






 本文介绍了卷积神经网络的基础知识,包括卷积层的原理、卷积核、填充和步幅,池化层的类型及其与平均池化和最大池化的区别,以及激活函数的作用。此外,还探讨了AlexNet、VGGNet和RESNet等经典CNN模型的特点。
本文介绍了卷积神经网络的基础知识,包括卷积层的原理、卷积核、填充和步幅,池化层的类型及其与平均池化和最大池化的区别,以及激活函数的作用。此外,还探讨了AlexNet、VGGNet和RESNet等经典CNN模型的特点。
目录
在深度学习如火如天的today,我也成功入坑,之前短短续续的看了好多有关深读学习有关的视频和书籍,为了方便学习,在此记录整理。本文介绍的为基础内容,若有错误还请多多指正。文章许多图片内容多源于CSDN的精华帖,除分享学习外,无任何其他目的,文章中引用的字段,文末都附有链接,并已经点赞原文章加收藏。
1.常见的神经网络模型
首先说一下当前比较常见流行的神经网络模型有哪些:
1.卷积神经网络(Convolutional Neural Networks,CNN):主要应用于图像和视频数据的处理和分析,具有自动提取特征和保留空间信息等优点。
2.图像神经网络(Graph Neural Networks,GNN):主要应用于图数据的处理和分析,能够自动提取节点和图之间的特征,具有广泛的应用前景。
3.递归神经网络(Recurrent Neural Networks,RNN):主要应用于序列数据的处理和分析,能够捕捉数据的时间信息和上下文关系,广泛应用于自然语言处理、语音识别等领域。
4.转换器(Transformer):一种基于注意力机制的模型,广泛应用于自然语言处理领域,取得了很好的效果。
5.长短时记忆网络(Long Short-Term Memory,LSTM):是一种特殊的递归神经网络,能够更好地处理序列数据中长距离依赖的问题,也广泛应用于自然语言处理、语音识别等领域。
这些网络结构估计大家在学的途中都不陌生,但可能只是听说过,具体如何实现大多未之能及。在文章基础网络结构介绍之后也会着重阐述卷积神经网络。当然,以上的网络模型只是比较常见的,其他模型等到需要的时候再学习。
2.卷积神经网络(CNN)的基本原理
CNN主要包括以下结构:
输入层(Input layer):输入数据;
卷积层(Convolution layer,CONV):使用卷积核进行特征提取和特征映射;
激活层:非线性映射(ReLU)
池化层(Pooling layer,POOL):进行下采样降维;
全连接层(Affine layer / Fully Connected layer,FC):在尾部进行拟合,减少特征信息的损失;
激活层:非线性映射(ReLU)
输出层(Output layer):输出结果。
2.1卷积层
2.1.1卷积的原理与计算
卷积是通过两个函数f和g生成第三个函数h的一种数学算子,可以理解为函数f与函数g经过翻转和平移的重叠部分的面积。

卷积是指在滑动中提取特征的过程,可以形象的理解为用放大镜把每部都放大并且拍下来,再把拍下来的图片拼接成一个新的大图片的过程。
计算机处理数据时用的都是离散的数据,所以把上面的公式离散化。

在计算机视觉中卷积有两个部分,一个是图像(蓝色部分)一个是卷积核(阴影部分)。卷积可以用于对输入数据(图像)进行特征提取,这个过程可以理解为通过卷积核对输入特征进行加权运算,提取输入中的重要信息。
卷积运算就是卷积核对图像做平移卷积计算输出新的图像的过程。如下图

相信看过吴恩达深度学习的小伙伴们看过举的边沿检测的实例,这里我们再举个实例方便理解。其实就是两矩阵做运算的结果作为新矩阵的元素。

2.1.2卷积核(Kernel)
卷积核就是图像处理时,给定输入图像,输入图像中一个小区域中像素加权平均后成为输出图像中的每个对应像素,其中权值由一个函数定义,这个函数称为卷积核。又称滤波器。
可以把卷积核理解为权重。每一个卷积核都可以当做一个“特征提取算子”,把一个算子在原图上不断滑动,得出的滤波结果就被叫做“特征图”(Feature Map),这些算子被称为“卷积核”(Convolution Kernel)。我们不必人工设计这些算子,而是使用随机初始化,来得到很多卷积核,然后通过反向传播优化这些卷积核,以期望得到更好的识别结果。

2.1.3 填充(Padding)
卷积的缺点:1.图像缩小(输出缩小)2.图像边缘信息发挥的作用小。为了解决这个问题在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),使用填充的目的是调整输出的尺寸,使输出维度和输入维度一致;

2.1.4 步幅(Stride)
卷积就相当于用核函数的小窗口,首先在输出数据上进行滑动计算,然后输出结果的过程。既然是移动的窗口,那么向右向下移动几步,仍然是一个可以选测的参数,这就是步幅。如上述图片的步幅就为2.
2.1.5 三维卷积
上述讨论都是基于灰度图像的前提下,也就是二维矩阵。当输入为多通道图像,输出多通道的卷积时如下图。假设图像为7x7x3,这里的3可以理解为RGB颜色通道。他的卷积过程是相应通道的卷积核与相应通道的输入矩阵进行卷积,然后结果相加。需要解释的是这里有两个3x3x3过滤器,右边上面的输出值是输入图像与第一个过滤器卷积的结果。下边是与第二个过滤器做卷积结果。这里不理解的可以看这里多通道卷积。

2.2池化层
在经过很多次卷积后,有时候会得到较大数量的特征图所以卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性。池化层实际上是一种降采样形式。 池化的作用:1,特性不变性 2.特征降维 3.在一定程度上防止过拟合。
常用的池化函数有:平均池化(Average Pooling / Mean Pooling)、最大池化(Max Pooling)、最小池化(Min Pooling)和随机池化(Stochastic Pooling)等,其中3种池化方式展示如下。

最大池化和平均池化的区别:
特征提取中误差主要来自两个方面:1)邻域大小受限造成的估计值方差增大;(2)卷积层参数误差造成估计均值的偏移。
pytorch实现
torch.nn.functional.avg_pool2d(input, kernel_size, stride=None,
padding=0, ceil_mode=False, count_include_pad=True)2.3激活层
卷积本质也是一种线性运算,如果只用卷积层,那么无非就是n 多个矩阵相乘罢了,将无法解决非线性问题,所以我们会加入激活函数,以提高模型的非线性表达能力。
2.3.1激活函数
激活函数可以将非线性特性引入到神经网络。如下图,输入通过加权,求和后还被作用一个函数f,这个函数就是激活函数,引入激活函数是为了增加神经网模型的非线性。

关于激活函数的详解,以及梯度消失和梯度爆炸问题可参考
2.常用的激活函数(Sigmoid、Tanh、ReLU等)
常用的激活函数
饱和激活函数:sigmoid、tanh。
非饱和激活函数:ReLU、PReLU、Leaky RELU、ELU等。
sigmoid的数学公式为 , 导数公式为
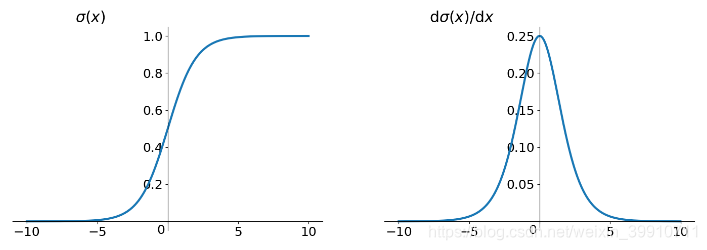
sigmoid
1.容易出现梯度消失
优化神经网络的方法是梯度回传:先计算输出层对应的 loss,然后将 loss 以导数的形式不断向上一层网络传递,修正相应的参数,达到降低loss的目的。 Sigmoid函数在深度网络中常常会导致导数逐渐变为0,使得参数无法被更新,神经网络无法被优化。
2.函数输出并不是零均值
零均值是不可取的,因为这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。 Sigmoid函数的输出值恒大于0,这会导致模型训练的收敛速度变慢。
3.幂运算相对来讲比较耗时
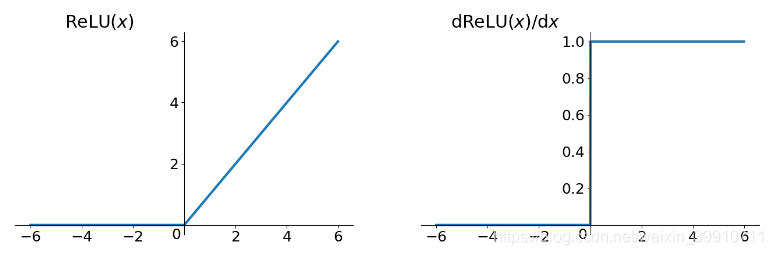
ReLU的优点:
1.解决了梯度消失问题 (在正区间),ReLU的非饱和性可以有效地解决梯度消失的问题, 提供相对宽的激活边界。
2.Sigmoid和Tanh激活函数均需要计算指数, 复杂度高, 而ReLU只需要一个阈值即可得到激活值。ReLU 函数中只存在线性关系,因此它的计算速度比 sigmoid 和 tanh 更快。计算速度非常快,只需要判断输入是否大于0。
3.ReLU使得一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的互相依存关系,缓解了过拟合问题的发生
缺点:
1.ReLU 函数的输出为 0 或正数,不是zero-centered
2.ReLU 函数的输出均值大于0,偏移现象和神经元死亡会共同影响网络的收敛性。
2.4全连接层
全连接层一般位于整个卷积神经网络的最后,负责将卷积输出的多维特征图转化成一维的一个向量,由此实现了端到端的学习过程(即:输入一张图像或一段语音,输出一个向量或信息)。全连接层的每一个结点都与上一层的所有结点相连因而称之为全连接层。由于其全相连的特性,一般全连接层的参数也是最多的。
全连接层的主要作用就是将前层(卷积、池化等层)计算得到的特征空间映射样本标记空间
如下图,假设得到了三张特征图,那么需要在进入全连接层时需要把这2x2x3的矩阵展开一个12x1的向量。
此时这12x1向量中的每一个元素就是输入层的神经元,然后用权重矩阵对其加权求和,就得到每个分类的得分,然后根据softmax函数进行概率计算。

全连接层中一层的一个神经元就可以看成一个多项式,我们用许多神经元去拟合数据分布,一般两层或以上的全连接层就可以很好地解决非线性问题了。我们都知道,全连接层之前的作用是提取特征,全理解层的作用是分类。
举一个例子我们去识别一张猫的图片,假设这个神经网络模型已经训练完了,全连接层已经知道。当我们得到下图左侧特征时,就可以判断是否是猫。红色的神经元表示这个特征被找到了(激活了),同一层的其他神经元,要么猫的特征不明显,要么没找到,当我们把这些找到的特征组合在一起,发现最符合要求的是猫。

总结:全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的分布式特征表示映射到样本标记空间的作用。
3.常见的卷积神经网络
3.1AlexNet
AlexNet经典网络是在2012年发表在NIPS上,论文名字为《ImageNet Classification with Deep Convolutional Neural Networks》。他也是(2012年ImageNet 大规模视觉识别挑战赛)赢得冠军的神经网络。
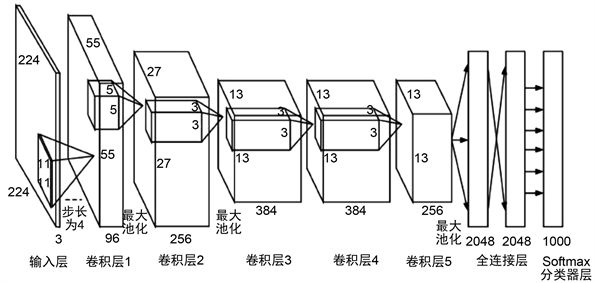
如下图所示,Alexnet共有8层结构,前5层为卷积层,后三层为全连接层

AlexNet网络结构具有如下特点:
1.AlexNet在激活函数上选取了非线性非饱和的relu函数,在训练阶段梯度衰减快慢方面,relu函数比传统神经网络所选取的非线性饱和函数(如sigmoid函数,tanh函数)要快许多
2.AlexNet在双gpu上运行,每个gpu负责一半网络的运算,
3. Dropout操作会将概率小于0.5的每个隐层神经元的输出设为0,即去掉了一些神经节点,达到防止过拟合。那些“失活的”神经元不再进行前向传播并且不参与反向传播。这个技术减少了复杂的神经元之间的相互影响。
4.池化方式采用overlapping pooling。即池化窗口的大小大于步长,使得每次池化都有重叠的部分。这种操作非常像卷积操作,可以使相邻像素间产生信息交互和保留必要的联系。此操作可以有效防止过拟合的发生。
上图包含了GPU通信的部分。这是由当时GPU内存的限制引起的,作者使用两块GPU进行计算,因此分为了上下两部分。但是,以目前GPU的处理能力,单GPU足够了,因此其结构图可以如下所示:
要点:
数据集:ImageNet 数据集,含 1500 多万个带标记的图像,超过 2.2 万个类别
激活函数:ReLU(训练速度快,一定程度上减小了梯度消失的问题)
数据增强:平移、镜像、缩放等
过拟合:dropout
如何训练:批处理梯度下降训练模型,注明了动量衰减值和权值衰减值
训练时间:使用两台 GTX 580 GPU,训练了 5 到 6 天
3.2VGGNet
AlexNet成功解决了传统神经网络最多只能训练两三层的问题,带来了是深度学习的革命。VGGNet 是牛津大学计算机视觉组和 Google DeepMind 公司的研究员一起研发的的深度卷积神经网络,同时也获得了2014年 ILSVRC比赛的冠军。
为了降低卷积层要训练参数的数量,VGGNet减小了卷积核。例如5x5的卷积核,可以用两个3x3的卷积核来代替,7x7的卷积核可以用3个3x3的卷积核来代替。同时为了降低训练时间,如下图所示,VGGNet发明了分级训练的方法。设计了A,A-LRN,B,C,D,E这6中网络。首先训练11层的A级网络,然后用训练好的参数去加速,13层,16最高达到19层。

比较常用的是VGGNet-16和VGGNet-19,VGGNet-16的网络结构如下图所示:

VGG-16:2个卷积层+Max Pooling+2个卷积层+Max Pooling+3个卷积层+Max Pooling+3个卷积层+Max Pooling+3个卷积层+Max Pooling+3个全连接层。
3.3RESNet
REsNet网络是2015年被提出的,并斩获当年imagenet竞赛中分类任务的第一名。 详细介绍可看这个视频精读AI论文】ResNet深度残差网络
在ResNet提出之前,神经网络都是通过卷积层和池化层的叠加组成的。人们认为卷积层和池化层的层数越多,获取到的图片特征信息越全,学习效果也就越好。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了,如下图所示。
出现这种情况原因:梯度消失和梯度爆炸,退化问题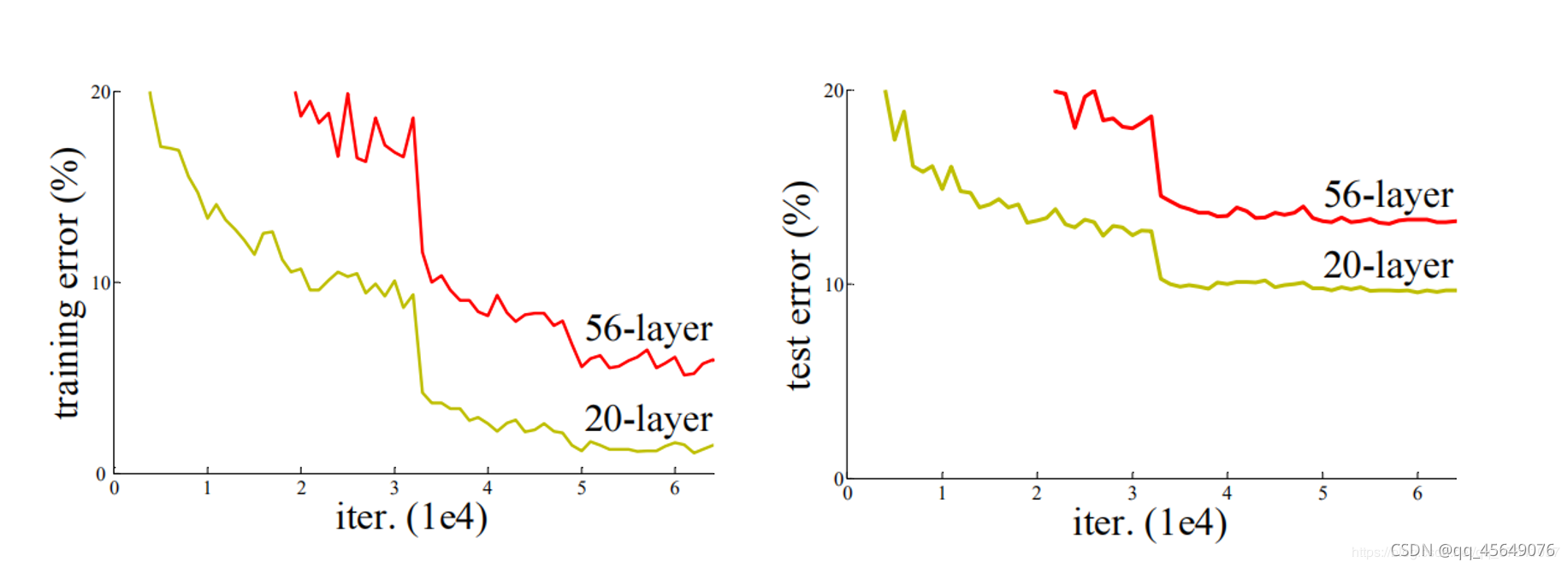
前面的实验结果现象,在不断加神经网络的深度时,模型准确率会先上升然后达到饱和,再持续增加深度时则会导致准确率下降,示意图如下:

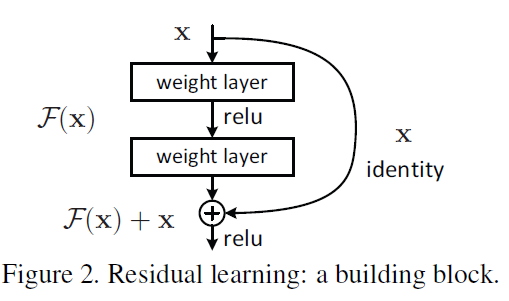
那么我们作这样一个假设:假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(Identity mapping,也即 y=x,输出等于输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,便是著名深度残差网络 ResNet 的灵感来源。
ResNet 引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到 1000 多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,很明显,该图是带有跳跃结构的:

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









