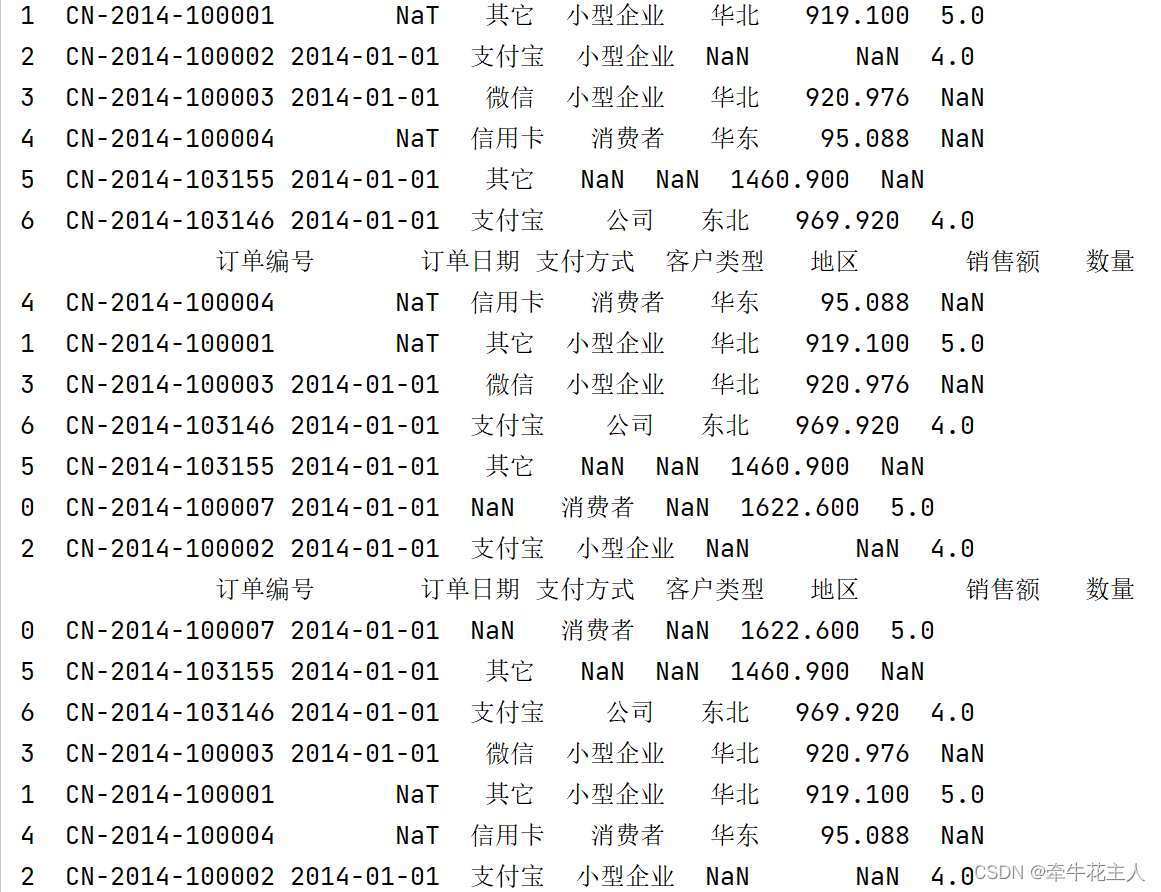
2.3.1 按单列排序
order = pd.read_excel('C:\\Users\\changyanhua\\Desktop\\order.xlsx')
print(order)
# 1. 按销售额升序排列
print(order.sort_values(by='销售额'))
# 2. 按销售额降序排列
print(order.sort_values(by='销售额',ascending=False))
3.3.2 排序依据为多列
# 1. 按销售额、日期升序排列
print(order.sort_values(by=['销售额','订单日期']))
# 2. 按销售额升序、生产日期降序排列
print(order.sort_values(by=['销售额','订单日期'],ascending=[True,False]))















 2642
2642











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









